本文经自动驾驶之心公众号授权转载,转载请联系出处。
笔者的个人思考
端到端是今年非常火的一个方向,今年的CVPR best paper也颁给了UniAD,但端到端同样也存在很多问题,比如可解释性不高、训练难收敛等等,领域的一些学者开始逐渐把注意力转到端到端的可解释性上,今天为大家分享端到端可解释性的最新工作ADAPT,该方法基于Transformer架构,通过多任务联合训练的方式端到端地输出车辆动作描述及每个决策的推理。笔者对ADAPT的一些思考如下:
这里是用视频的2D 的feature来做的预测, 有可能把2D feature转化为 bev feature之后效果会更好.与LLM结合效果可能会更好, 比如 Text Generation那部分换成LLM.当前这个工作是拿历史的视频作为输入, 预测的action及其描述也是历史的, 如果改成预测将来的action以及action对应的原因的话可能更有意义.image token化那块儿得到的 token 有点儿多,可能有很多没有用的信息, 或许可以试试Token-Learner.
出发点是什么?
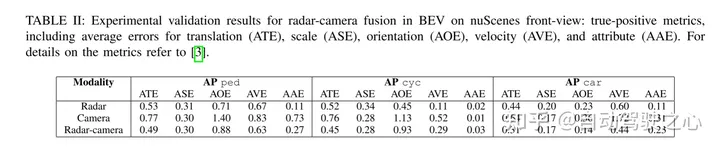
端到端自动驾驶在交通行业具有巨大潜力,而且目前对这方面的研究比较火热。像CVPR2023的best paper UniAD 做的就是端到端的自动驾驶。但是, 自动决策过程缺乏透明度和可解释性会阻碍它的发展, 毕竟实车上路,是要安全第一的。早期已经有一些尝试使用 attention map 图或 cost volume 来提高模型的可解释性,但这些方式很难理解。那么这篇工作的出发点,就是寻求一种好理解的方式来解释决策。下图是几种方式的对比, 显然用语言表达更容易理解。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
ADAPT有什么优势?
能够端到端地输出车辆动作描述及每个决策的推理;该方法基于transformer的网络结构, 通过multi-task的方式进行联合训练;在BDD-X(Berkeley DeepDrive eXplanation) 数据集上达到了SOTA的效果;为了验证该系统在真实场景中的有效性, 建立了一套可部署的系统, 这套系统能够输入原始的视频, 实时地输出动作的描述及推理;
效果展示

看效果还是非常不错的, 尤其是第三个黑夜的场景, 红绿灯都注意到了。
目前领域的进展
Video Captioning
视频描述的主要目标是用自然语言描述给定视频的对象及其关系。早期的研究工作通过在固定模板中填充识别的元素来生成具有特定句法结构的句子,这些模板不灵活且缺乏丰富性。
为了生成具有灵活句法结构的自然句子,一些方法采用序列学习的技术。具体而言,这些方法使用视频编码器来提取特征,并使用语言解码器来学习视觉文本对齐。为了使描述更加丰富,这些方法还利用对象级别的表示来获取视频中详细的对象感知交互特征
