
训练
-
重新表达的标题为:字节跳动与华东师大的合作:探索小模型的上下文学习能力




众所周知,大型语言模型(LLM)可以通过上下文学习的方式从少量示例中学习,无需进行模型微调。目前,这种上下文学习现象只能在大型模型中观察到。例如,像GPT-4、Llama等大型模型在许多领域中都表现出了卓越的性能,但由于资源限制或实时性要求较高,许多场景无法使用大型模型 那么,常规大小的模型是否具备…
-
谷歌新方法ASPIRE:赋予LLM自我评分能力,有效解决「幻觉」问题,超越10倍体积模型
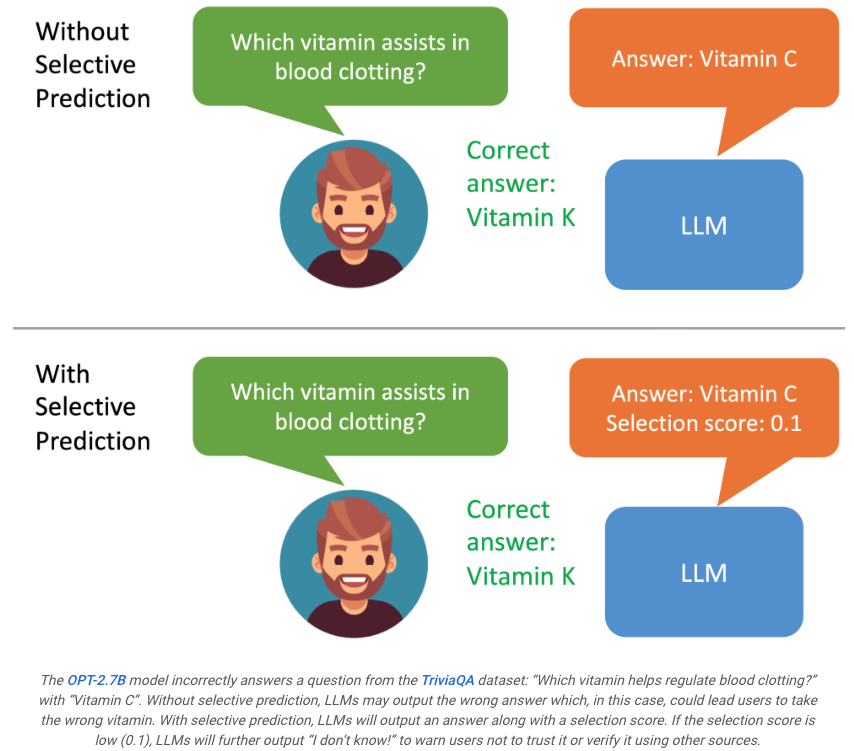

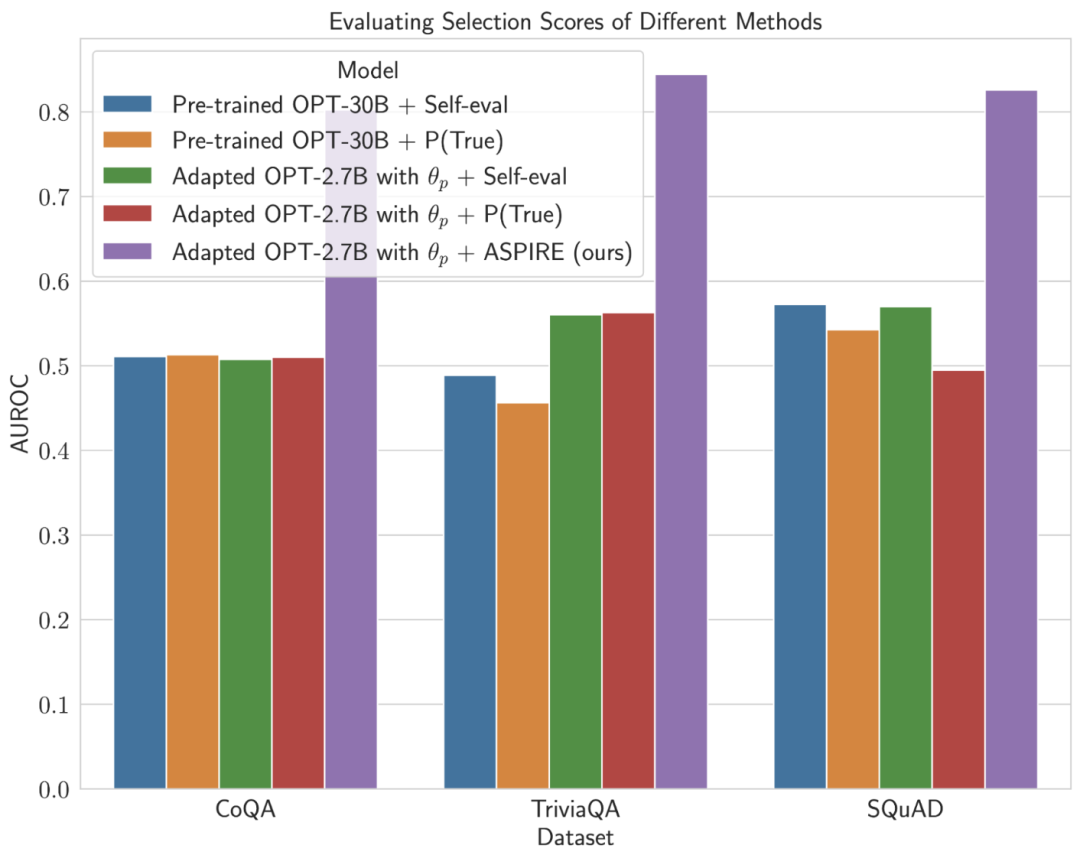
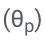
大模型的「幻觉」问题马上要有解了? 威斯康星麦迪逊大学和谷歌的研究人员最近推出ASPIRE系统,使大模型能够自评输出。 如果用户看到模型的生成的结果评分不高,就能意识到这个回复可能是幻觉。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 如果…
-
7.7亿参数,超越5400亿PaLM!UW谷歌提出「分步蒸馏」,只需80%训练数据|ACL 2023

