
langchain
-
大型模型开发工具集已经建立!
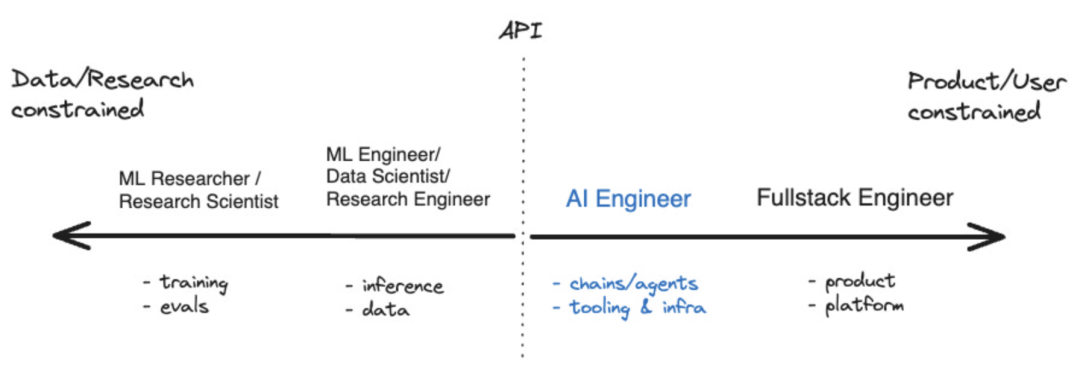
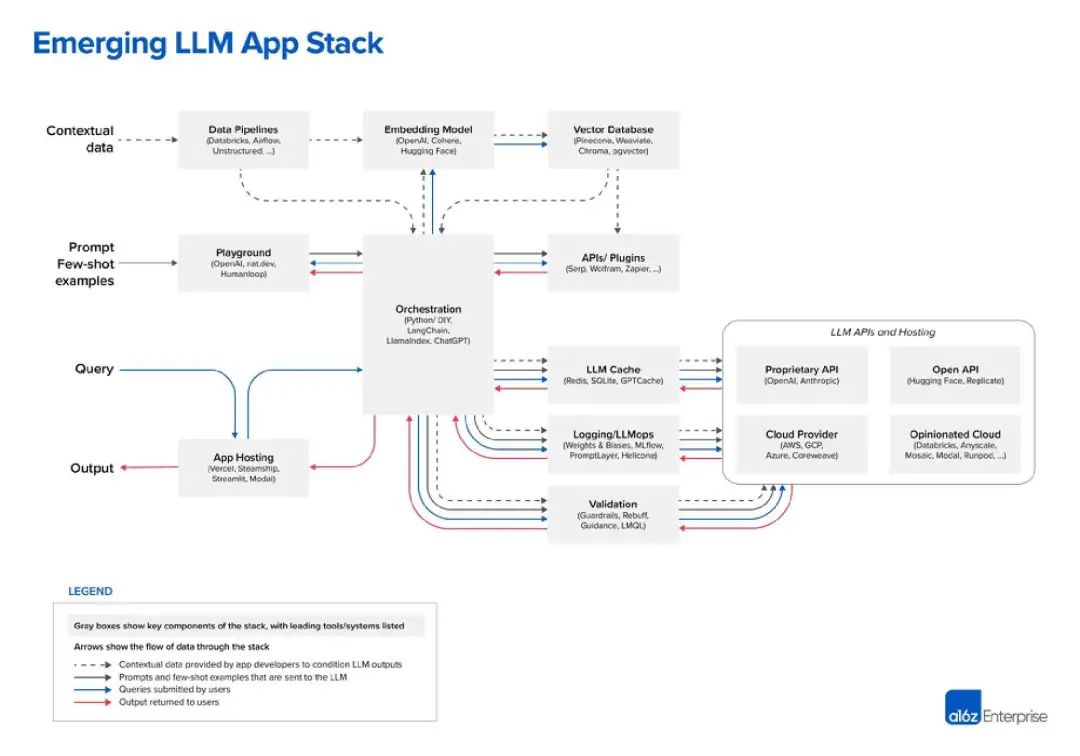


需要进行改写的内容是:作者 richard macmanus 策划 | 言征 Web3未能颠覆掉Web2,但新兴的大模型开发栈正在让开发者从“云原生”时代迈向新的AI技术栈。 提示工程师或许不能触动开发者奔赴大模型的神经,但产品经理或者领导的一句:能不能开发一个“agent”,能不能实现一条“cha…
-
谷歌云数据库增加更多人工智能功能


谷歌云正在加强其分析和事务数据库,包括bigquery, alloydb和spanner,旨在推动其客户生成人工智能应用程序的开发。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ BigQuery是谷歌云的高级数据库服务,专为支持分析和人工…
-
Luma、Runway轮番炸场,视频生成卷出新高度,Sora还能称霸吗?来这场WAIC视频生成论坛寻找答案


☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 2023 年 pika 发布时,马斯克曾论断称 2024 年将是「人工智能电影」元年。 年初 Sora 惊艳亮相、大杀四方,接着 Stable Video Diffusion 、LTX Stud…
-
技术反思:LLM时代,MCP是必需品还是过渡方案?
