
本篇文章给大家带来的内容是关于MapReduce的基本内容介绍(附代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
1、WordCount程序
1.1 WordCount源程序
import java.io.IOException;import java.util.Iterator;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount { public WordCount() { } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs(); if(otherArgs.length < 2) { System.err.println("Usage: wordcount [...] "); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(WordCount.TokenizerMapper.class); job.setCombinerClass(WordCount.IntSumReducer.class); job.setReducerClass(WordCount.IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true)?0:1); } public static class TokenizerMapper extends Mapper
1.2 运行程序,Run As->Java Applicatiion
1.3 编译打包程序,产生Jar文件
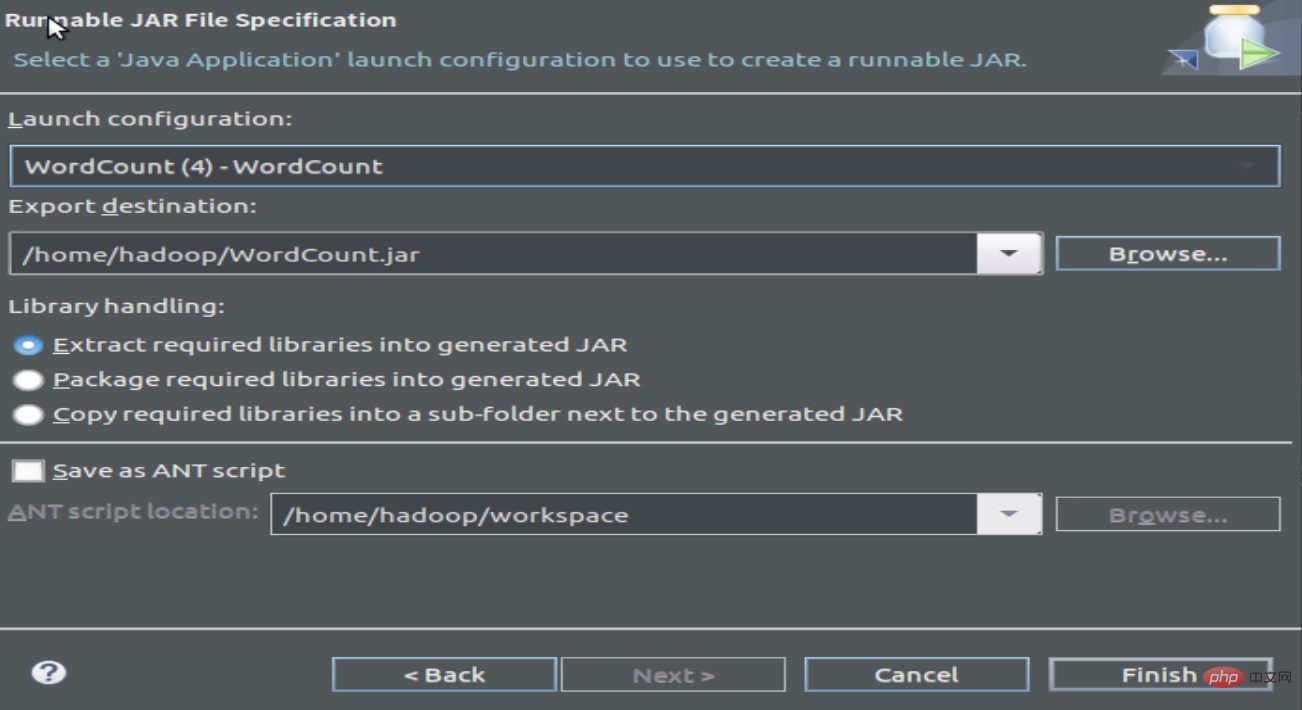
2 运行程序
2.1 建立要统计词频的文本文件
wordfile1.txt
Spark Hadoop
Big Data
wordfile2.txt
Spark Hadoop
Big Cloud
2.2 启动hdfs,新建input文件夹,上传词频文件
 腾讯云AI代码助手
腾讯云AI代码助手
基于混元代码大模型的AI辅助编码工具
 98 查看详情
98 查看详情 
cd /usr/local/hadoop/
./sbin/start-dfs.sh
./bin/hadoop fs -mkdir input
./bin/hadoop fs -put /home/hadoop/wordfile1.txt input
./bin/hadoop fs -put /home/hadoop/wordfile2.txt input
2.3 查看已上传的词频文件:
hadoop@dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -ls .
Found 2 items
drwxr-xr-x – hadoop supergroup 0 2019-02-11 15:40 input
-rw-r–r– 1 hadoop supergroup 5 2019-02-10 20:22 test.txt
hadoop@dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -ls ./input
Found 2 items
-rw-r–r– 1 hadoop supergroup 27 2019-02-11 15:40 input/wordfile1.txt
-rw-r–r– 1 hadoop supergroup 29 2019-02-11 15:40 input/wordfile2.txt
2.4 运行WordCount
./bin/hadoop jar /home/hadoop/WordCount.jar input output
屏幕上会输入大段信息
然后可以查看运行结果:
hadoop@dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -cat output/*
Hadoop2
Spark2
以上就是MapReduce的基本内容介绍(附代码)的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/376939.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


