
locoyspider
-
LocoySpider如何采集视频链接下载_LocoySpider视频采集的URL解析




首先检查视频链接是否通过正则或XPath准确提取,再根据网站类型选择静态解析、动态加载模拟、插件辅助或手动构造路径的方式获取真实URL,最终配置下载规则实现采集。 如果您在使用LocoySpider进行视频链接采集时遇到URL无法正确解析或下载的问题,可能是由于视频地址未经过有效提取或正则表达式配置…
-
LocoySpider如何优化网络带宽使用_LocoySpider带宽优化的限速配置

答案:可通过限制线程数、设置请求间隔、启用带宽限速插件及分时段调度来优化LocoySpider的带宽使用。具体包括:在“选项”中将最大采集线程数设为5-10;在任务参数中配置300-1000毫秒请求间隔并启用随机波动;安装并启用BandwidthLimiter插件,设置下行限速如800KB/s;通过…
-
LocoySpider如何处理表单提交模拟_LocoySpider表单模拟的POST请求

首先配置表单采集模式并设置字段值,接着通过自定义HTTP头和POST数据模拟请求,同时启用Cookie管理维持会话,并结合正则提取动态隐藏字段以确保提交合法性。 如果您需要使用LocoySpider抓取那些需要提交表单才能获取数据的网页内容,通常会遇到必须模拟POST请求的情况。这类页面往往依赖用户…
-
LocoySpider如何集成Python脚本扩展_LocoySpider脚本扩展的自定义函数

首先配置Python环境,确保安装Python 3.8+并添加至PATH;接着编写接收标准输入、处理数据并输出结果的独立.py脚本;然后在LocoySpider自定义函数中通过外部程序调用Python解释器执行该脚本;最后通过编码声明、异常捕获和日志查看完成调试。 如果您在使用LocoySpider…
-
LocoySpider如何集成自然语言处理_LocoySpiderNLP集成的文本分析


可通过集成NLP技术实现LocoySpider采集内容的智能语义识别与分类。一、调用外部API如百度AI、阿里云NLP等,通过HTTP请求发送采集文本,解析返回的JSON获取情感分析、关键词、实体等结果,并写入数据库,同时设置频率限制与重试机制防封禁。二、部署本地NLP模型,选用Jieba、HanL…
-
LocoySpider如何设置多任务并发_LocoySpider并发任务的队列管理
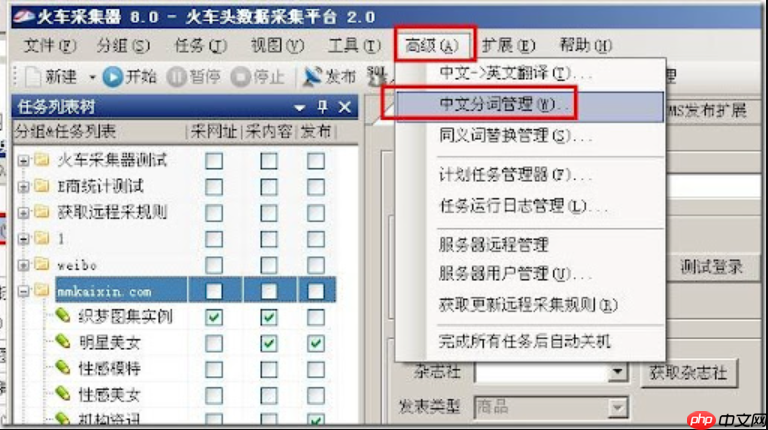

启用多任务并发需在系统设置中选择并发模式并设最大任务数,配置任务优先级确保关键任务优先执行,通过分组管理分类任务并限制各组并发量,调整每任务线程数优化性能,实时监控资源使用情况并动态调整运行状态以提升LocoySpider采集效率。 如果您在使用LocoySpider进行数据采集时希望提升效率,通过…
-
LocoySpider如何采集多页列表数据_LocoySpider分页采集的循环规则