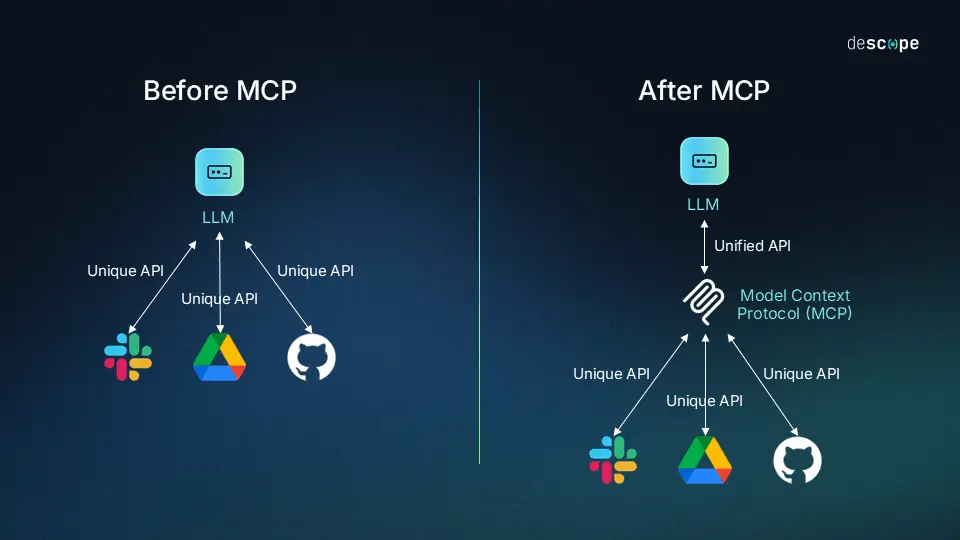
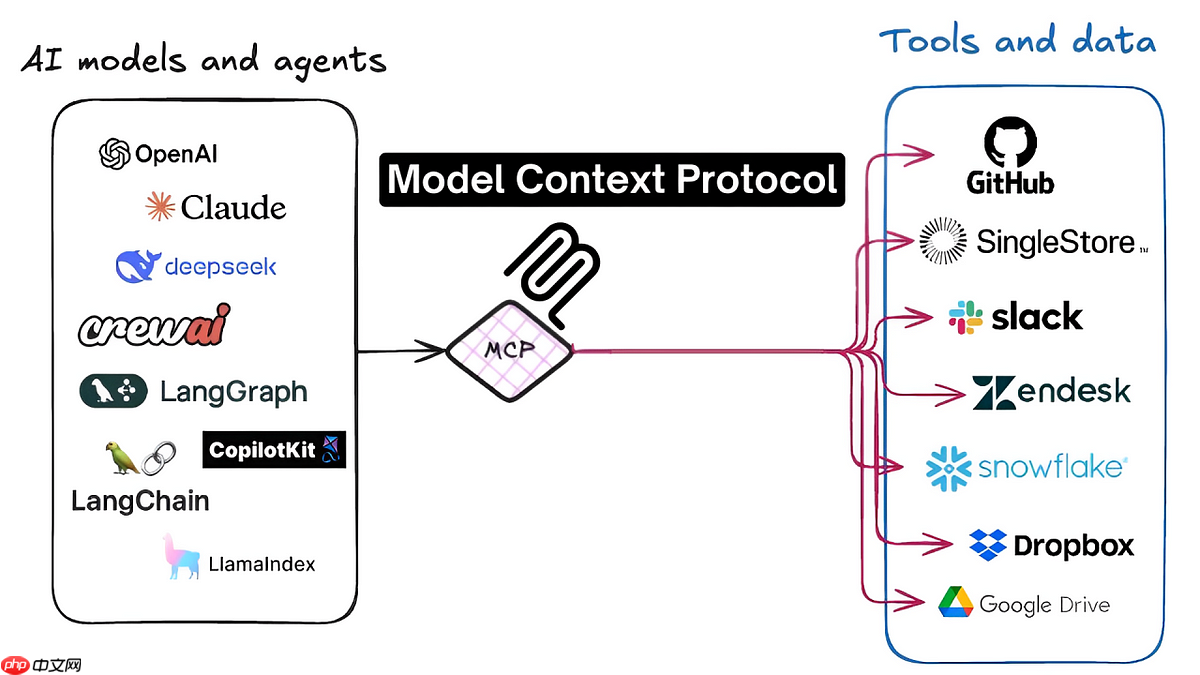
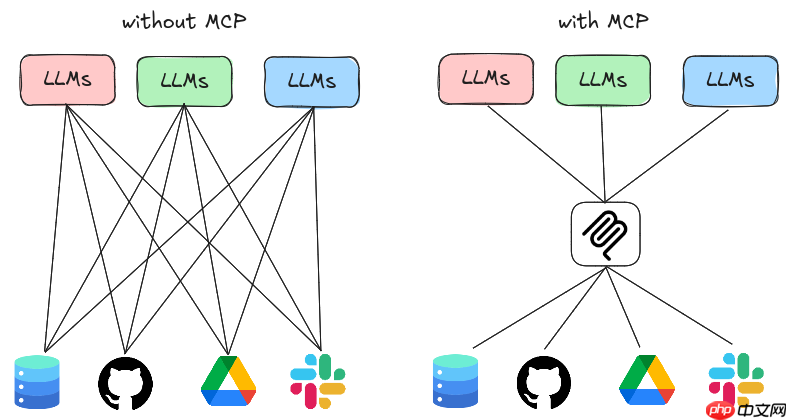
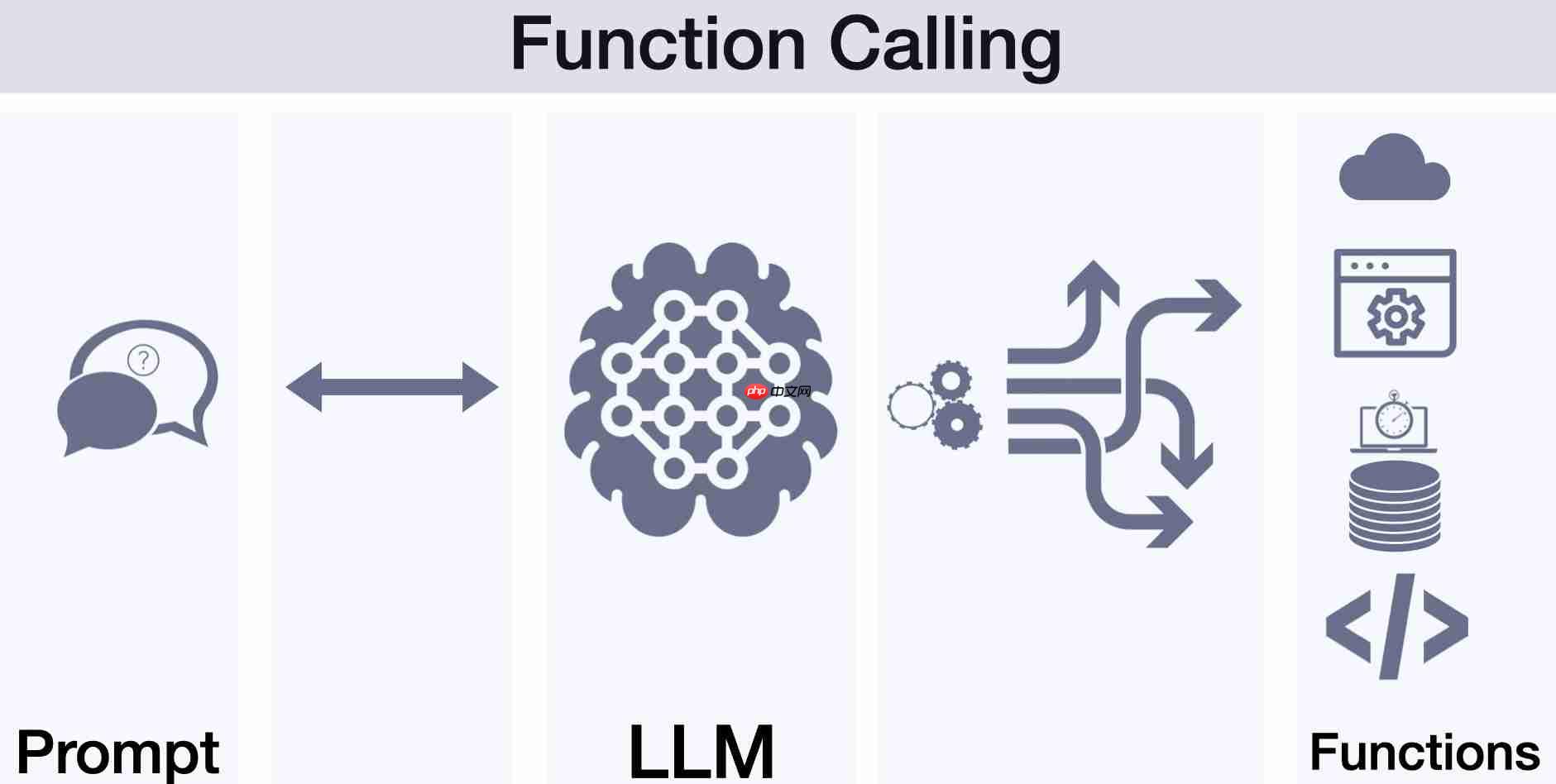
前言 近期mcp的火爆是大家有目共睹的,关注人工智能前沿开发的开发者或多或少都有阅读过mcp相关文章或者视频,也不乏有像本人一样动手亲自来实践,开发本地mcp服务或者实现一系列相关llm+mcp应用(如本人曾实践过llm+mcp论文查找服务)。随着实操体验热度过去之后,结合本人人工智能应用开发与落地…
