
udio
-
颜水成挂帅,昆仑万维2050全球研究院联合NUS、NTU发布Vitron,奠定通用视觉多模态大模型终极形态
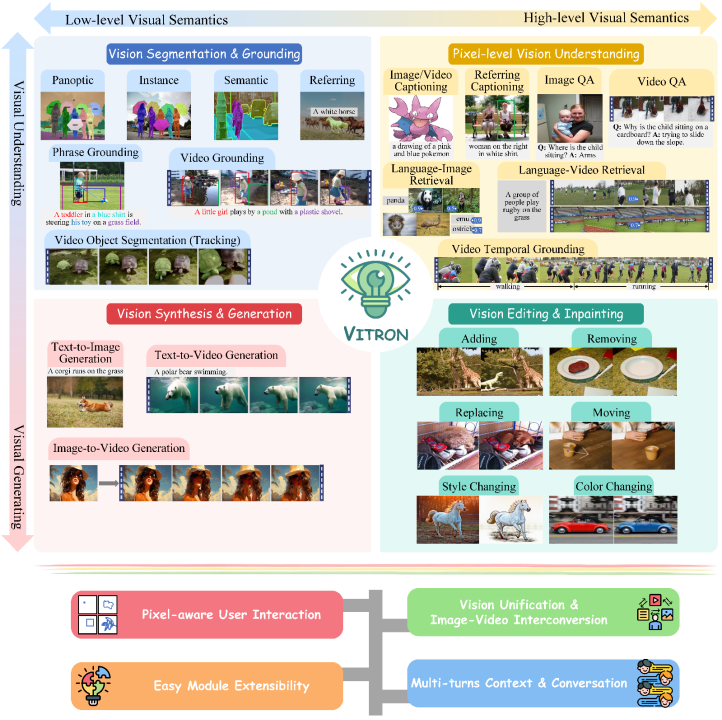

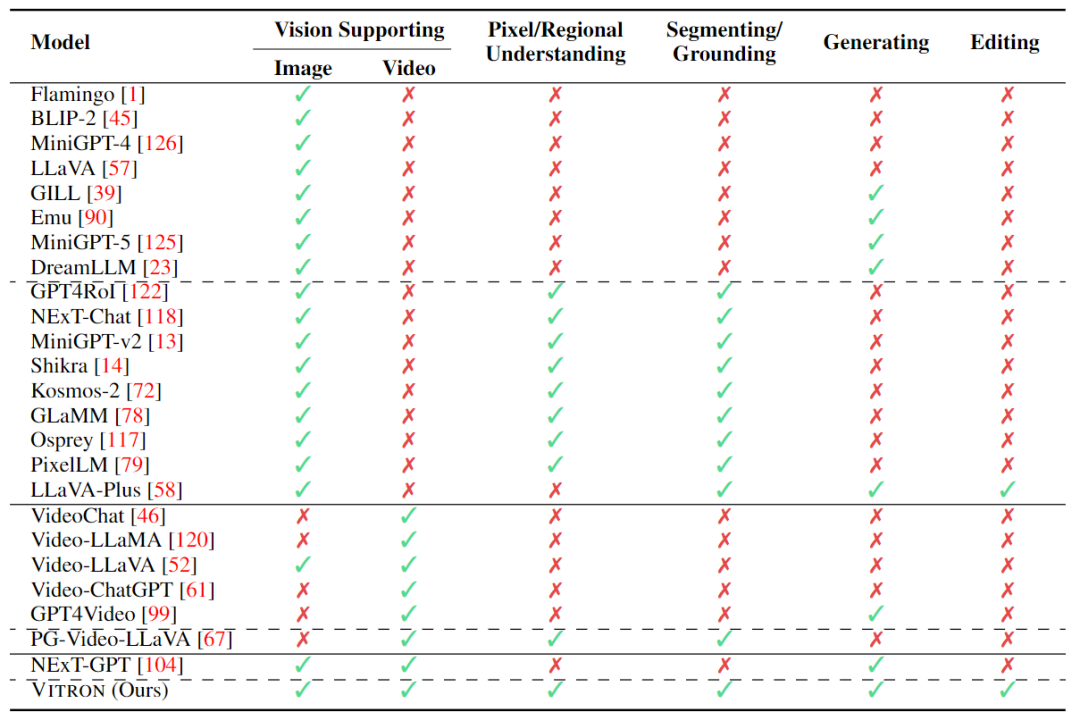
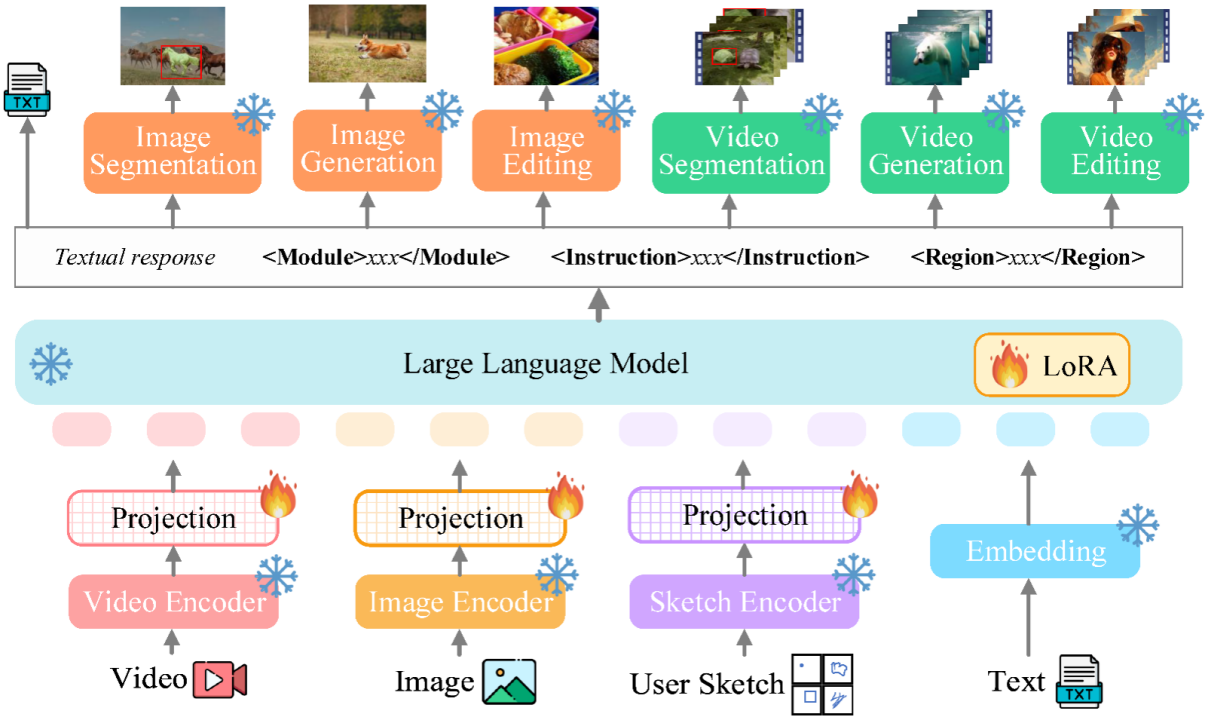
近日,由颜水成教授带队,昆仑万维2050全球研究院、新加坡国立大学、新加坡南洋理工大学团队联合发布并开源了vitron通用像素级视觉多模态大语言模型。 这是一款重磅的通用视觉多模态大模型,支持从视觉理解到视觉生成、从低层次到高层次的一系列视觉任务,解决了困扰大语言模型产业已久的图像/视频模型割裂问题…
-
