本项目基于中山大学提出的无参数SimAM注意力机制,在Caltech101的16类子集上验证其效果。SimAM从神经科学出发,通过能量函数挖掘神经元重要性,生成三维权重,优于传统一维、二维注意力。项目构建含SimAM的TowerNet模型,与ResNet50等经典网络对比,经数据准备、模型训练后,显示加入SimAM后性能和鲁棒性显著提升,验证了其有效性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

① 项目背景
本文是中山大学在注意力机制方面的尝试,从神经科学理论出发,构建了一种能量函数挖掘神经元重要性,并对此推导出了解析解以加速计算。通过ImageNet分类、COCO检测与分割等任务验证了所提SimAM的灵活性与有效性。值得一提的是,所提SimAM是一种无参数注意力模块。
现有的注意力模块通常被继承到每个块中,以改进来自先前层的输出。这种细化步骤通常沿着通道维度(a)或空间维度(b)操作,这些方法生成一维或二维权重,并平等对待每个通道或空间位置中的神经元,通道注意力:1D注意力,它对不同通道区别对待,对所有位置同等对待;空域注意力:2D注意力,它对不同位置区别对待,对所有通道同等对待。这可能会限制他们学习更多辨别线索的能力。因此三维权重©优于传统的一维和二维权重注意力。
原文中作者推导了一个能量函数,并发现了每个神经元的重要性。根据(Hillyard et al.,1998),哺乳动物大脑中的注意调节通常表现为神经元反应的增益(即缩放)效应,因此作者使用缩放运算符而不是加法来细化特征,项目后边有介绍函数推导过程。
论文地址:http://proceedings.mlr.press/v139/yang21o.html
② 数据准备
2.1 解压缩数据集
我们将网上获取的数据集以压缩包的方式上传到aistudio数据集中,并加载到我们的项目内。
在使用之前我们进行数据集压缩包的一个解压。
In [1]
!unzip -oq /home/aistudio/data/data69664/Images.zip -d work/dataset
In [1]
import paddleimport numpy as npfrom typing import Callable#参数配置config_parameters = { "class_dim": 16, #分类数 "target_path":"/home/aistudio/work/", 'train_image_dir': '/home/aistudio/work/trainImages', 'eval_image_dir': '/home/aistudio/work/evalImages', 'epochs':100, 'batch_size': 32, 'lr': 0.01}
2.2 划分数据集
接下来我们使用标注好的文件进行数据集类的定义,方便后续模型训练使用。
In [3]
import osimport shutiltrain_dir = config_parameters['train_image_dir']eval_dir = config_parameters['eval_image_dir']paths = os.listdir('work/dataset/Images')if not os.path.exists(train_dir): os.mkdir(train_dir)if not os.path.exists(eval_dir): os.mkdir(eval_dir)for path in paths: imgs_dir = os.listdir(os.path.join('work/dataset/Images', path)) target_train_dir = os.path.join(train_dir,path) target_eval_dir = os.path.join(eval_dir,path) if not os.path.exists(target_train_dir): os.mkdir(target_train_dir) if not os.path.exists(target_eval_dir): os.mkdir(target_eval_dir) for i in range(len(imgs_dir)): if ' ' in imgs_dir[i]: new_name = imgs_dir[i].replace(' ', '_') else: new_name = imgs_dir[i] target_train_path = os.path.join(target_train_dir, new_name) target_eval_path = os.path.join(target_eval_dir, new_name) if i % 5 == 0: shutil.copyfile(os.path.join(os.path.join('work/dataset/Images', path), imgs_dir[i]), target_eval_path) else: shutil.copyfile(os.path.join(os.path.join('work/dataset/Images', path), imgs_dir[i]), target_train_path)print('finished train val split!')