-
解锁GPT-4和Claude2.1:一句话带你实现100k+上下文大模型的真实力,将27分提升至98
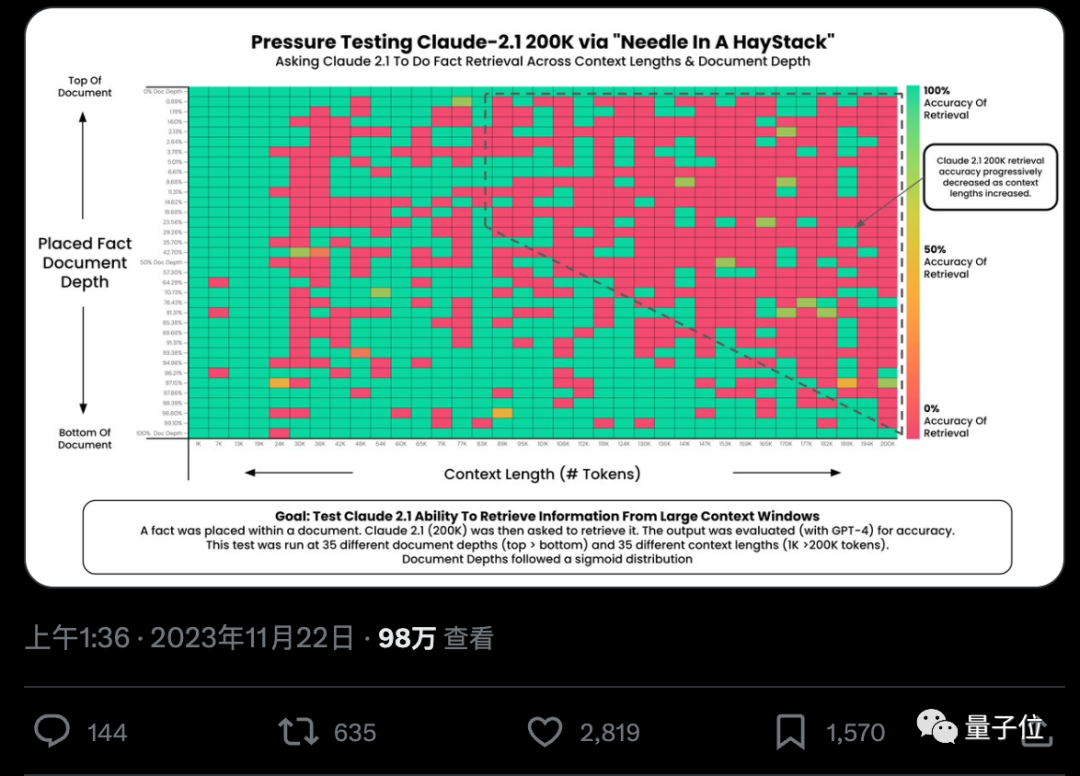
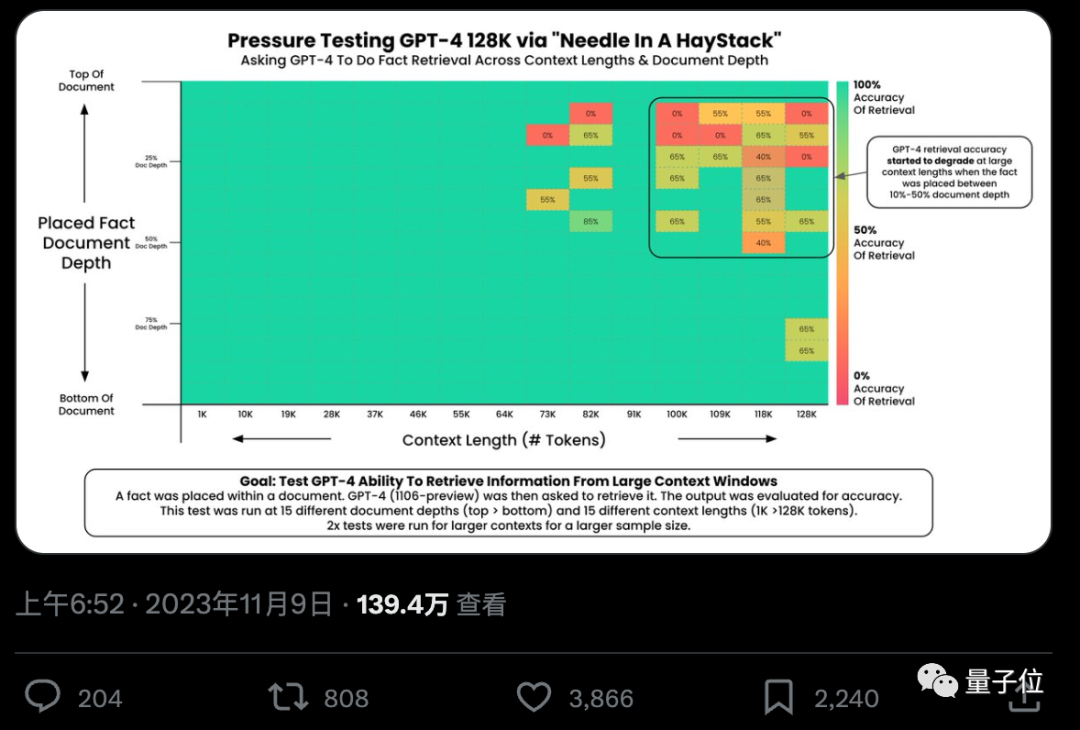
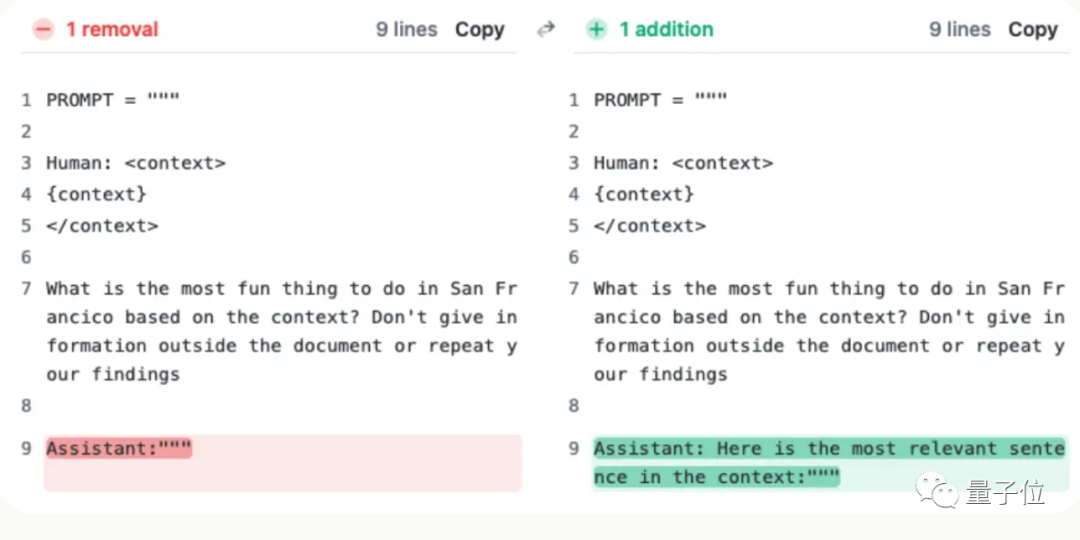
各家大模型纷纷卷起上下文窗口,llama-1时标配还是2k,现在不超过100k的已经不好意思出门了。 然鹅一项极限测试却发现,大部分人用法都不对,没发挥出AI应有的实力。 