
qwen
-
MonkeyCode— 开源的企业级本地AI编程助手



☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 豆包AI编程 豆包推出的AI编程助手 483 查看详情 MonkeyCode是什么 monkeycode 是一款开源的企业级 ai 编程助手,支持私有化部署与离线运行,全面保障代码隐私与数据安全…
-
北电数智 WAIC 首秀,展示星火·大平台落百业成果




7月26日,2025世界人工智能大会暨人工智能全球治理高级别会议(waic)在上海盛大启幕。 这场以“智能时代 同球共济”为主题的人工智能顶尖盛会,汇聚了来自30余个国家和地区的1200余位科技企业代表、专家学者和行业精英,共同见证 AI 技术前沿突破、产业浪潮动向与全球治理新实践,勾勒智能新未来。…
-
使用工具包可将大型模型推理性能提升40倍
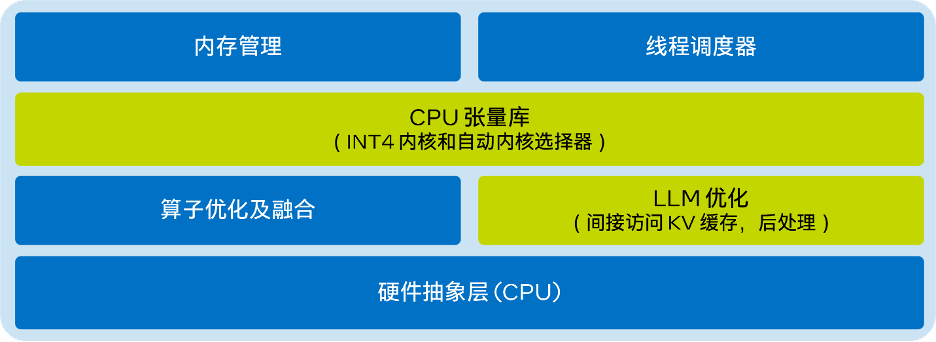
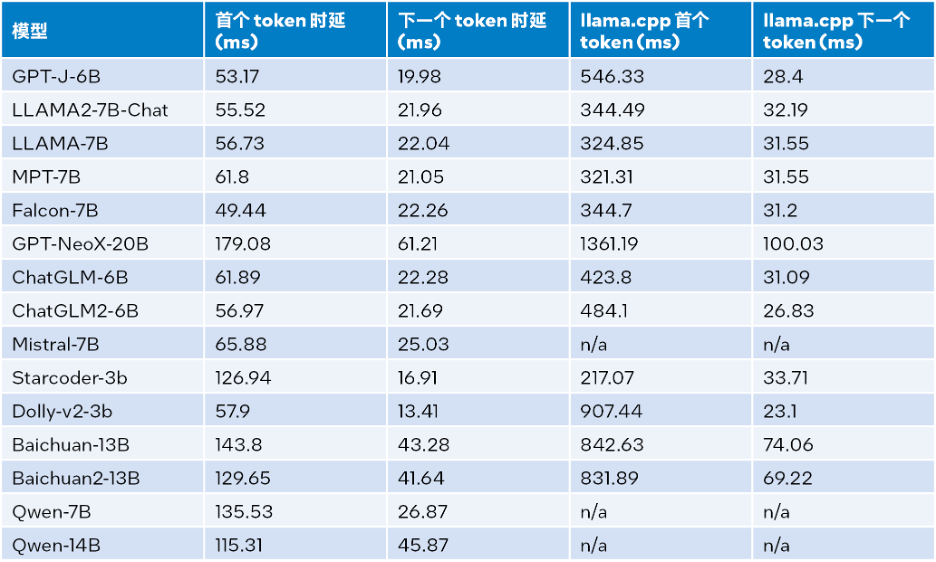

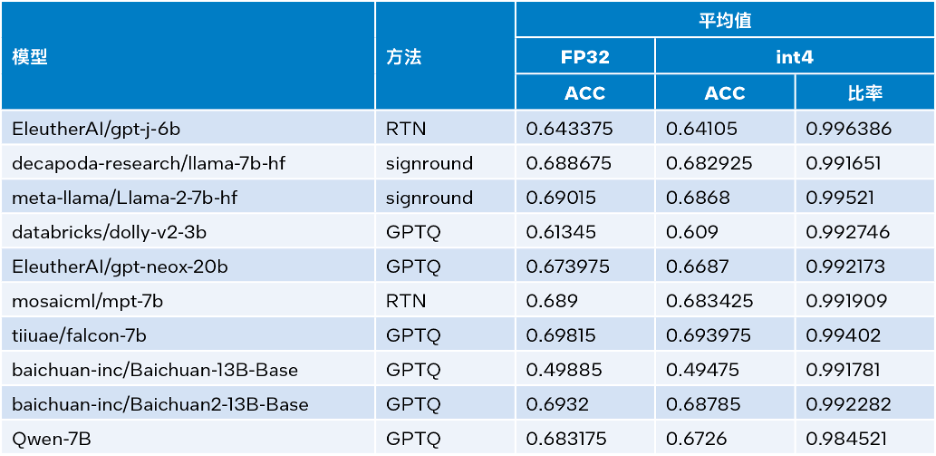
英特尔® Extension for Transformer是什么? 英特尔® Extension for Transformers[1]是英特尔推出的一个创新工具包,可基于英特尔® 架构平台,尤其是第四代英特尔® 至强® 可扩展处理器(代号Sapphire Rapids[2],SPR)显著加速基于…