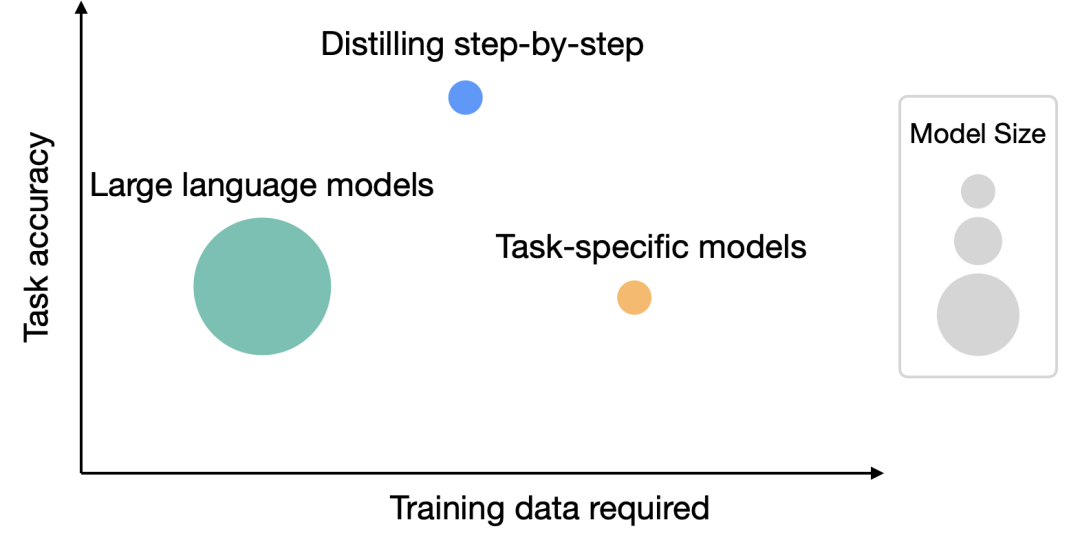
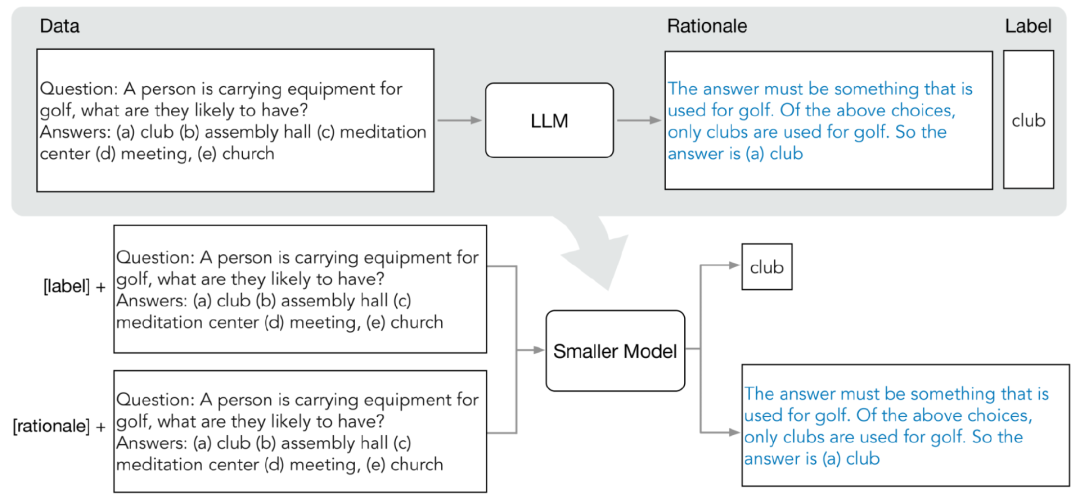