闭源赶超GPT-4 Turbo、开源击败Llama-3-70B,歪果仁:这中国大模型真香
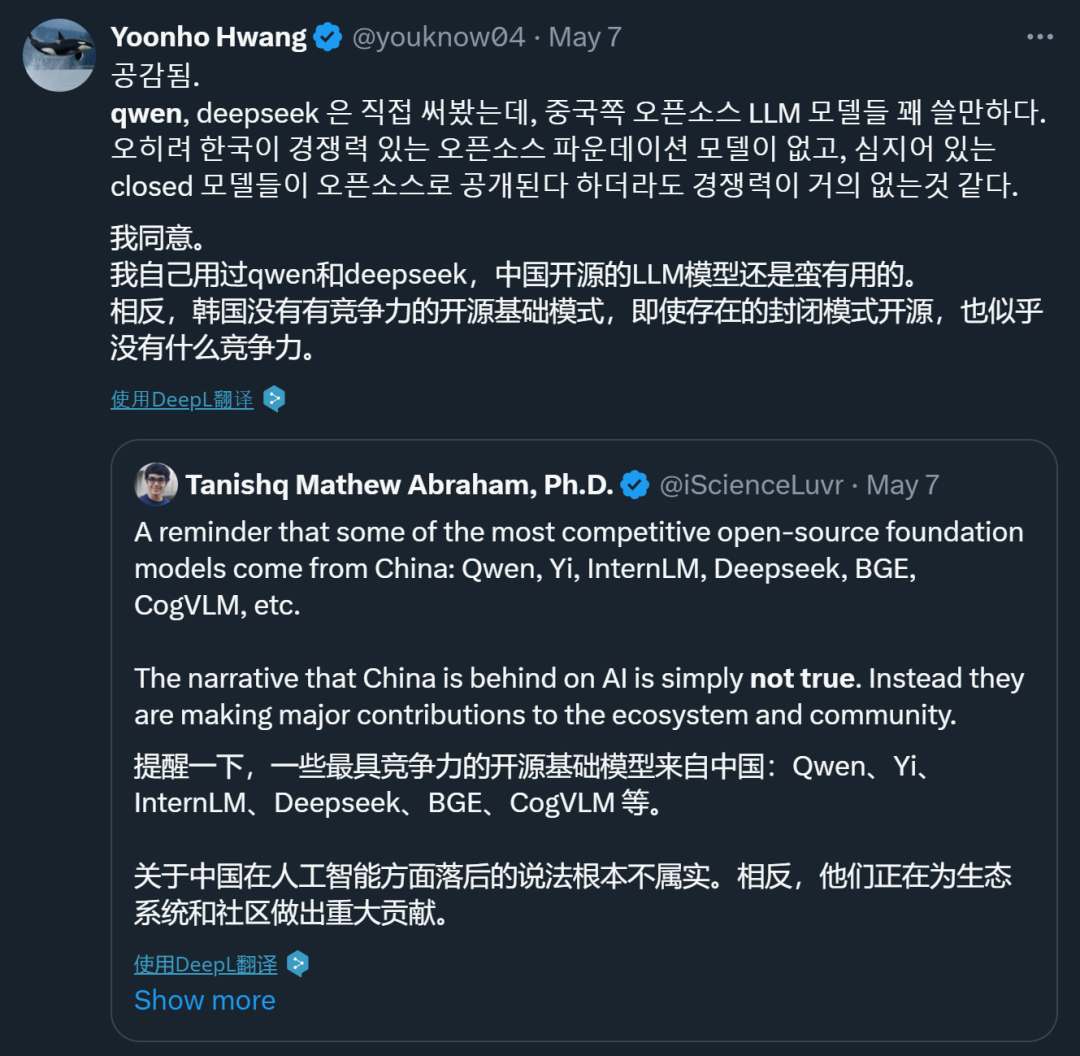
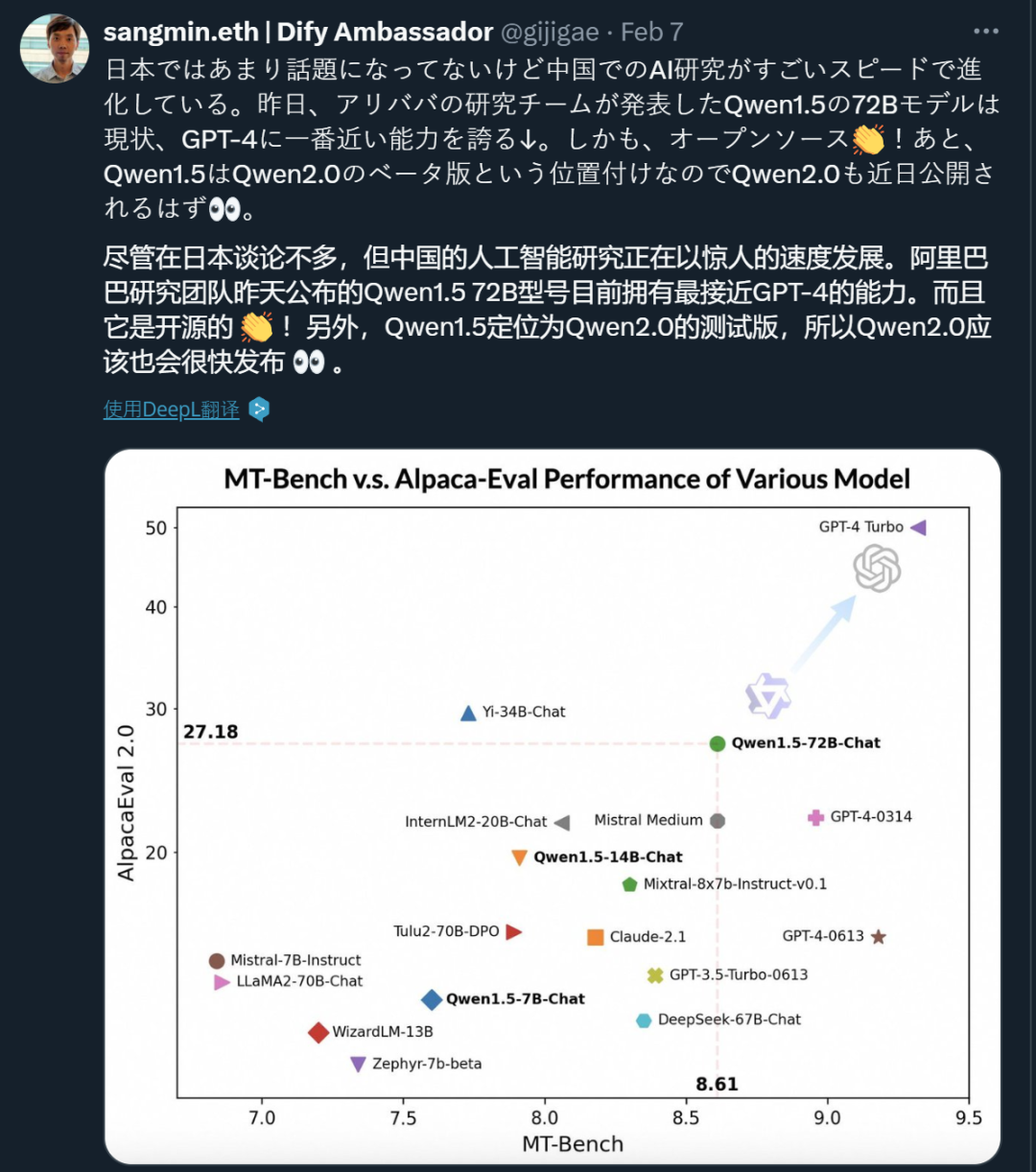
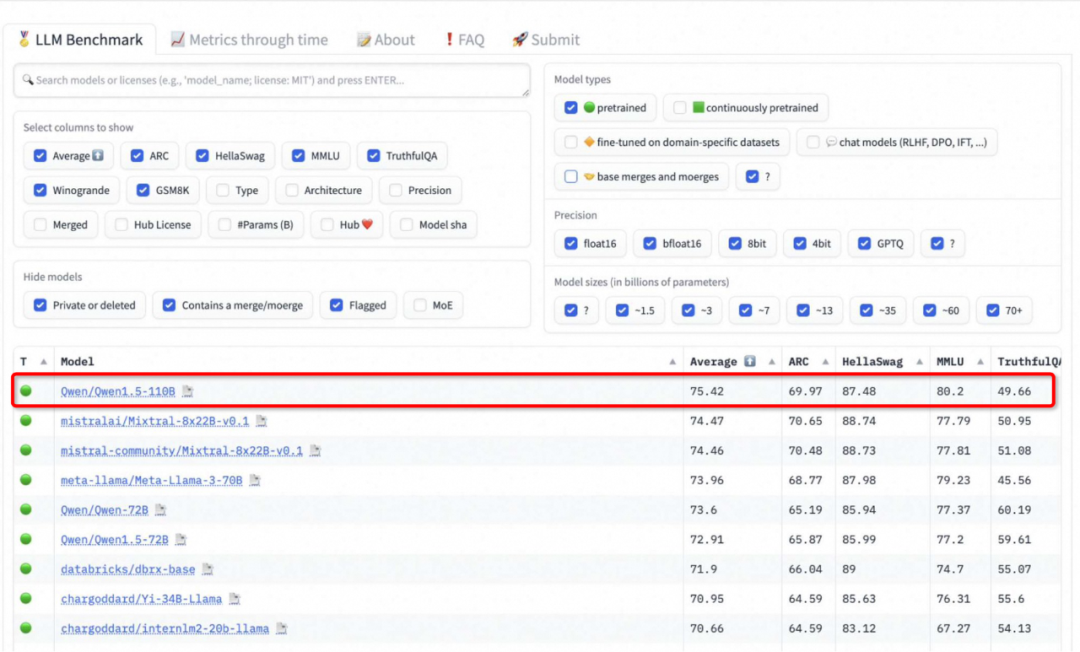
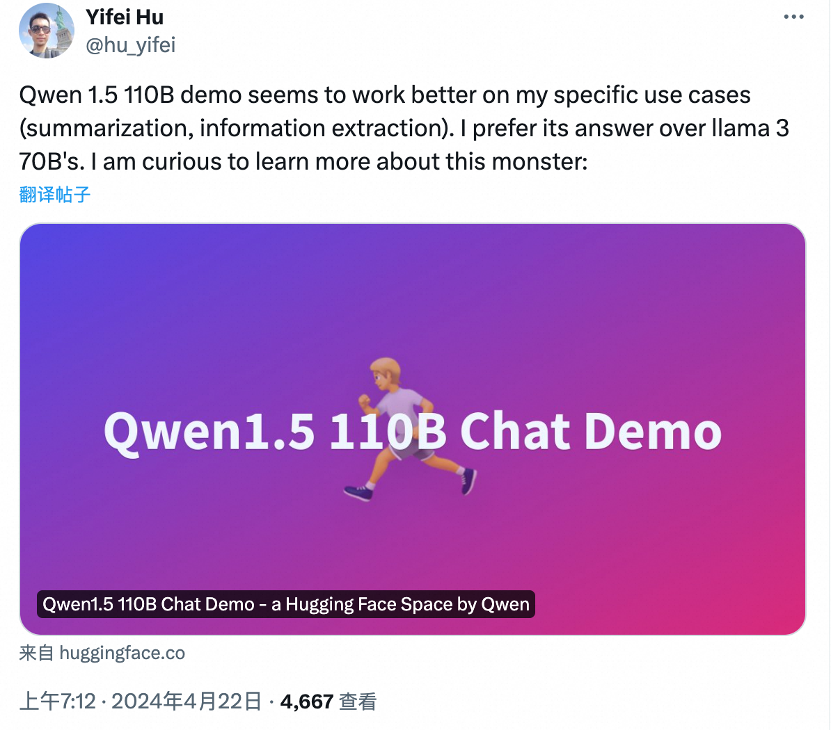
在发布一周年之际,阿里云通义千问大模型在闭源和开源领域都交上了一份满意的答卷。 国内的开发者们或许没有想到,有朝一日,他们开发的 AI 大模型会像出海的网文、短剧一样,让世界各地的网友坐等更新。甚至,来自韩国的网友已经开始反思:为什么我们就没有这样的模型? 这个「别人家的孩子」就是阿里云的通义千问(…
-
