
qwen
-
参数量超1万亿!通义千问新模型Qwen3-Max性能领先引期待
近日,阿里巴巴旗下通义千问qwen上线新模型qwen3-max-preview (instruct)。官方宣称,“这是我们迄今为止最大的模型,参数量超1万亿!”参数量的飞跃为ai技术的应用开辟了全新的可能性。 Qwen3-Max-Preview在多项主流权威基准测试中展现出全球领先的性能。在通用知识…
-
阿联酋推出低成本 AI 推理模型,宣称“性价比”超同行 20 倍




阿联酋穆罕默德·本·扎耶德人工智能大学(mbzuai)在官网宣布,其与g42共同推出了一款低成本的推理模型“k2 think”。 新闻稿声称,K2 Think仅需320亿个参数,却能超越其他公司的、规模大20倍的推理模型。该模型基于阿里巴巴开源Qwen 2.5模型构建,并在Cerebras提供的硬件…
-
大模型全军覆没,中科院自动化所推出多图数学推理新基准
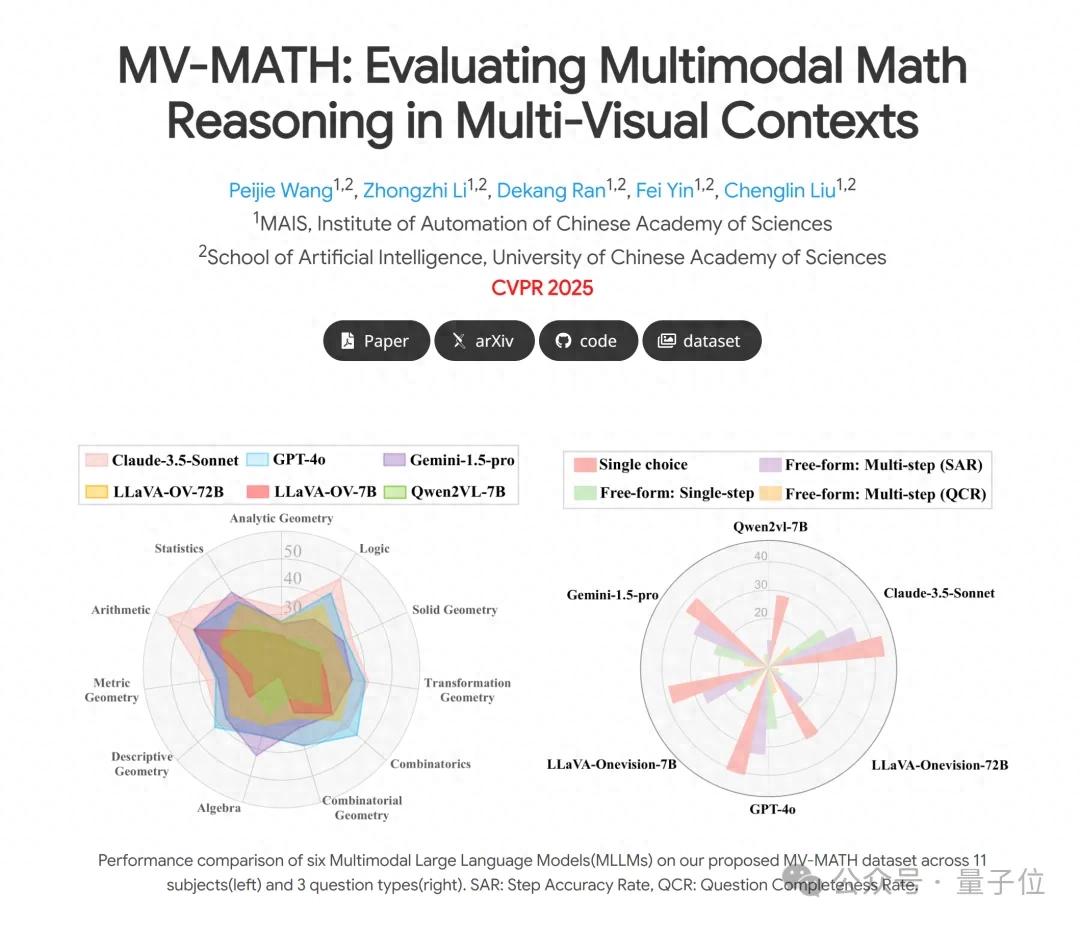
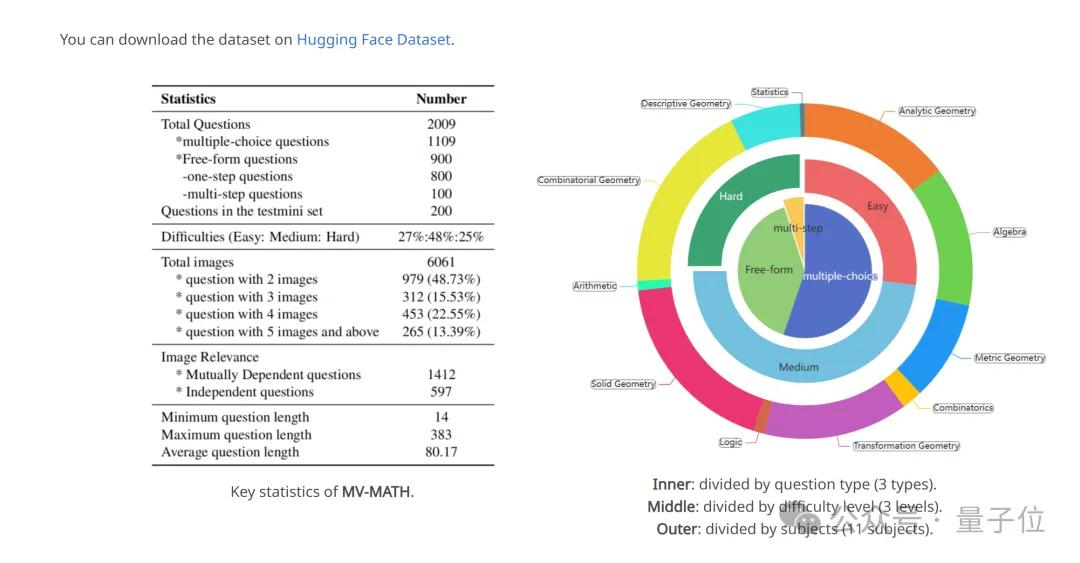
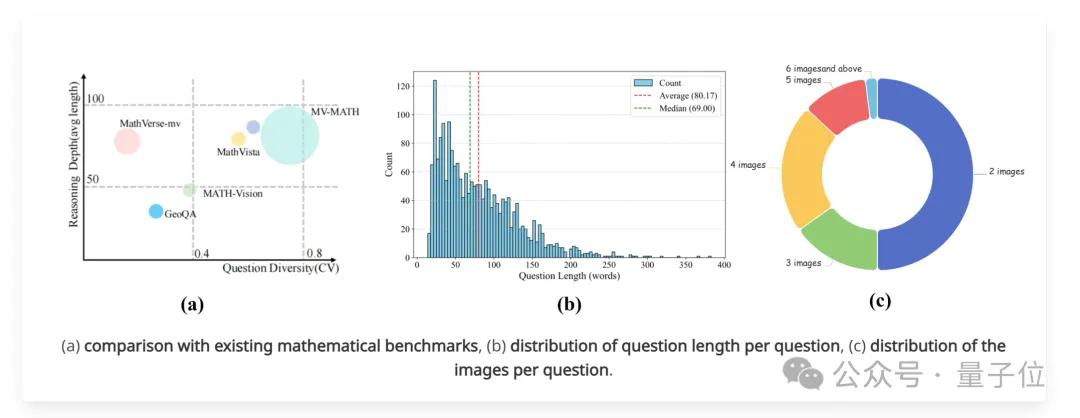
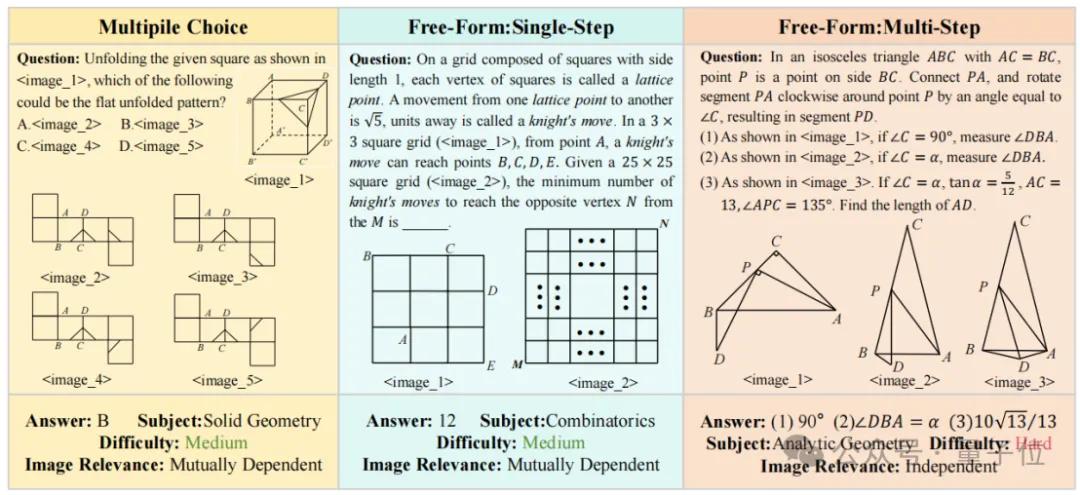
近日,中国科学院自动化研究所推出多图数学推理全新基准mv-math(该工作已被cvpr 2025录用),这是一个精心策划的多图数学推理数据集,旨在全面评估mllm(多模态大语言模型)在多视觉场景中的数学推理能力。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek…
-
蚂蚁与中国人民大学发布首个原生 MoE 扩散语言模型