首先确保分页规则正确,根据网站结构选择文本循环、URL参数递增或XPath提取下一页链接方式,配置循环逻辑并关联解析节点,实现多页数据完整抓取。 如果您在使用LocoySpider进行数据采集时遇到多页列表无法完整抓取的问题,通常是因为分页规则设置不正确或循环逻辑未匹配目标网站的翻页结构。以下是实现…
-
LocoySpider如何设置数据清洗规则_LocoySpider清洗规则的正则替换
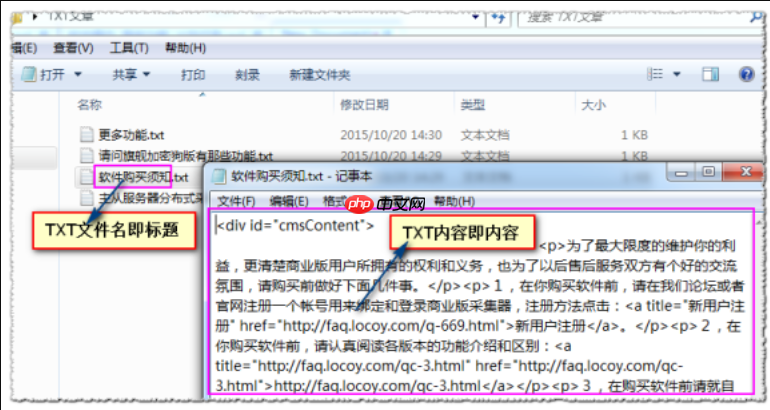

答案:通过设置清洗规则优化LocoySpider采集数据。首先进入字段清洗界面,点击“清洗”按钮添加规则;接着使用正则替换删除冗余字符,如用s+匹配空白并留空替换实现去空格;也可选择内置模板快速去除HTML标签或换行符;最后支持多规则顺序执行,按需调整优先级确保清洗逻辑正确,保存后运行任务验证效果。…
-
LocoySpider如何调试爬虫脚本错误_LocoySpider脚本调试的排查方法
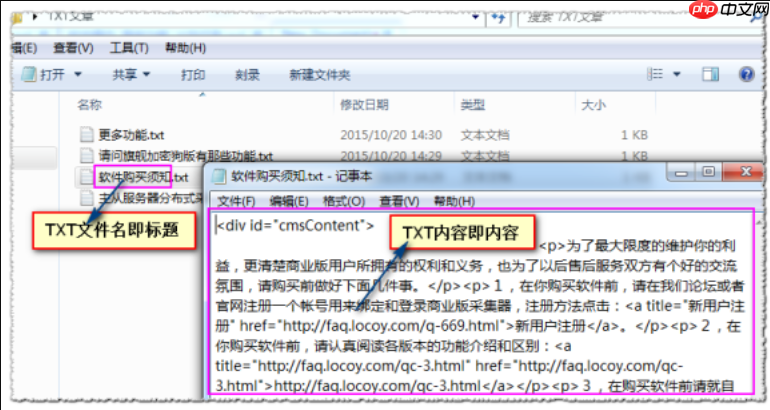

首先检查网页加载与元素定位是否准确,确认选择器有效且页面完全加载;接着验证脚本语法与变量定义,确保无拼写错误并正确声明变量;然后测试分页规则,保证翻页链接可提取并支持JavaScript翻页;再分析网络请求状态,核对请求头信息并应对反爬机制;最后启用调试模式逐步执行,观察数据提取结果与逻辑分支执行情…
-
LocoySpider如何采集地图位置数据_LocoySpider地图采集的坐标提取


首先确认地图数据来源,检查网络请求中包含经纬度的接口,识别坐标字段;再通过正则表达式提取嵌入HTML的坐标值,确保匹配lat/lng等关键词;若数据由JavaScript动态生成,则启用智能模式或浏览器内核模拟加载,结合XPath定位脚本内容并解析坐标;最后对于仅有地址无坐标的场景,调用高德或百度地…
