
环境准备
我使用的是CentOS-6.7版本的3个虚拟机,主机名为hadoop01、hadoop02、hadoop03。这3台虚拟机既是Zookeeper集群,又是Kafka集群(但在生产环境中,这两个集群通常会部署在不同的机架上)。我将使用hadoop用户来搭建集群(在生产环境中,root用户通常不被允许随意使用)。关于虚拟机的安装,可以参考以下两篇文章:在Windows中安装一台Linux虚拟机,以及通过已有的虚拟机克隆四台虚拟机。Zookeeper集群参考zookeeper-3.4.10的安装配置。Kafka安装包的下载地址为:https://www.php.cn/link/90797bef9ef6175e04f3c9383568f9e4。
将Kafka安装包上传到服务器并解压
[hadoop@hadoop01 ~]$ tar -zxvf /opt/soft/kafka_2.11-0.10.2.1.tgz -C /opt/apps/
进入Kafka的config目录下,修改server.properties文件
[hadoop@hadoop01 ~]$ cd /opt/apps/kafka_2.11-0.10.2.1/config/[hadoop@hadoop01 config]$ vim server.propertiesbroker.id=1host.name=192.168.42.101log.dirs=/opt/data/kafkazookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
说明:
只需修改上述列出的4个配置,其余保持默认。host.name这个配置在原文件中不存在,需要手动添加,建议使用IP地址而不是主机名。这个配置在Kafka单节点或伪分布式集群中不需要设置。broker.id在每个节点上必须唯一,我设置hadoop01的broker.id=1,hadoop02的broker.id=2,hadoop03的broker.id=3。log.dirs指定Kafka数据的存储位置,默认的tmp目录会定期清空,因此需要修改,并且在启动Kafka集群前需要创建指定的目录。zookeeper.connect如果不指定,将使用Kafka自带的Zookeeper。
分发安装包
[hadoop@hadoop01 apps]$ scp -r kafka_2.11-0.10.2.1 hadoop03:`pwd`
分别修改hadoop02和hadoop03的broker.id和host.name
在每个节点下创建log.dirs指定的目录
启动Zookeeper服务
[hadoop@hadoop01 ~]$ zkServer.sh start[hadoop@hadoop02 ~]$ zkServer.sh start[hadoop@hadoop03 ~]$ zkServer.sh start
在3个节点上都启动Kafka