用 Deepseek 满血版和 Descript Audio,编辑专业音频作品



用 deepseek 满血版 + descript audio 组合可实现专业级音频后期处理。1. 先通过 whisper 生成字幕文本,再由 deepseek 整理成通顺文稿,确保语音识别准确并辅助剪辑;2. 在 descript 中导入整理后的文字,自动对齐音频并实现“文本质感”编辑,支持划掉口…
-
基于paddlehub2.4.0: 让动态视频生成漫画书!【一键运行】


该项目基于PaddleHub2.4.0,实现动态视频转漫画书功能。以人民美术出版社版《水浒传》连环画为风格学习数据,借助其预训练模型,通过安装依赖、处理数据、图片转漫画、视频关键帧转漫画等步骤,抽取视频关键帧并转为漫画风格,为视频创作提供新形式,展现了AI在文化创意领域的潜力。 ☞☞☞AI 智能聊天…
-
【新手入门】检索篇 – RAG技术深度实战与优化
本文围绕RAG技术展开深度解析,介绍其基础原理,即结合信息检索与文本生成,解决大模型知识截止、深度不足等问题。还阐述核心组件,如文档加载器等,讲解文档分块策略、向量化与相似度计算,以及检索策略优化、系统集成、性能优化和实际应用案例等内容。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无…
-
【AI达人特训营第三期】时频图分类项目

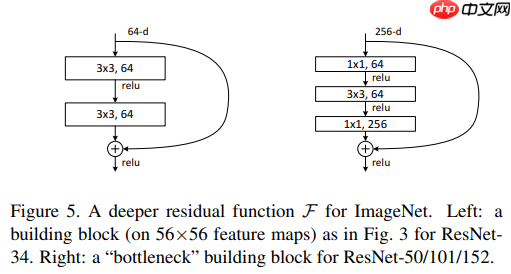

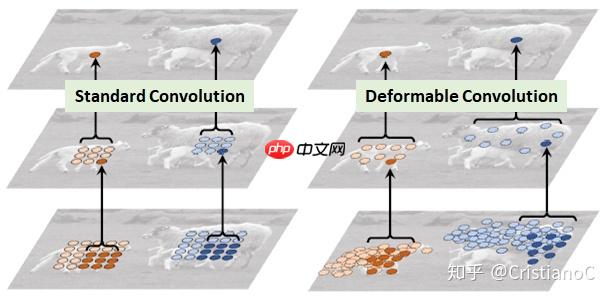