虽然现有的架构在一般 video captioning 方向取得了有一定的结果,但它不能直接应用于动作表示,因为简单地将视频描述转移到自动驾驶动作表示会丢失掉一些关键信息,比如车辆速度等,而这些对于自动驾驶任务来说至关重要。如何有效地利用这些多模态信息来生成句子目前仍在探索中。PaLM-E 在多模态句子这块儿是个不错的工作。
端到端自动驾驶
Learning-based 的自动驾驶是一个活跃的研究领域。最近CVPR2023 的best-paper UniAD, 包括后面的 FusionAD, 以及Wayve的基于World model的工作 MILE 等都是这个方向的工作。输出地形式有出轨迹点的,像UniAD, 也有直接出车辆的action的, 像MILE。
此外,一些方法对车辆、骑自行车者或行人等交通参与者的未来行为进行建模,以预测车辆的路径点,而另外一些方法则直接根据传感器输入来预测车辆的控制信号,类似于这个工作中的控制信号预测子任务
自动驾驶的可解释性
在自动驾驶领域中,大部分可解释性的方法都是基于视觉的,还有一些是基于LiDAR的工作。一些方法利用注意力图来过滤掉不显著的图像区域,使得自动驾驶车辆的行为看起来合理且可解释。然而,注意力图可能会包含一些不太重要的区域。还有一些方法使用激光雷达和高精度地图作为输入,预测其他交通参与者的边界框,并利用成本体来解释决策推理过程。此外,还有一种方法通过分割来构建在线地图,以减少对高清地图的依赖。尽管基于视觉或激光雷达的方法可以提供良好的结果,但缺乏语言解释使得整个系统看起来复杂且难以理解。一项研究首次探索了自动驾驶车辆的文本解释可能性,通过离线提取视频特征来预测控制信号,并进行视频描述的任务
自动驾驶中的Multi-task learning
这个端到端的框架采用多任务学习,用文本生成和预测控制信号这两个任务来联合训练模型。多任务学习在自动驾驶中用的非常多。由于更好的数据利用和共享特征,不同任务的联合训练提高了各个任务的性能,因此这个工作中, 采用的是控制信号预测和文本生成这两个任务的联合训练。
ADAPT方法
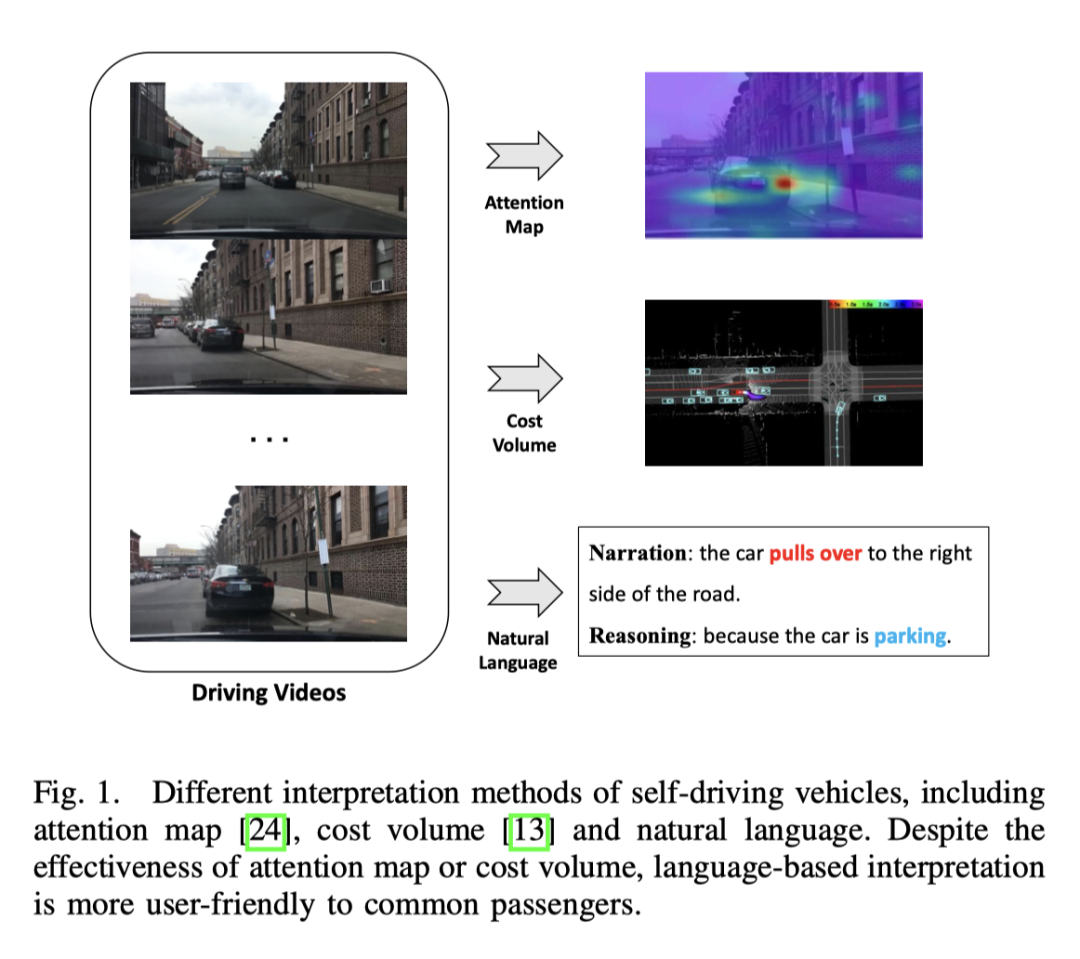
以下是网络结构图:
整个结构被分成了两个任务:
Driving Caption Generation(DCG): 输入videos, 输出两个句子, 第一句描述自车的action,第二句描述采取这个action的推理, 比如 “The car is accelerating, because the traffic lights turn green.”Control Signal Prediction(CSP) : 输入相同的videos, 输出一串控制信号, 比如速度,方向, 加速度.