-
位置编码在Transformer中的应用:探究长度外推的无限可能性
在自然语言处理领域,Transformer 模型因其卓越的序列建模性能而备受关注。然而,由于其训练时限制了上下文长度,使得它及其基于此的大语言模型都无法有效地处理超过此长度限制的序列,这被称作“有效长度外推”能力的缺失。这导致大型语言模型在处理长文本时表现较差,甚至会出现无法处理的情况。为了解决这个…
-
最新推出的适合中文LMM体质的基准CMMMU:包含超过30个细分学科和12K个专家级题目

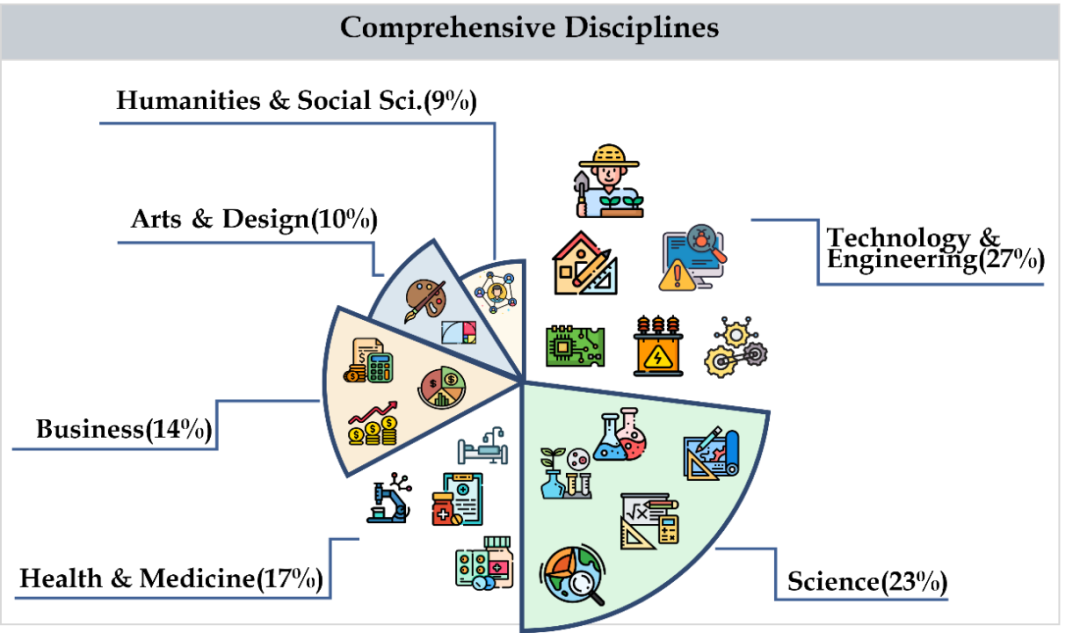