本项目基于ResNet50,将其BottleneckBlock模块中conv2特征层的标准卷积替换为DCN可变性卷积,构建ResNet50-DCN模型,用于科大讯飞24类语音时序图谱分类。使用2143条训练样本、429条验证样本训练,90轮后验证集最高准确率79%,未深入调优,有提升空间,还包含数据…
-
Higgs Audio V2— 开源语音大模型,能模拟多人互动场景




☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 豆包大模型 字节跳动自主研发的一系列大型语言模型 834 查看详情 Higgs Audio V2是什么 higgs audio v2 是由李沐及其领导的 boson ai 团队推出的一款开源语音…
-
【AI达人特训营第三期】Conv2Former:一种ViT风格的卷积模块

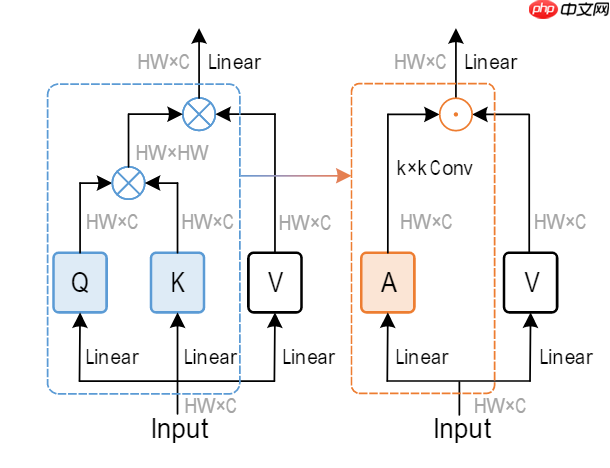
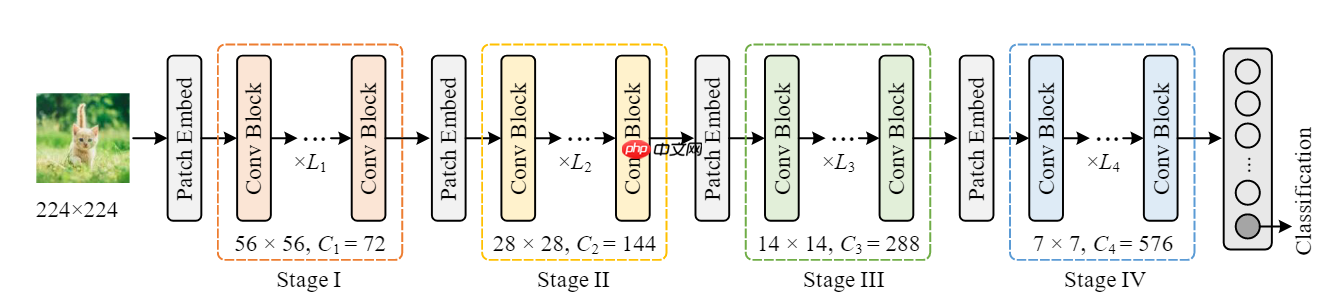
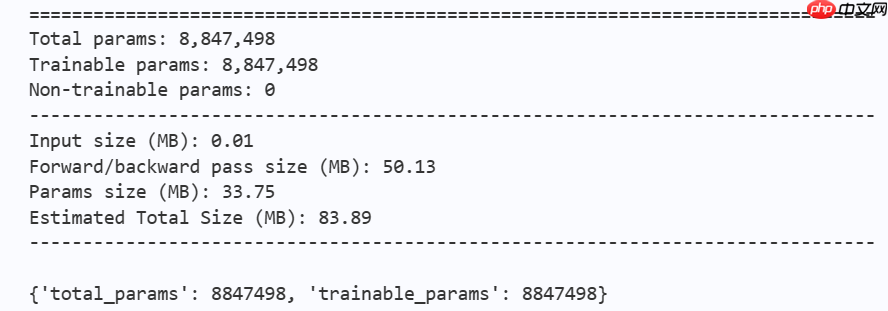
本文复现了Conv2Former模型,其采用Transformer风格的QKV结构,以卷积生成权重加权,平衡全局信息提取与计算开销。在CIFAR-10数据集上,用Conv2Former-N参数({64,128,256,512}维度,{2,2,8,2}深度)训练50个epoch,验证集准确率达82%,…
-
情人节:借助二次元老婆研究特征解耦


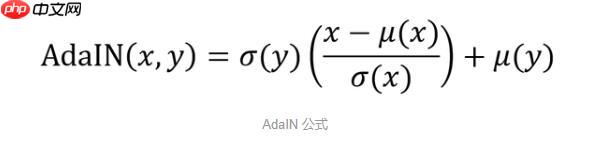

