hadoop
-
Hadoop系列之一:大数据存储及处理平台产生的背景
传统的关系型数据库中的表通常由一个或多个字段组成,每个字段都预先定义了其可存储数据的格式及约束等,这类的数据就是结构化数据(structureddata)。一个设计良 传统的关系型数据库中的表通常由一个或多个字段组成,每个字段都预先定义了其可存储数据的格式及约束等,这类的数据就是结构化数据(stru…
-
hadoop跟mysql的区别是什么?




hadoop和mysql严格的来说没有任何关系,区别为hadoop是一种分布式计算框架,用于处理大量的数据,而mysql是数据库用来存放数据的。 但是一般来说,配合hadoop的数据库不是mysql这类传统的关系型数据库,因为当数据量非常大的时候,这些数据库的处理速度会非常慢(就算做了集群也一样慢)…
-
linux下安装Hadoop的方法是什么
一:安装JDK 1.执行以下命令,下载JDK1.8安装包。 wget –no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz 2.执行以下命令,解压下载的JDK…
-
企业数据中心的大数据之惑-【沈阳软件】总第16期
注:本文已经发表在2013年《沈阳软件》总第16期上,作为封面报道发表。2013年被中国IT界称为大数据年,如果你逢人不谈大数据,好像就已经跟不上时代潮流,会被业 注:所有《沈阳软件》可以从下载电子版 表单大师AI 一款基于自然语言处理技术的智能在线表单创建工具,可以帮助用户快速、高效地生成各类专业…
-
Ubuntu中关于hadoop环境变量的设置方法(图文)
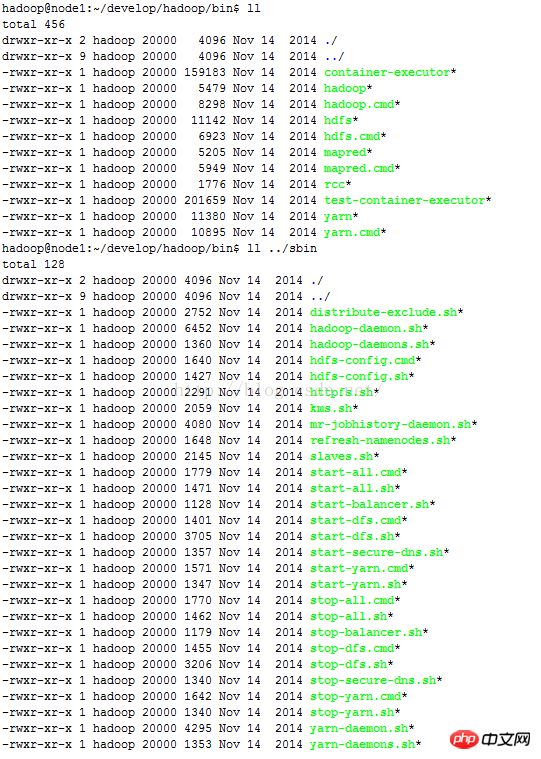


ubuntu搭建hadoop时,在/bin、/sbin等路径下有一些经常使用的工具 为了能够在任何路径下都能使用这些工具,而不必切换到bin/sbin路径下,需要设置hadoop的环境变量(注意:前提是已经设置好jdk环境变量,jdk环境变量设置方法)。 (1)使用vim/vi/gedit等命令,打…
-
Hadoop伪分布式集群搭建

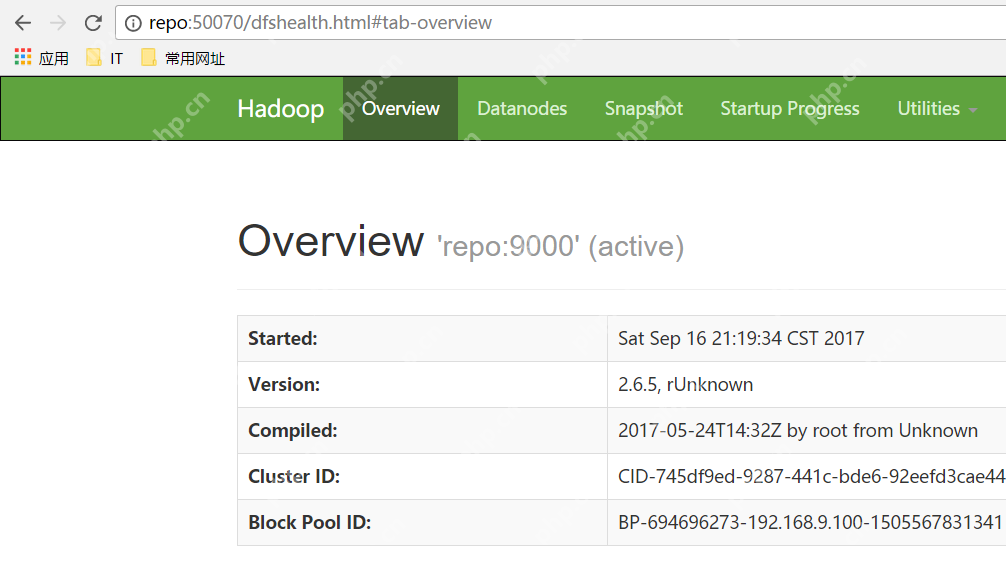
软件准备 我使用的是CentOS-6.6的虚拟机,主机名为repo。参考在Windows中安装Linux虚拟机的步骤,我在该虚拟机中安装了JDK,参考在Linux中安装JDK的指南。此外,该虚拟机配置了免秘钥登录自身,参考配置各台虚拟机之间免秘钥登录的设置。Hadoop安装包的下载地址为:https…
-
java框架在Hadoop生态系统中的集成策略


将 java 框架集成到 hadoop 生态系统的方法有三种策略:mapreduce 集成:使用 hadoop streaming 工具将 java 程序作为 mapreduce 作业执行。yarn 集成:使用 apache spark 在 yarn 上运行分布式 java 应用程序。hdfs 集成…
-
Java函数式编程如何与Hadoop或Spark框架集成实现并行计算?


java 函数式编程与 hadoop/spark 集成实现了并行计算:使用 lambda 表达式简化 mapreduce 任务,实现 map 和 reduce。利用流进行实时处理,持续过滤和聚合不断变化的数据集。该集成提供了简洁高效的方式,用于在分布式系统中执行并行计算。 Java 函数式编程与 H…
-
Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)[通俗易懂]
![Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)[通俗易懂]](https://www.chuangxiangniao.com/wp-content/uploads/2025/11/175272050088447.jpg)
![Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)[通俗易懂]](https://www.chuangxiangniao.com/wp-content/uploads/2025/11/175272050072537.jpg)
![Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)[通俗易懂]](https://www.chuangxiangniao.com/wp-content/uploads/2025/11/175272050141669.jpg)
![Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)[通俗易懂]](https://www.chuangxiangniao.com/wp-content/uploads/2025/11/175272050187161.jpg)
大家好,又见面了,我是你们的朋友全栈君。 Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)系列文章传送门 这个系列文章传送门: Hadoop入门(一)——CentOS7下载+VM上安装(手动分区)图…