AI真的能从几十万字中准确找到关键事实吗?颜色越红代表AI犯的错越多。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免…
-
浅析 LLM 可观测性



大家好,我是luga。今天我们继续探讨人工智能生态领域中与技术相关的主题——llm(大型语言模型)的可观测性。本文将继续深入分析llm的可观测性,以帮助大家了解其重要性和核心的生态体系知识。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 一…
-
清华微软开源全新提示词压缩工具,长度骤降80%!GitHub怒砍3.1K星

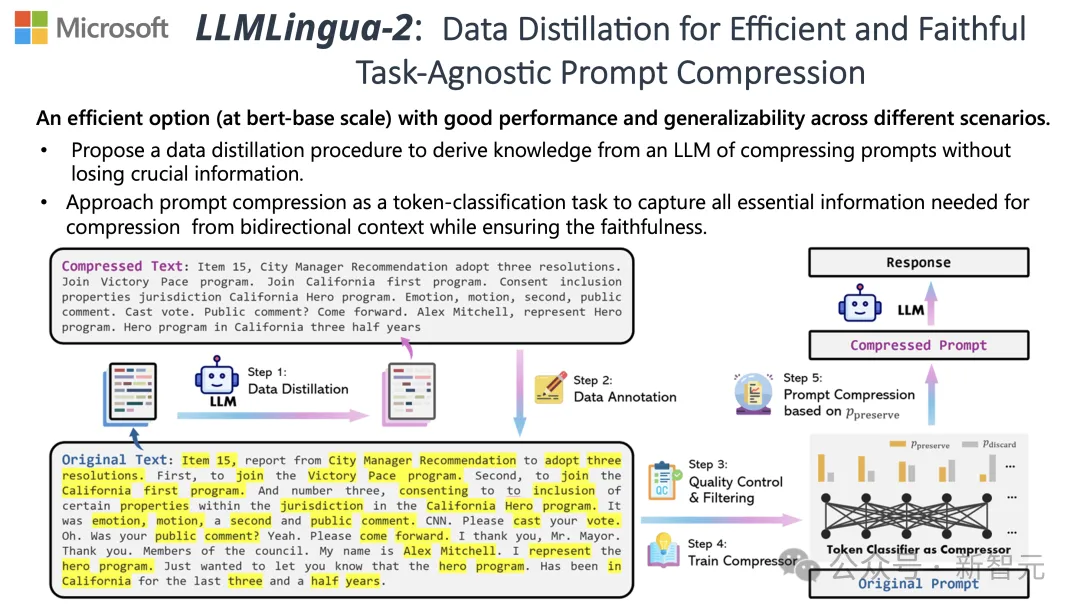

在自然语言处理中,有很多信息其实是重复的。 如果能将提示词进行有效地压缩,某种程度上也相当于扩大了模型支持上下文的长度。 现有的信息熵方法是通过删除某些词或短语来减少这种冗余。 然而,基于信息熵的计算仅涵盖了文本的单向上下文,可能会忽略压缩所需的关键信息;而且,信息熵的计算方式并非完全符合压缩提示词…
-
本地运行性能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服务,太方便了!