本项目旨在实现二次元头像的特征解耦,让B头像风格影响A头像主体且保持A大体不变。采用Konachan动漫头像数据集,基于SPADE架构,A为内容主体,B为风格。通过Encoder-Decoder提取特征,利用KLDLoss、VGG损失等训练,使生成图融合A主体与B风格,测试显示能体现特征影响差异。 …
-
【论文复现】 MnasNet复现以及一些感想

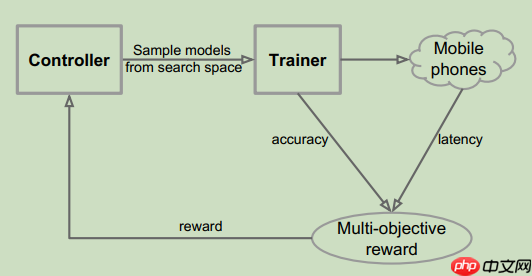


本文围绕MnasNet复现展开,介绍了这一谷歌提出的轻量化网络,其通过自动搜索平衡精度与延迟,采用真实手机环境测延迟。复现基于PyTorch实现转为Paddle版本,调整了因硬件限制的参数,采用预热策略等,还提及训练中遇到的精度提升问题及解决办法,最后分享了复现收获。 ☞☞☞AI 智能聊天, 问答助…