[hadoop@hadoop01 kafka_2.11-0.10.2.1]$ bin/kafka-server-start.sh -daemon config/server.properties[hadoop@hadoop02 kafka_2.11-0.10.2.1]$ bin/kafka-server-start.sh -daemon config/server.properties[hadoop@hadoop03 kafka_2.11-0.10.2.1]$ bin/kafka-server-start.sh -daemon config/server.properties# -daemon选项的意思是后台启动服务
验证Kafka服务是否启动
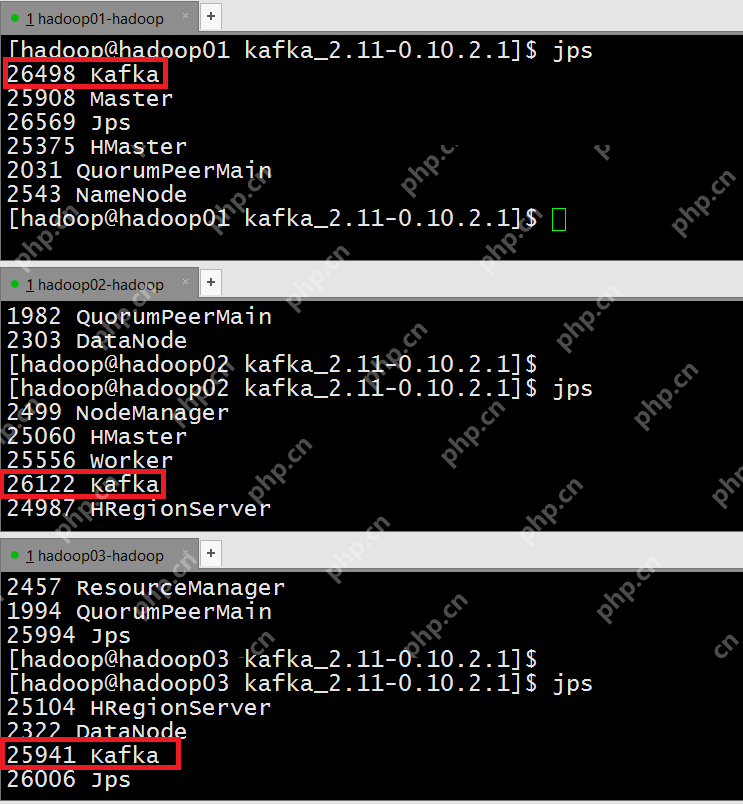
 集简云
集简云
软件集成平台,快速建立企业自动化与智能化
 22 查看详情
22 查看详情  测试Kafka集群
测试Kafka集群
(1) 在任意节点上创建”test01″这个topic
[hadoop@hadoop01 kafka_2.11-0.10.2.1]$ bin/kafka-topics.sh --create --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --replication-factor 1 --partitions 1 --topic test01
(2) 在hadoop01上开启kafka-console-producer,向test01这个topic中写入数据
[hadoop@hadoop01 kafka_2.11-0.10.2.1]$ bin/kafka-console-producer.sh --broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 --topic test01
(3) 在另一台节点上开启kafka-console-consumer,将hadoop01节点接收到的数据打印出来
[hadoop@hadoop02 kafka_2.11-0.10.2.1]$ bin/kafka-console-consumer.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --topic test01 --from-beginning
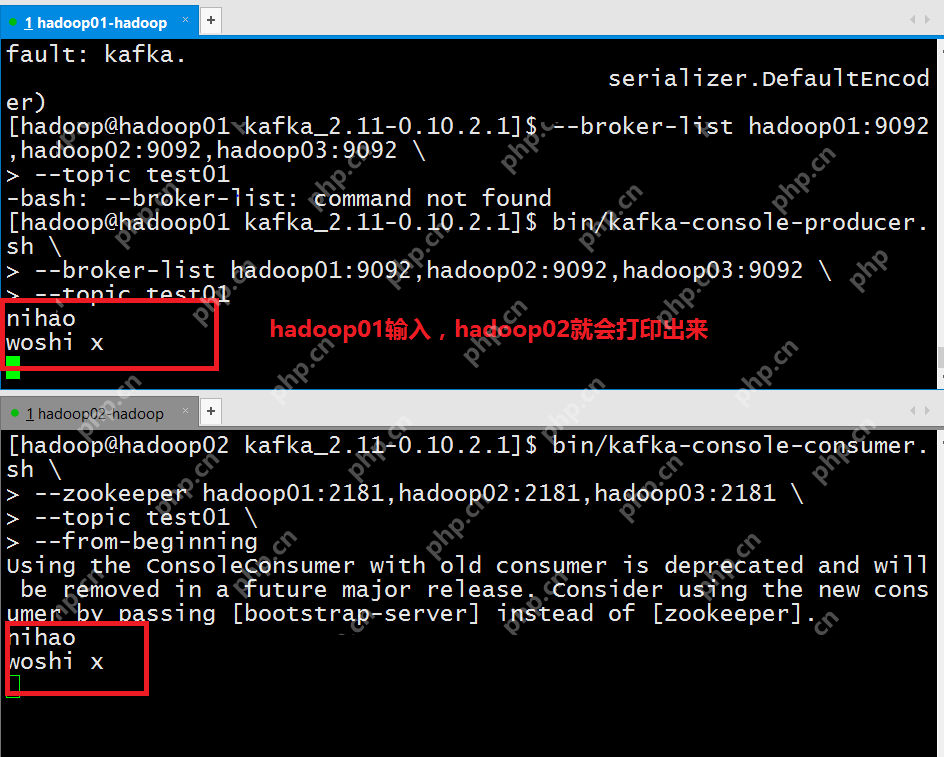
Kafka集群搭建成功!
以上就是Kafka集群搭建的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/618869.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




