其中, DCG和CSP两个任务是共享 Video Encoder, 只是采用不同的prediction heads来产生不同的最终输出。
对于 DCG 任务, 是用 vision-language transformer encoder产生两个自然语言的句子。
针对CSP任务,使用运动转换编码器来预测控制信号的序列
Video Encoder
这里采用的是 Video Swin Transformer 将输入的video frames 转为 video feature tokens。
输入 桢 image, shape 为 , 出来的feature的size 是 , 这里的 是channel的维度.
Prediction Heads
Text Generation Head
上面这个feature , 经过token化得到 个 维度为 的video token, 然后经过一个MLP 调整维度与 text tokens的embedding对齐, 之后将 text tokens和 video tokens 一起喂给 vision-language transformer encoder, 产生动作描述和推理。
 猫眼课题宝
猫眼课题宝
5分钟定创新选题,3步生成高质量标书!
 85 查看详情
85 查看详情 
Control Signal Prediction Head
和输入的 桢video 对应着的 有 控制信号 , CSP head的输出是 , 这里每一个控制信号不一定是一维的, 可以是多维的, 比如同时包括速度,加速度,方向等。这里的做法是 把video features token化了之后, 经过motion transformer 产生一串输出信号, loss 函数是MSE,
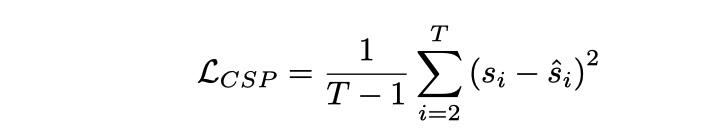
需要注意的是,在这里并没有包含第一帧,因为第一帧提供的动态信息太少了
Joint Training
在这个框架中, 因为共享的video encoder, 因此其实是假设CSP和DCG这两个任务在 video representation的层面上是对齐的。出发点是动作描述和控制信号都是车辆细粒度动作的不同表达形式,动作推理解释主要关注影响车辆动作的驾驶环境。
采用联合训练的方式进行训练
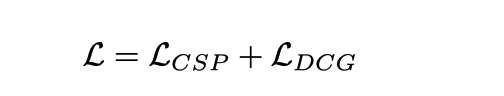
需要注意的是, 虽然是联合训练地,但是推理的时候,却可以独立执行, CSP任务很好理解, 根据流程图直接输入视频,输出控制信号即可, 对于DCG任务, 直接输入视频, 输出描述和推理, Text 的产生是基于自回归的方式一个单词一个单词的产生, 从[CLS]开始, 结束于 [SEP]或者是达到了长度阈值。
实验设计与对比
数据集
使用的数据集是 BDD-X, 这个数据集包含了 7000段成对的视频和控制信号。每段视频大约40s, 图像的大小是 , 频率是 FPS, 每个video都有1到5种车辆的行为,比如加速,右转,并线。所有这些行为都有文本注释,包括动作叙述(例如,“汽车停下来”)和推理(例如,“因为交通灯是红色的”)。总共大约有 29000 个行为注释对。
具体实现细节
video swin transformer 在 Kinetics-600 上面预训练过vision-language transformer 和 motion transformer是随机初始化的没有固定 video swin 的参数, 所以整个是端到端训练的输入的视频桢大小经过resize和crop, 最终输入网络的是 224×224对于描述和推理,用的是WordPiece embeddings [75] 而不是整个words, (e.g., ”stops” is cut to ”stop” and ”#s”), 每个句子的最大长度是15训练的时候对于 masked language modeling 会随机mask掉50%的tokens, 每个mask的token 有80%的概率 会成为 【MASK】这个token, 有10%的概率会随机选择一个word, 剩下的10%的概率保持不变。用的是AdamW 的优化器, 并且在前10%的训练 steps中, 有warm-up的机制用4个V100的GPU大约要训练13个小时
联合训练的影响
这里对比了三个实验说明了联合训练的有效性.
Single
指的是把CSP任务移掉,只保留着DCG的任务, 相当于只训 captioning 模型.