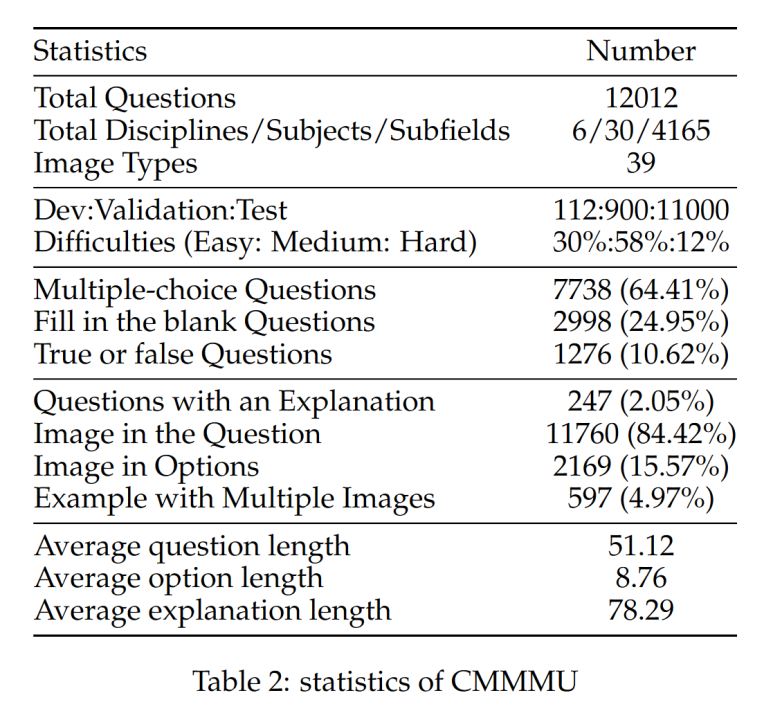
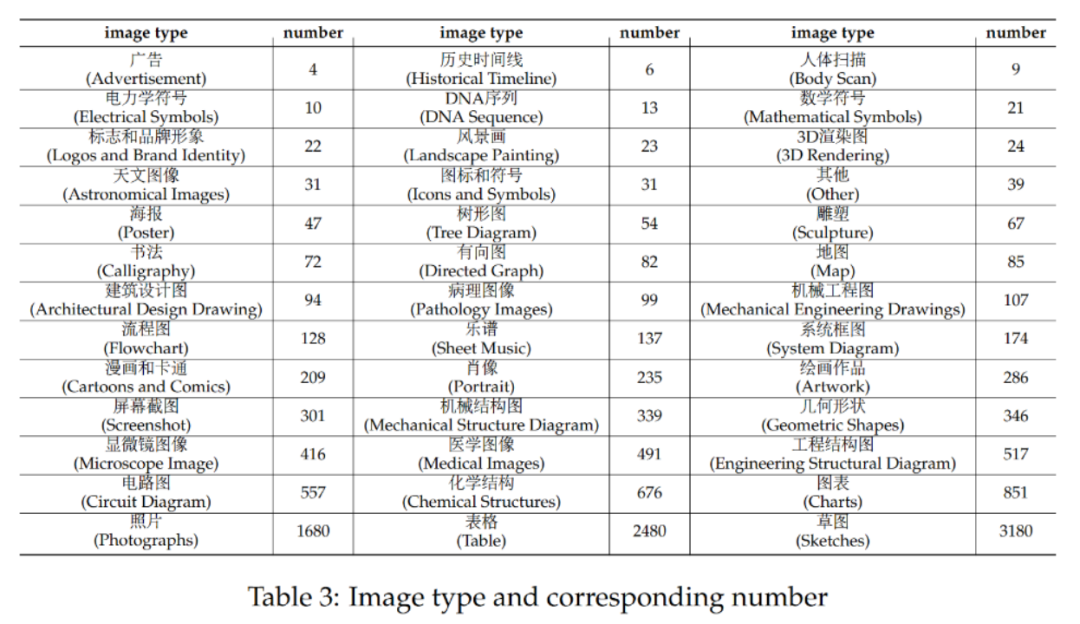
随着多模态大模型(LMM)的不断进步,对于评估LMM性能的需求也在增长。尤其在中文环境下,评估LMM的高级知识和推理能力变得更加重要。 在这个背景下,为了评估基本模型在中文各种任务中的专家级多模态理解能力,M-A-P 开源社区、港科大、滑铁卢大学和零一万物共同推出了 CMMMU(Chinese Ma…
-
将多模态大模型稀疏化,3B模型MoE-LLaVA媲美LLaVA-1.5-7B

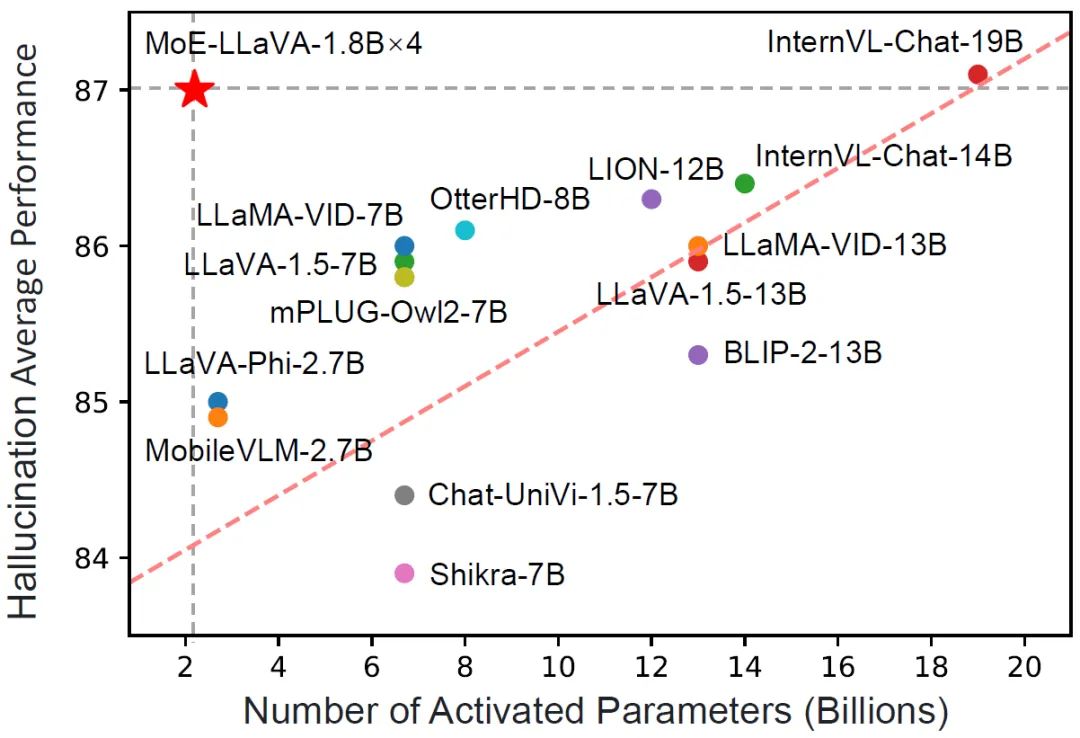