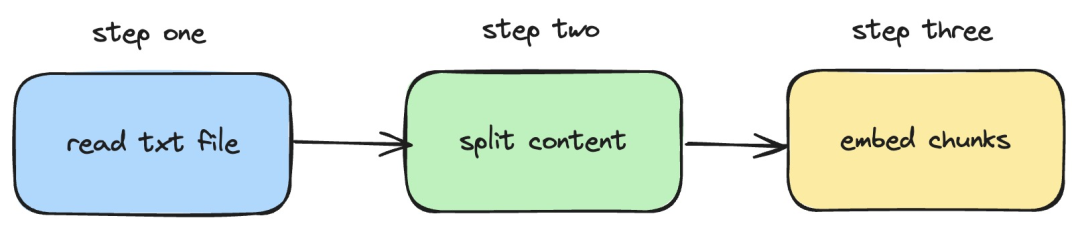

ollama 是一款超级实用的工具,让你能够在本地轻松运行 llama 2、mistral、gemma 等开源模型。本文我将介绍如何使用 ollama 实现对文本的向量化处理。如果你本地还没有安装 ollama,可以阅读这篇文章。 本文我们将使用 nomic-embed-text[2] 模型。它是一…
-
Gemini如何配置自定义知识库 Gemini私有数据接入教程



gemini本身不支持直接配置自定义知识库或接入私有数据,但可通过特定方法实现。