2.3 数据集定义与数据集展示
2.3.1 数据集展示
我们先看一下解压缩后的数据集长成什么样子,对比分析经典模型在Caltech101抽取16类mini版数据集上的效果
该数据集的源为Caltech101,本次实验共抽取16类来进行比较。该数据集一共有验证集1440=4532张图片,验证集384=1232张照片。该数据集主要有以下集中类型的图片,在下方展示。In [3]
import osimport randomfrom matplotlib import pyplot as pltfrom PIL import Imageimgs = []paths = os.listdir('work/dataset/Images')for path in paths: img_path = os.path.join('work/dataset/Images', path) if os.path.isdir(img_path): img_paths = os.listdir(img_path) img = Image.open(os.path.join(img_path, random.choice(img_paths))) imgs.append((img, path))f, ax = plt.subplots(4, 4, figsize=(12,12))for i, img in enumerate(imgs[:16]): ax[i//4, i%4].imshow(img[0]) ax[i//4, i%4].axis('off') ax[i//4, i%4].set_title('label: %s' % img[1])plt.show()
2.3.2 导入数据集的定义实现
In [2]
#数据集的定义class Dataset(paddle.io.Dataset): """ 步骤一:继承paddle.io.Dataset类 """ def __init__(self, transforms: Callable, mode: str ='train'): """ 步骤二:实现构造函数,定义数据读取方式 """ super(Dataset, self).__init__() self.mode = mode self.transforms = transforms train_image_dir = config_parameters['train_image_dir'] eval_image_dir = config_parameters['eval_image_dir'] train_data_folder = paddle.vision.DatasetFolder(train_image_dir) eval_data_folder = paddle.vision.DatasetFolder(eval_image_dir) if self.mode == 'train': self.data = train_data_folder elif self.mode == 'eval': self.data = eval_data_folder def __getitem__(self, index): """ 步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签) """ data = np.array(self.data[index][0]).astype('float32') data = self.transforms(data) label = np.array([self.data[index][1]]).astype('int64') return data, label def __len__(self): """ 步骤四:实现__len__方法,返回数据集总数目 """ return len(self.data)
In [3]
from paddle.vision import transforms as T#数据增强transform_train =T.Compose([T.Resize((256,256)), #T.RandomVerticalFlip(10), #T.RandomHorizontalFlip(10), T.RandomRotation(10), T.Transpose(), T.Normalize(mean=[0, 0, 0], # 像素值归一化 std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差 std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel] ])transform_eval =T.Compose([ T.Resize((256,256)), T.Transpose(), T.Normalize(mean=[0, 0, 0], # 像素值归一化 std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差 std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel] ])
2.3.3 实例化数据集类
根据所使用的数据集需求实例化数据集类,并查看总样本量。
In [4]
train_dataset =Dataset(mode='train',transforms=transform_train)eval_dataset =Dataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CUDAPlace(0), batch_size=32, shuffle=True, #num_workers=2, #use_shared_memory=True )eval_loader = paddle.io.DataLoader (eval_dataset, places=paddle.CUDAPlace(0), batch_size=32, #num_workers=2, #use_shared_memory=True )print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))
训练集样本量: 45,验证集样本量: 12
③ 模型选择和开发
3.1 对比网络构建
本次我们选取了经典的卷积神经网络resnet50,vgg19,mobilenet_v2来进行实验比较。
In [ ]
network = paddle.vision.models.vgg19(num_classes=16)#模型封装model = paddle.Model(network)#模型可视化model.summary((-1, 3,256 , 256))
In [ ]