大型语言模型在性能方面表现出色,能够通过零样本或少样本提示来解决新任务。然而,在实际应用部署中,LLM却不太实用,因为它的内存利用效率低,同时需要大量的计算资源 比如运行一个1750亿参数的语言模型服务至少需要350GB的显存,而目前最先进的语言模型大多已超过5000亿参数量,很多研究团队都没有足够…
-
用Vision Pro实时训练机器狗!MIT博士生开源项目火了




vision pro又现火爆新玩法,这回还和具身智能联动了~ 就像这样,MIT小哥利用Vision Pro的手部追踪功能,成功实现了对机器狗的实时控制。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 不仅开门这样的动作能精准get: 也几乎…
-
开源11天,马斯克再发Grok-1.5!128K代码击败GPT-4


Grok-1官宣开源不过半月,新升级的Grok-1.5出炉了。 刚刚,马斯克xAI官宣,128K上下文Grok-1.5,推理能力大幅提升。 并且,很快就会上线。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 11天前,Grok-1模型的权重…
-
语言、机器人破壁,MIT等用GPT-4自动生成模拟任务,并迁移到真实世界




☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 在机器人领域,实现通用机器人策略需要大量数据,而在真实世界收集这些数据又耗时费力。尽管模拟为生成场景级和实例级的不同体量的数据提供了一种经济的解决方案,但由于需要大量的人力(尤其是对复杂任务),…
-
LLM将成历史?开源bGPT或颠覆深度学习范式:直接模拟二进制,开启模拟数字世界新纪元!




微软亚洲研究院推出的最新成果bGPT,这种基于字节的Transformer模型,为我们探索数字世界开辟了新的大门。 与传统基于词表的语言模型不同,bGPT具有独特之处,即其能够直接处理原始二进制数据,不受特定格式或任务的限制。其旨在全面模拟数字世界,为模型的发展打开了新的可能性。 ☞☞☞AI 智能聊…
-
套娃不可取:研究人员证实用AI生成的结果训练AI将导致模型退化


it之家 6 月 14 日消息,it之家的小伙伴们可能都有设想过,如果用 %ignore_a_1% 生成的结果来训练 ai,进行“套娃式训练”,能得到什么样的结果?目前还真有研究团队对此进行了观察记录,详细论文及得出的结果发表在了 arxiv 上。 一句话总结 —— “在训练中使用模型生成的内容,将…
-
“木头姐”:特斯拉的人工智能训练——“赢家通吃”的机会

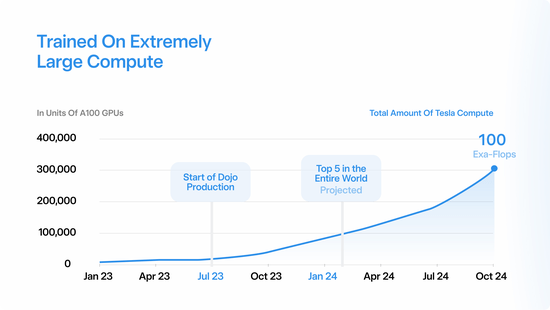
“木头姐”凯西·伍德cathie wood日前表示,如果特斯拉在加大人工智能训练方面取得成功,它将成为首家在全国范围内推出自动驾驶出租车平台的公司。 特斯拉(TSLA.O)CEO埃隆·马斯克在今年5月曾示意,机器人出租车的利润率可能高达70%或更高。 方舟投资公司,也就是“木头姐”旗下的公司,对特斯…
-
「知识型图像问答」微调也没用?谷歌发布搜索系统AVIS:少样本超越有监督PALI,准确率提升三倍



在大型语言模型(LLM)的支持下,与视觉结合的多模态任务,例如图像描述、视觉问答(VQA)和开放词汇目标识别(open-vocabulary object detection)等方面都取得了显著的进展 不过目前视觉语言模型(VLM)基本都只是利用图像内的视觉信息来完成任务,在inforseek和OK…