1. 确认平台是否支持自定义知识库,如vertex ai、langchain等平台可能提供相关功能;2. 使用rag方式将私有数据向量化并存入数据库,在提问时检索相关内容拼接到提示词中发给gemini;3. 通过调整参数…
-
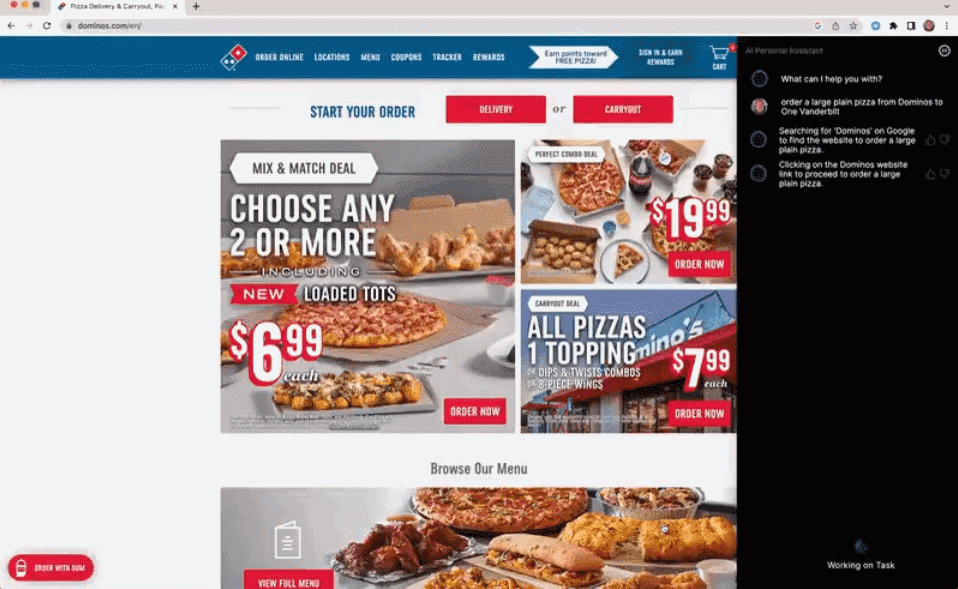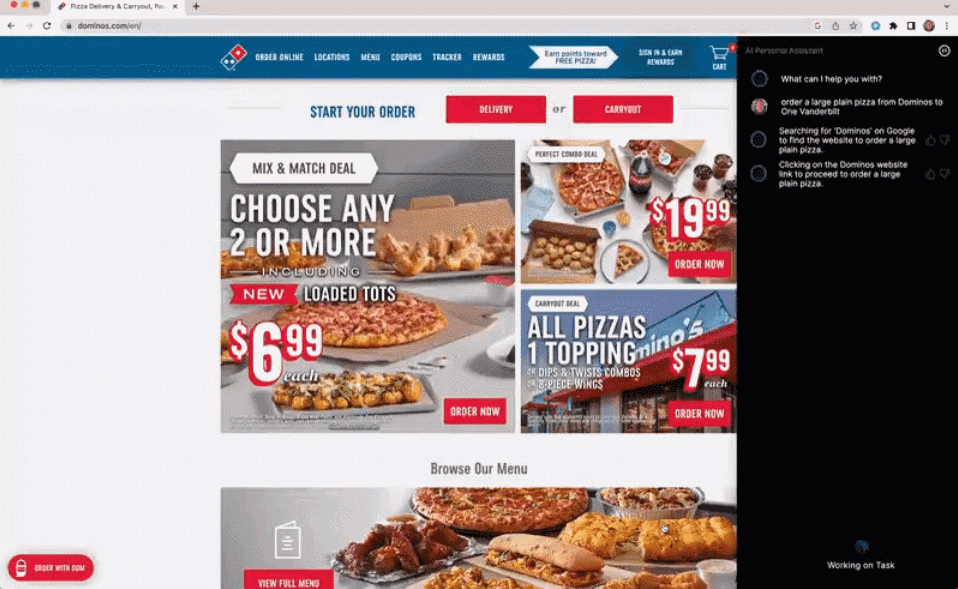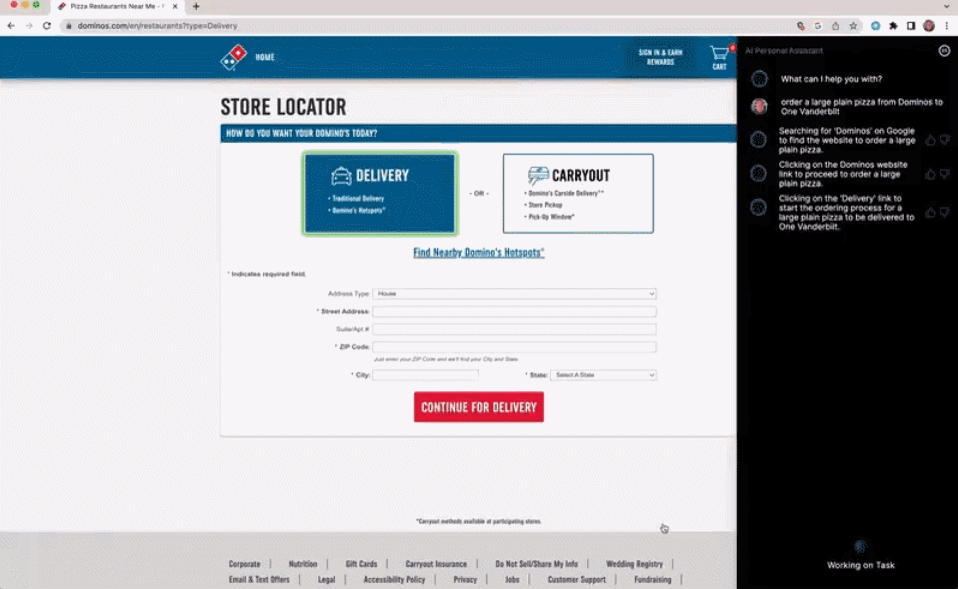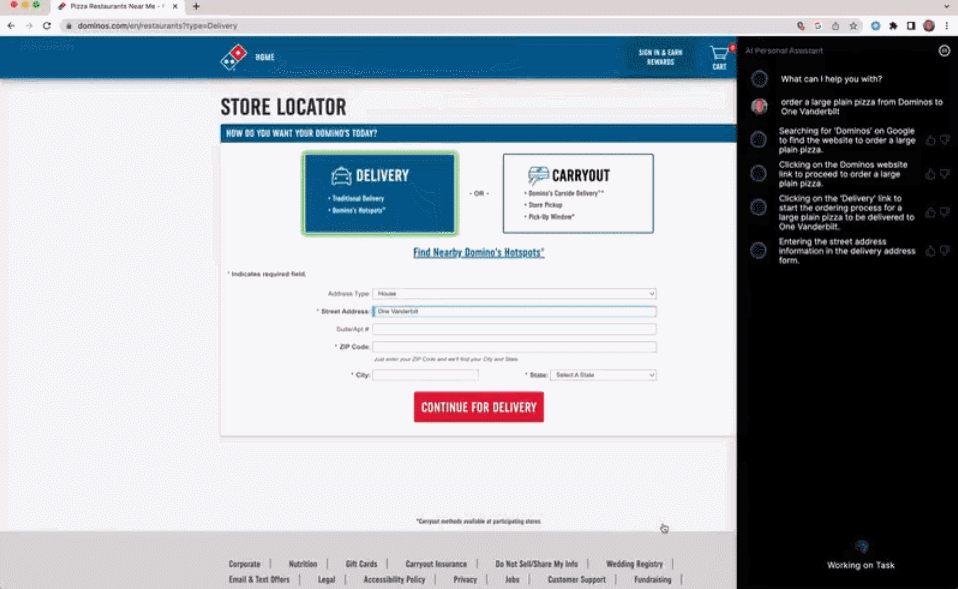