Single+
尽管CSP的任务仍然不存在,但在输入DCG模块时,除了视频标记之外,还需要输入控制信号标记
效果对比如下
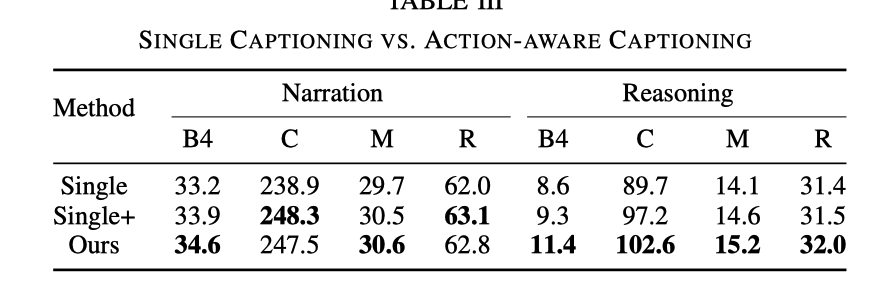
相比只有DCG任务,ADAPT的Reasoning效果明显更好。虽然有控制信号输入时效果有所提升,但是仍然不及加入CSP任务的效果好。加入CSP任务后,对视频的表示和理解能力更强
另外下面这个表格也说明了联合训练对于 CSP的效果也是有提升的.

这里 可以理解为精度, 具体会把预测的控制信号做一个截断,公式如下
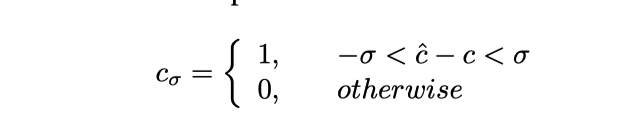
不同类型控制信号的影响
在实验中,使用的基础信号有速度和航向。然而,实验发现,当只使用其中任何一个信号时,效果都不如同时使用两个信号的效果好,具体数据如下表所示:
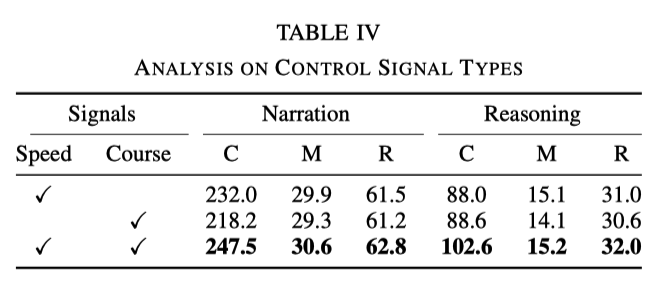
这表明速度和方向这两个信号可以帮助网络更好地学习动作描述和推理
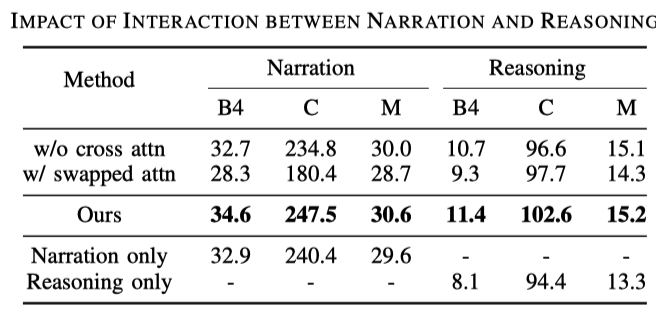
动作描述与推理之间的交互
与一般描述任务相比,驾驶描述任务生成是两个句子,即动作描述和推理。通过下表可以发现:
第1,3行说明使用cross attention效果要更好一些, 这也好理解, 基于描述来做推理有利于模型的训练;第2,3行说明交换推理和描述的顺序也会掉点, 这说明了推理是依赖于描述的;后面三行对比来看, 只输出描述和只输出推理都不如二者都输出的时候效果好;
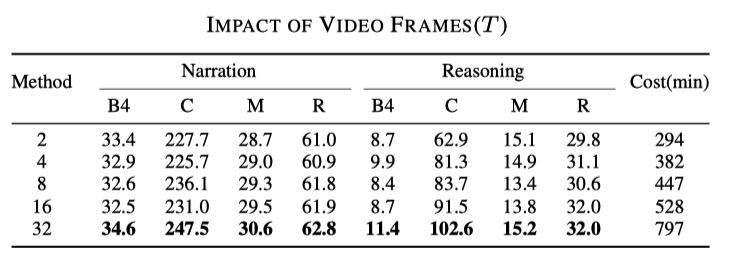
Sampling Rates 的影响
这个结果是可以猜到的, 使用的帧越多,结果越好,但是对应的速度也会变慢, 如下表所示

需要重写的内容是:原文链接:https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
以上就是新标题:ADAPT:端到端自动驾驶可解释性的初步探索的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/483678.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