
openai似乎找到了解决生成式人工智能“一本正经胡说八道”的办法。
5月31日,OpenAI在其官网宣布,已经训练了一个模型,能够有助于消除生成式AI常见的“幻觉”和其他常见问题。
OpenAI表示,可以训练奖励模型来检测幻觉,奖励模型又分为结果监督(根据最终结果提供反馈)或过程监督(为思维链中的每个步骤提供反馈)模型。
也就是说,过程监督奖励推理的每个正确步骤,而结果监督只是简单地奖励正确的答案。
OpenAI表示,相比之下,过程监督有一个重要的优势——它直接训练模型以产生由人类认可的思维链:
过程监督与结果监督相比有几个一致性优势。每个步骤都得到精确监督,因此它奖励遵循一致思维链模型的行为。 过程监督也更有可能产生可解释的推理,因为它鼓励模型遵循人类批准的过程 结果监督可能会奖励一个不一致的过程,而且通常更难审查。
OpenAI在数学数据集上测试了这两种模型,发现过程监督方法导致了“显著更好的性能”。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
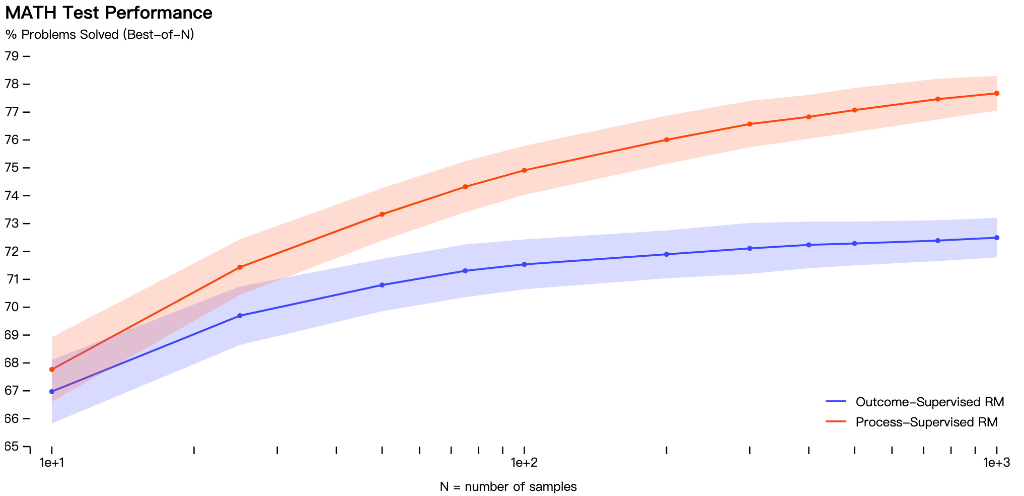
但需要注意的是,到目前为止,过程监督方法仅在数学领域进行了测试,并且需要更多的工作来观察它如何更普遍地执行。
此外,OpenAI没有说明这一研究需要多长时间才能应用在ChatGPT,它仍然处于研究阶段。
虽然最初的结果是好的,但OpenAI确实提到,更安全的方法会产生降低的性能,称为对齐税(alignment tax)。
 Waymark
Waymark
Waymark是一个视频制作工具,帮助企业快速轻松地制作高影响力的广告。
 79 查看详情
79 查看详情 
目前的结果显示,在处理数学问题时,过程监督不会产生对齐税,但在一般的信息上的情况尚不知晓。
生成式AI的“幻觉”
生成式AI问世以来,围绕其编造虚假信息、“产生幻觉”的指控从未消失,这也是目前生成式AI模型最大的问题之一。
今年2月,谷歌为应对微软资助下ChatGPT,仓促推出了聊天机器人Bard,结果却被发现在演示中出现了常识性错误,导致谷歌股价大跌。
导致AI出现幻觉的原因有多种,输入数据欺骗AI程序进行错误分类是其中一种。
例如,开发人员使用数据(如图像、文本或其他类型)来训练人工智能系统,如果数据被改变或扭曲,应用程序将以不同的方式解释输入并产生不正确的结果。
幻觉可能会出现在像ChatGPT这样的基于语言的大型模型中,这是由于不正确的转换器解码,导致语言模型可能会产生一个没有不合逻辑或模糊的故事或叙述。
以上就是解决AI落地的最大障碍,OpenAI找到办法了?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1007562.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