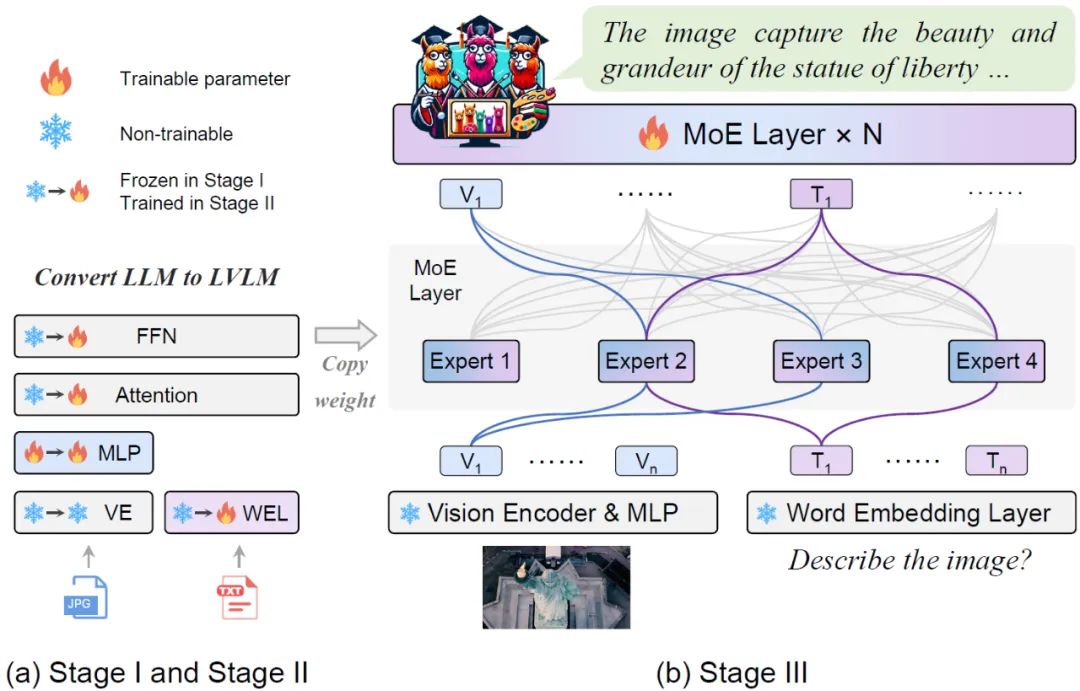

大型视觉语言模型(lvlm)可以通过扩展模型来提高性能。然而,扩大参数规模会增加训练和推理成本,因为每个token的计算都会激活所有模型参数。 来自北京大学、中山大学等机构的研究者联合提出了一种新的训练策略,名为MoE-Tuning,用于解决多模态学习和模型稀疏性相关的性能下降问题。MoE-Tuni…
-
揭秘NVIDIA大模型推理框架:TensorRT-LLM




一、TensorRT-LLM 的产品定位 TensorRT-LLM是NVIDIA为大型语言模型(LLM)开发的可扩展推理方案。