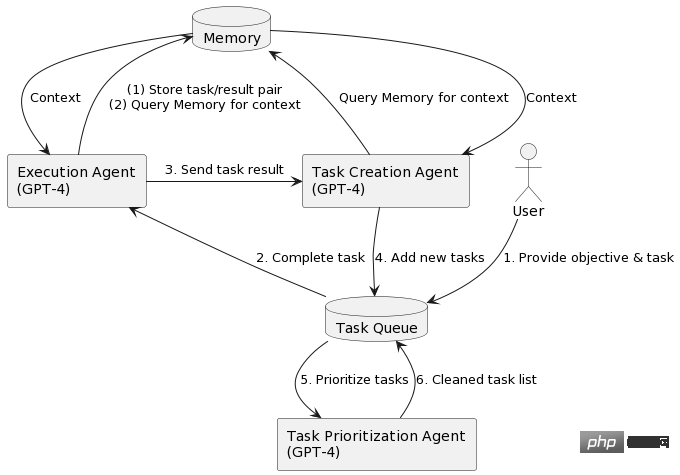
AutoGPT star量破10万,这是首篇系统介绍自主智能体的文章
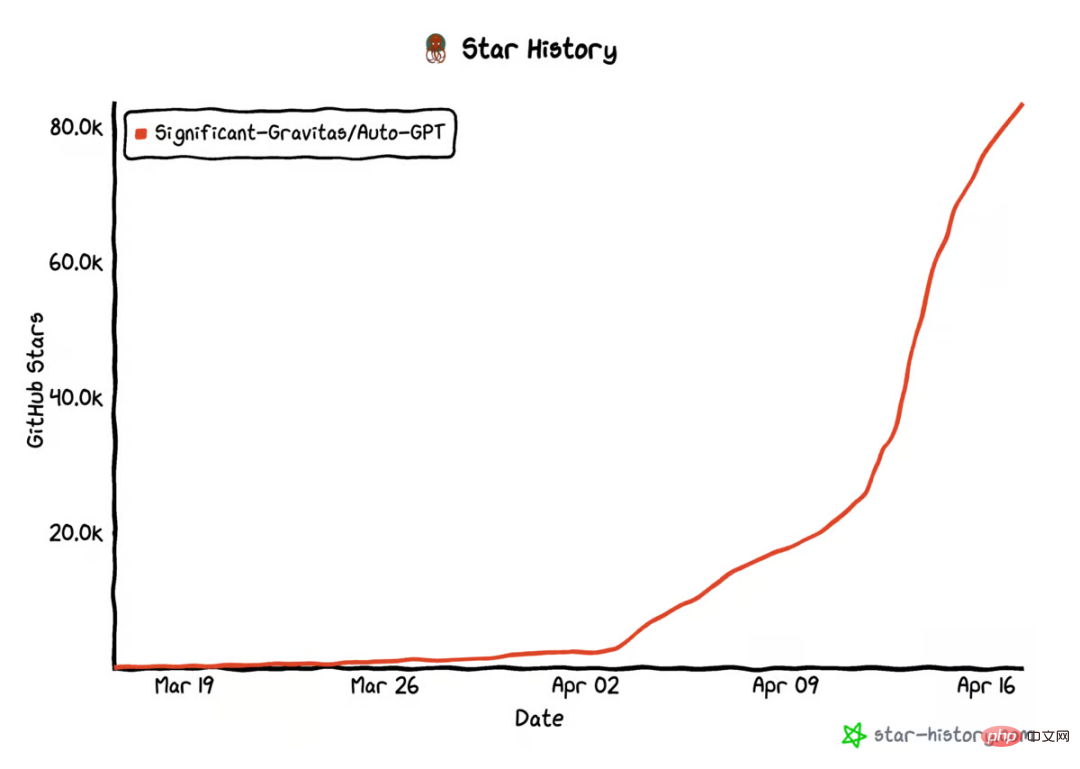

在 github 上,autogpt 的 star 量已经破 10 万。这是一种新型人机交互方式:你不用告诉 ai 先做什么,再做什么,而是给它制定一个目标就好,哪怕像「创造世界上最好的冰淇淋」这样简单。类似的项目还有 babyagi 等等。这股自主智能体浪潮意味着什么?它们是怎么运行的?它们在未来…