蚂蚁集团联合中国人民大学正式发布业界首个基于原生MoE架构的扩散语言模型(dLLM)——“LLaDA-MoE”。 该模型采用非自回归的掩码扩散机制,突破了传统语言模型依赖自回归生成的固有范式,在上下文学习、指令理解、代码生成与数学推理等多项核心能力上达到与Qwen2.5系列相当的水平,有力挑战了“语…
-
COMET— 字节开源的通信优化系统


字节跳动推出comet:高效moe模型训练优化系统 COMET是字节跳动为解决Mixture-of-Experts (MoE)模型分布式训练中的高通信开销问题而开发的优化系统。通过细粒度的计算-通信重叠技术,COMET深度融合计算和通信操作,避免了传统方法中因粒度不匹配造成的资源浪费和延迟。 它采用…
-
OLMo 2 32B— Ai2 推出的最新开源语言模型


olmo 2 32b:一款突破性的开源语言模型 Allen Institute for AI (Ai2) 隆重推出其最新力作——OLMo 2 32B,一个参数规模达320亿的开源语言模型。该模型是OLMo 2系列的巅峰之作,在多项学术基准测试中表现卓越,甚至超越了GPT-3.5-Turbo和GPT-…
-
Moonlight-16B-A3B— 月之暗面开源的 MoE 模型


Moonlight-16B-A3B是什么 moonlight-16b-a3b 是 moonshot ai 推出的新型 mixture-of-expert (moe) 模型,具有 160 亿总参数和 30 亿激活参数。模型使用了优化后的 muon 优化器进行训练,计算效率是传统 adamw 的两倍。在…
-
亚马逊云科技推出 Qwen3 与 DeepSeek-V3.1 模型的完全托管服务


亚马逊云科技近日宣布,已在Amazon Bedrock平台正式上线Qwen3和DeepSeek-V3.1两款开放权重模型,目前该服务已面向全球用户开放。 此次发布进一步强化了亚马逊云科技作为运行开放权重AI模型首选平台的定位。Amazon Bedrock现已汇聚来自Meta、Mistral AI、O…
-
Qwen2.5-VL-32B— 阿里开源的最新多模态模型


阿里巴巴开源的qwen2.5-vl-32b:一款320亿参数的多模态语言模型 Qwen2.5-VL-32B是阿里巴巴最新推出的开源多模态模型,其参数规模达到320亿。它在Qwen2.5-VL系列的基础上,通过强化学习进行了优化,展现出更贴近人类偏好的回答风格、显著提升的数学推理能力以及更强的图像细粒…
-
Fin-R1— 上海财经联合财跃星辰推出的金融推理大模型


fin-r1:上海财经大学与财跃星辰合作推出的金融领域大型语言模型 Fin-R1是上海财经大学人工智能金融实验室(SUFE-AIFLM-Lab)与财跃星辰联合研发的首个金融领域R1类推理大模型。它基于Qwen2.5-7B-Instruct架构,拥有70亿参数,并经过两阶段训练:监督微调(SFT)和强…