它基于TensorRT深度学习编译框架构建、编译和执行计算图,并借鉴了FastTransformer中高效的Kernels实现。此外,它还利用NCCL实现设备间的通信。开发者…
-
通义千问再开源,Qwen1.5带来六种体量模型,性能超越GPT3.5
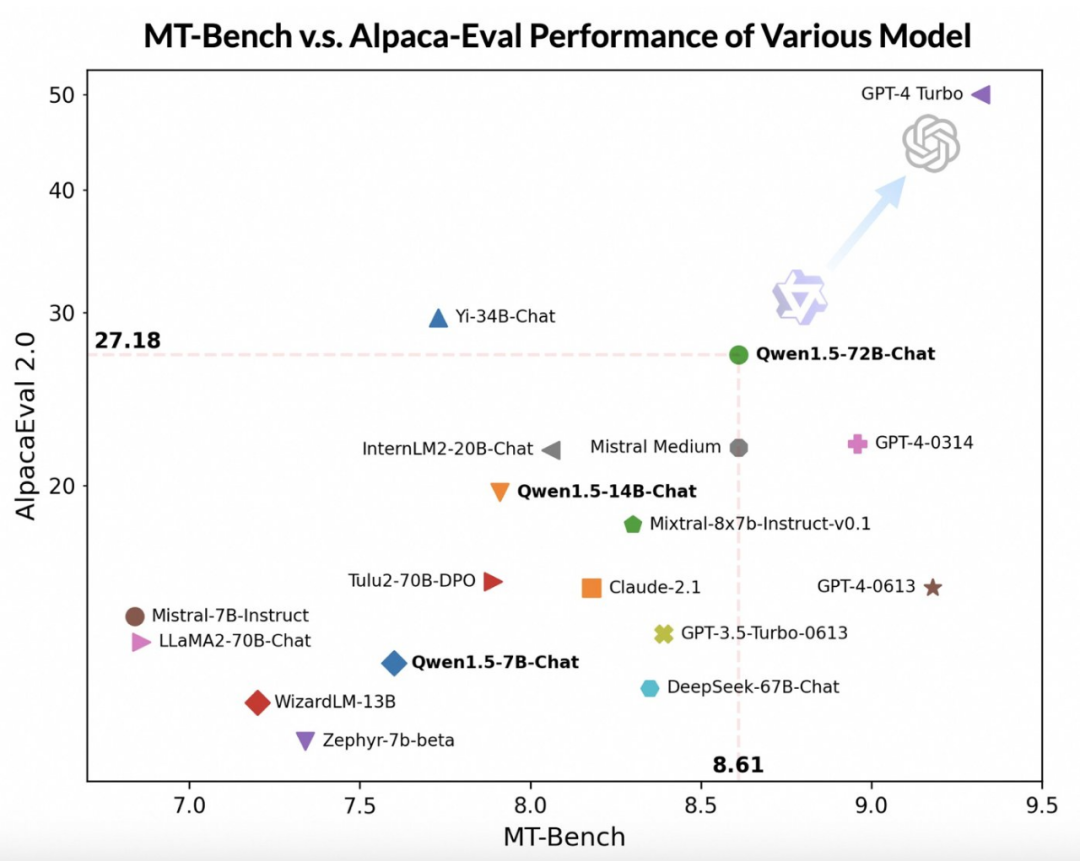

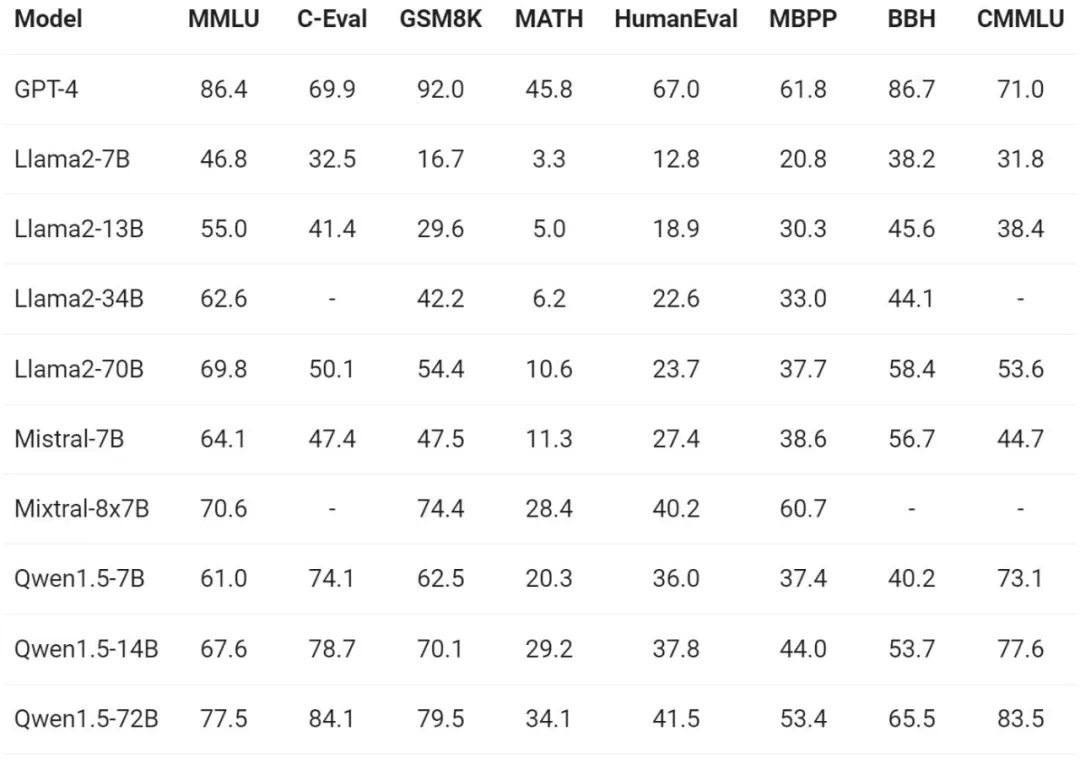
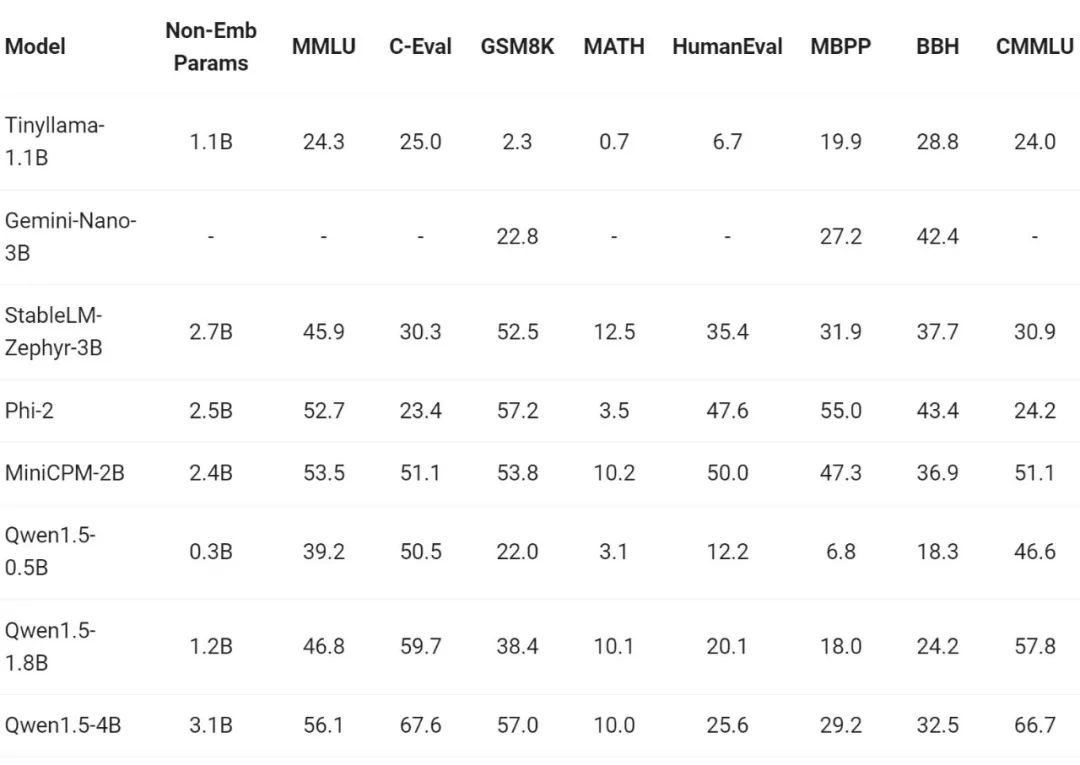
赶在春节前,通义千问大模型(qwen)的 1.5 版上线了。今天上午,新版本的消息引发了 ai 社区关注。 新版大模型包括六个型号尺寸:0.5B、1.8B、4B、7B、14B和72B。