
火车头采集器
-
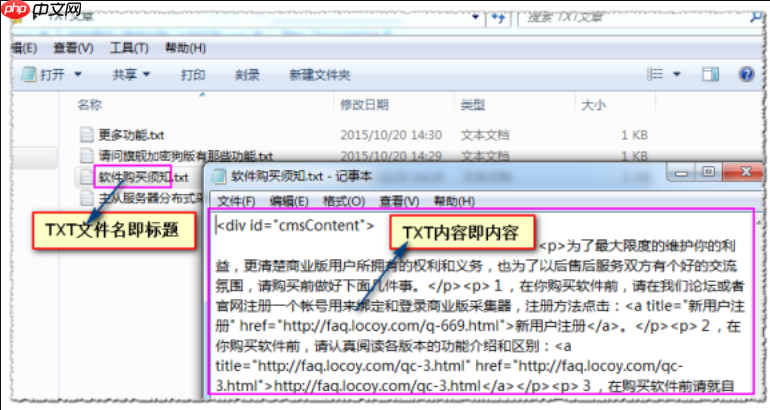
LocoySpider如何监控爬虫运行日志_LocoySpider日志监控的输出设置
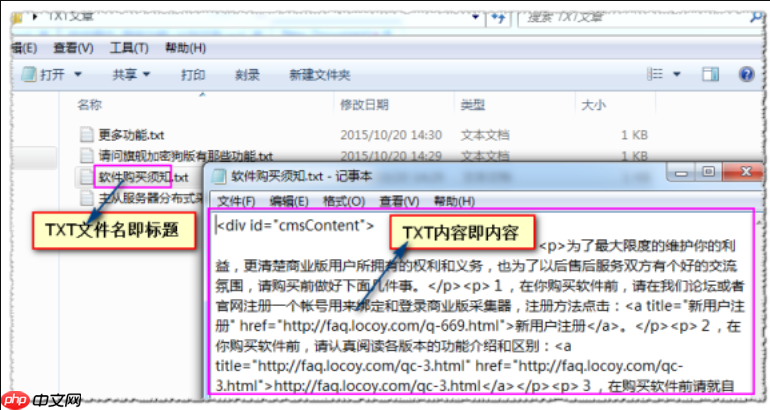



答案:需启用日志功能并配置级别、格式、查看与归档。具体为:开启运行日志记录,选择DEBUG或INFO级别,自定义含时间、任务名等字段的格式模板,实时查看日志流并搜索异常,设置按日分割与最大保留7天策略以自动清理。 如果您在使用LocoySpider进行数据采集时,需要实时掌握爬虫的运行状态和抓取细节…
-
火车头采集器如何备份还原采集项目_火车头采集器项目备份的恢复操作


答案:通过导出.ljx文件或复制project文件夹备份火车头采集项目,再通过导入项目或替换目录实现恢复。具体步骤包括使用软件内置的导出/导入功能、手动复制项目文件夹、注意版本兼容性与字符集设置,确保规则、Cookie等数据完整迁移。 如果您在使用火车头采集器时需要更换设备或重新安装软件,可能会遇到…
-
LocoySpider如何采集社交媒体数据_LocoySpider社交采集的API授权


首先通过官方API授权获取Access Token,并在LocoySpider中配置请求头和接口地址;其次对需登录的平台模拟登录并设置Cookie与User-Agent;最后合理设置请求间隔、代理IP池及重试机制以规避反爬。 如果您希望使用LocoySpider采集社交媒体上的公开数据,但遇到权限限…
-
火车头采集器如何使用正则表达式匹配_火车头采集器正则匹配的语法应用


掌握正则表达式基本语法并在火车头采集器中正确配置高级匹配模式,可精准提取不规则或动态网页内容。首先理解.、*、+、d、w、[]、()等符号作用,利用()分组提取目标文本;进入字段设置的高级模式,选择正则提取方式并输入包含捕获组的表达式;针对多行内容启用多行模式或使用[sS]匹配换行;处理特殊字符时需…
-
LocoySpider如何采集博客文章评论_LocoySpider博客采集的嵌套提取


首先配置文章链接提取,再通过嵌套规则采集评论;针对动态加载需捕获XHR请求并模拟,最后测试验证并导出数据。 如果您希望使用LocoySpider采集博客文章下的评论内容,但发现评论数据无法正常提取,可能是由于评论区域采用了动态加载或嵌套结构。以下是实现博客评论嵌套采集的具体操作步骤: 一、配置主页面…
-
火车头采集器如何运行在虚拟机环境中_火车头采集器虚拟机的资源分配

首先确保虚拟机分配至少2个CPU核心和4GB内存,建议升级至8GB;开启硬件虚拟化支持并确认BIOS设置正确;采用桥接网络模式保证网络稳定,必要时使用NAT加代理;安装.NET Framework 4.0及以上和Visual C++运行库;使用预分配固定大小磁盘并存储于SSD以提升I/O性能。 如果…
-
LocoySpider如何集成OCR文字识别_LocoySpiderOCR集成的图像处理

可通过集成OCR技术解决LocoySpider无法抓取图片文字的问题。一、使用Tesseract OCR引擎进行本地识别:1、安装Tesseract-OCR并配置环境变量;2、在LocoySpider中设置图片下载规则,保存目标图像至本地;3、通过批处理或Python脚本调用Tesseract命令识…
-
LocoySpider如何调试CSS选择器_LocoySpiderCSS调试的元素定位


首先使用%ignore_a_1%开发者工具验证CSS选择器,通过检查元素结构并用document.querySelector测试匹配;接着逐步简化或扩展选择器以提升准确性;利用LocoySpider的预览功能实时测试提取效果;针对动态内容启用模拟浏览器渲染或改采API接口;最后结合属性选择器与伪类精…
-
LocoySpider如何采集论坛帖子回复_LocoySpider论坛采集的线程跟踪


需配置多级规则抓取论坛主帖与回复,启用浏览器模拟加载JS内容,设置合理线程与间隔防封,并清洗无效数据以获取完整互动信息。 如果您需要从论坛中获取完整的讨论内容,但发现仅采集主帖无法获得用户间的互动信息,则可能是由于回复内容由JavaScript动态加载或分页机制导致。以下是使用火车头采集器(Loco…
-
LocoySpider如何采集天气预报信息_LocoySpider天气采集的API调用


首先需定位天气网站的API接口,通过浏览器开发者工具分析XHR请求并获取返回JSON数据的URL;接着在LocoySpider中配置高级采集模式,填入API地址、请求头及参数;然后使用JSON解析器提取字段并生成路径表达式;最后通过列表循环替换城市变量实现批量采集,设置合理请求间隔避免被封。 如果您…