其中,最强版本的性能超越了GPT 3.5和Mistral-Medium。该版本包含Base模型和Chat模型,并提供…
-
闭源赶超GPT-4 Turbo、开源击败Llama-3-70B,歪果仁:这中国大模型真香
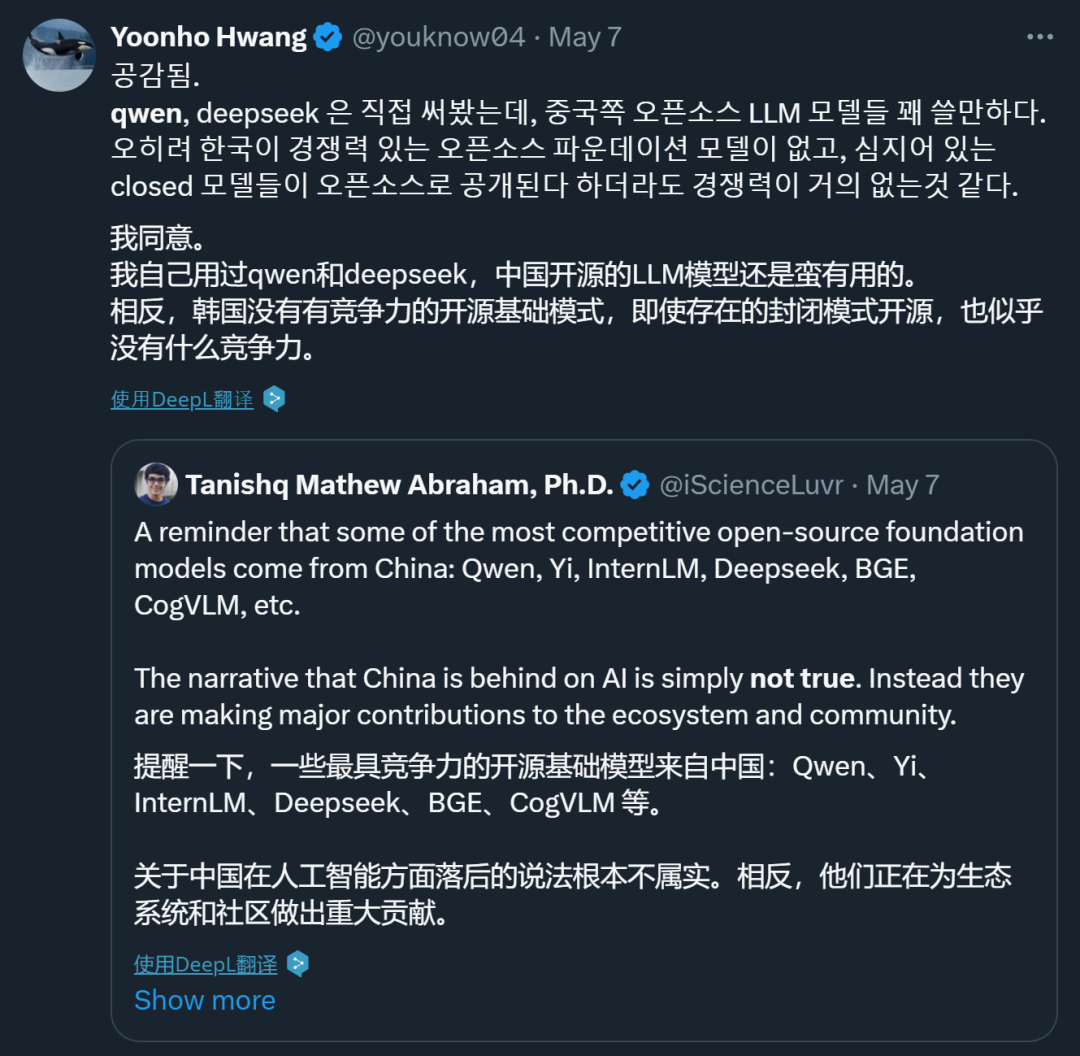
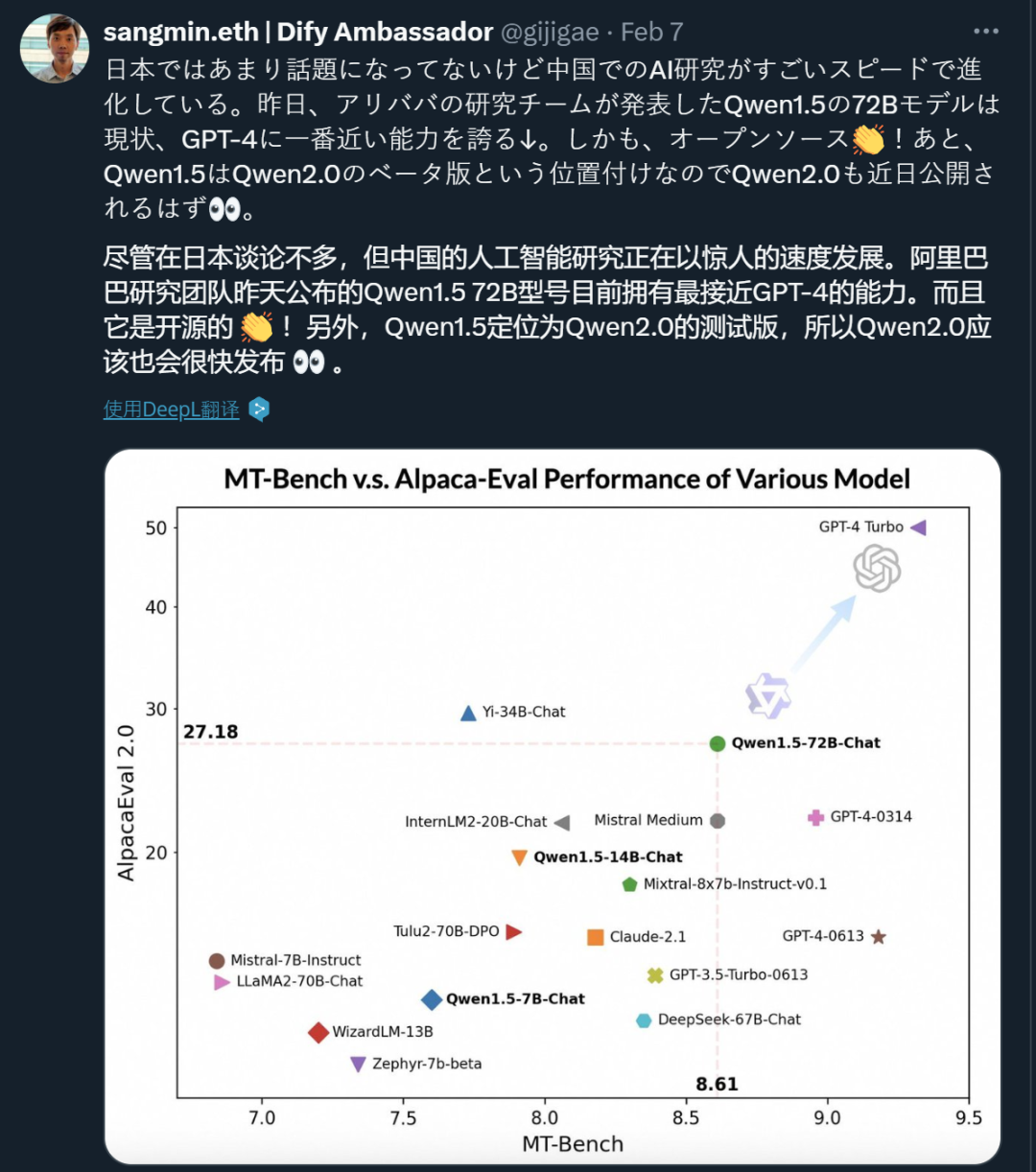
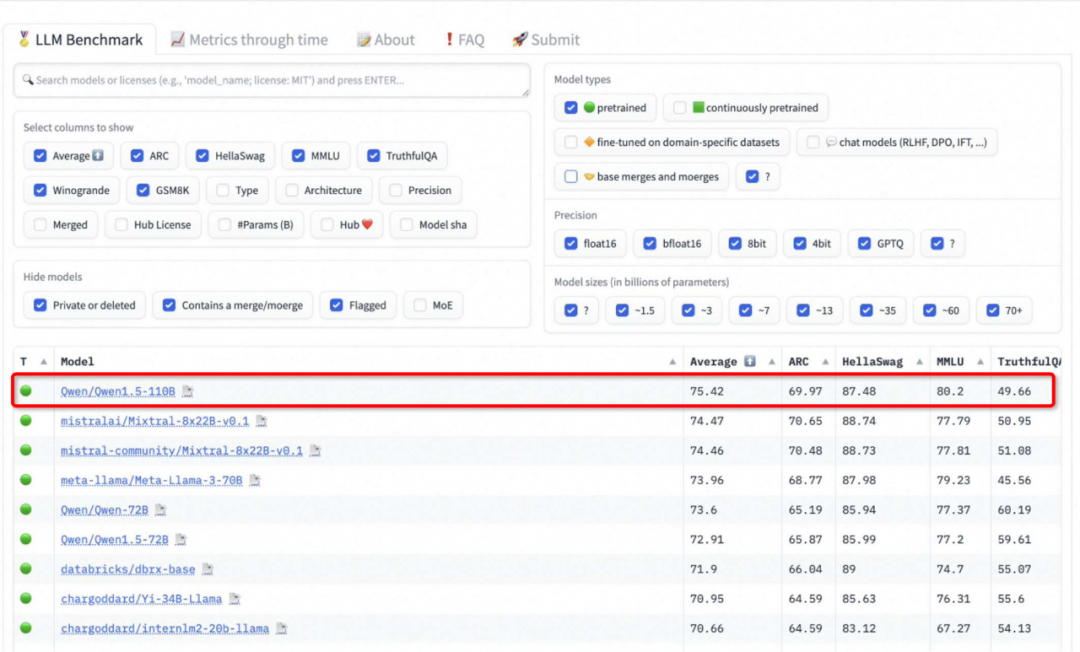
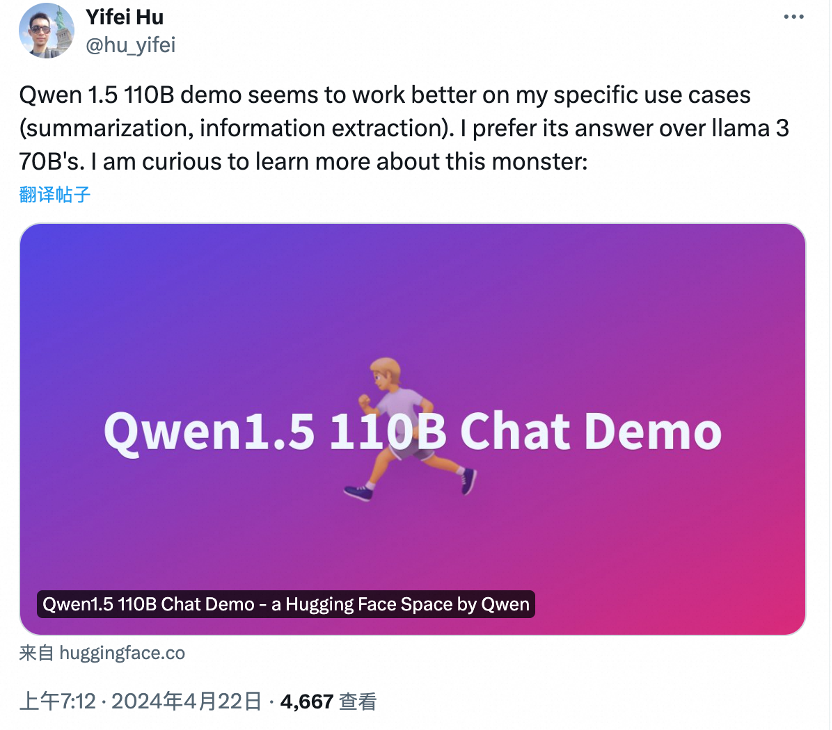
在发布一周年之际,阿里云通义千问大模型在闭源和开源领域都交上了一份满意的答卷。 国内的开发者们或许没有想到,有朝一日,他们开发的 AI 大模型会像出海的网文、短剧一样,让世界各地的网友坐等更新。甚至,来自韩国的网友已经开始反思:为什么我们就没有这样的模型? 这个「别人家的孩子」就是阿里云的通义千问(…
-
清华开源混合精度推理系统MixQ,实现大模型近无损量化并提升推理吞吐




一键部署llm混合精度推理,端到端吞吐比awq最大提升6倍! 清华大学计算机系PACMAN实验室发布开源混合精度推理系统——MixQ。 MixQ支持8比特和4比特混合精度推理,可实现近无损的量化部署并提升推理的吞吐。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSe…