network = paddle.vision.models.resnet50(num_classes=16)#模型封装model2 = paddle.Model(network)#模型可视化model2.summary((-1, 3,256 , 256))
3.2 对比网络训练
In [ ]
#优化器选择class SaveBestModel(paddle.callbacks.Callback): def __init__(self, target=0.5, path='work/best_model', verbose=0): self.target = target self.epoch = None self.path = path def on_epoch_end(self, epoch, logs=None): self.epoch = epoch def on_eval_end(self, logs=None): if logs.get('acc') > self.target: self.target = logs.get('acc') self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/vgg19')callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model')callbacks = [callback_visualdl, callback_savebestmodel]base_lr = config_parameters['lr']epochs = config_parameters['epochs']def make_optimizer(parameters=None): momentum = 0.9 learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False) weight_decay=paddle.regularizer.L2Decay(0.0001) optimizer = paddle.optimizer.Momentum( learning_rate=learning_rate, momentum=momentum, weight_decay=weight_decay, parameters=parameters) return optimizeroptimizer = make_optimizer(model.parameters())model.prepare(optimizer, paddle.nn.CrossEntropyLoss(), paddle.metric.Accuracy())model.fit(train_loader, eval_loader, epochs=100, batch_size=1, # 是否打乱样本集 callbacks=callbacks, verbose=1) # 日志展示格式
3.3 Simam注意力机制
3.3.1 simam_module模块的介绍
一个simam_module块可以被看作是一个计算单元,旨在增强卷积神经网络中特征的表达能力。它可以将任何中间特征张量作为输入并通过转换输出了与张量具有相同size同时具有增强表征的作用。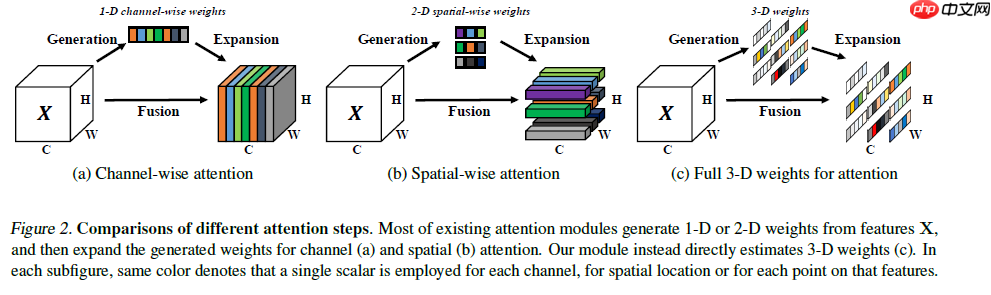
3.3.2 Simam注意力机制推导公式

In [5]
import paddlefrom paddle.fluid.layers.nn import transposeimport paddle.nn as nnimport mathimport paddle.nn.functional as Fclass simam_module(nn.Layer): def __init__(self, channels, e_lambda = 1e-4): super(simam_module, self).__init__() self.activaton = nn.Sigmoid() self.e_lambda = e_lambda def __repr__(self): s = self.__class__.__name__ + '(' s += ('lambda=%f)' % self.e_lambda) return s @staticmethod def get_module_name(): return "simam" def forward(self, x): b, c, h, w = x.shape n = w * h - 1 x_minus_mu_square = (x - x.mean(axis=[2,3], keepdim=True)).pow(2) y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(axis=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5 return x * self.activaton(y)if __name__ == '__main__': x = paddle.randn(shape=[1, 16, 64, 128]) # b, c, h, w simam = simam_module(16) y = simam(x) print(y.shape)
3.3.3 注意力多尺度特征融合卷积神经网络的搭建
In [6]
import paddle.nn.functional as F# 构建模型(Inception层)class Inception(paddle.nn.Layer): def __init__(self, in_channels, c1, c2, c3, c4): super(Inception, self).__init__() # 路线1,卷积核1x1 self.route1x1_1 = paddle.nn.Conv2D(in_channels, c1, kernel_size=1) # 路线2,卷积层1x1、卷积层3x3 self.route1x1_2 = paddle.nn.Conv2D(in_channels, c2[0], kernel_size=1) self.route3x3_2 = paddle.nn.Conv2D(c2[0], c2[1], kernel_size=3, padding=1) # 路线3,卷积层1x1、卷积层5x5 self.route1x1_3 = paddle.nn.Conv2D(in_channels, c3[0], kernel_size=1) self.route5x5_3 = paddle.nn.Conv2D(c3[0], c3[1], kernel_size=5, padding=2) # 路线4,池化层3x3、卷积层1x1 self.route3x3_4 = paddle.nn.MaxPool2D(kernel_size=3, stride=1, padding=1) self.route1x1_4 = paddle.nn.Conv2D(in_channels, c4, kernel_size=1) def forward(self, x): route1 = F.relu(self.route1x1_1(x)) route2 = F.relu(self.route3x3_2(F.relu(self.route1x1_2(x)))) route3 = F.relu(self.route5x5_3(F.relu(self.route1x1_3(x)))) route4 = F.relu(self.route1x1_4(self.route3x3_4(x))) out = [route1, route2, route3, route4] return paddle.concat(out, axis=1) # 在通道维度(axis=1)上进行连接# 构建 BasicConv2d 层def BasicConv2d(in_channels, out_channels, kernel, stride=1, padding=0): layer = paddle.nn.Sequential( paddle.nn.Conv2D(in_channels, out_channels, kernel, stride, padding), paddle.nn.BatchNorm2D(out_channels, epsilon=1e-3), paddle.nn.ReLU()) return layer# 搭建网络class TowerNet(paddle.nn.Layer): def __init__(self, in_channel, num_classes): super(TowerNet, self).__init__() self.b1 = paddle.nn.Sequential( BasicConv2d(in_channel, out_channels=64, kernel=3, stride=2, padding=1), paddle.nn.MaxPool2D(2, 2)) self.b2 = paddle.nn.Sequential( BasicConv2d(64, 128, kernel=3, padding=1), paddle.nn.MaxPool2D(2, 2)) self.b3 = paddle.nn.Sequential( BasicConv2d(128, 256, kernel=3, padding=1), paddle.nn.MaxPool2D(2, 2), simam_module(256)) self.b4 = paddle.nn.Sequential( BasicConv2d(256, 256, kernel=3, padding=1), paddle.nn.MaxPool2D(2, 2), simam_module(256)) self.b5 = paddle.nn.Sequential( Inception(256, 64, (64, 128), (16, 32), 32), paddle.nn.MaxPool2D(2, 2), simam_module(256), Inception(256, 64, (64, 128), (16, 32), 32), paddle.nn.MaxPool2D(2, 2), simam_module(256), Inception(256, 64, (64, 128), (16, 32), 32)) self.AvgPool2D=paddle.nn.AvgPool2D(2) self.flatten=paddle.nn.Flatten() self.b6 = paddle.nn.Linear(256, num_classes) def forward(self, x): x = self.b1(x) x = self.b2(x) x = self.b3(x) x = self.b4(x) x = self.b5(x) x = self.AvgPool2D(x) x = self.flatten(x) x = self.b6(x) return x
In [7]
model = paddle.Model(TowerNet(3, config_parameters['class_dim']))model.summary((-1, 3, 256, 256))
④改进模型的训练和优化器的选择
In [8]
#优化器选择class SaveBestModel(paddle.callbacks.Callback): def __init__(self, target=0.5, path='work/best_model', verbose=0): self.target = target self.epoch = None self.path = path def on_epoch_end(self, epoch, logs=None): self.epoch = epoch def on_eval_end(self, logs=None): if logs.get('acc') > self.target: self.target = logs.get('acc') self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/CA_Inception_Net')callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model')callbacks = [callback_visualdl, callback_savebestmodel]base_lr = config_parameters['lr']epochs = config_parameters['epochs']def make_optimizer(parameters=None): momentum = 0.9 learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False) weight_decay=paddle.regularizer.L2Decay(0.0002) optimizer = paddle.optimizer.Momentum( learning_rate=learning_rate, momentum=momentum, weight_decay=weight_decay, parameters=parameters) return optimizeroptimizer = make_optimizer(model.parameters())
In [9]
model.prepare(optimizer, paddle.nn.CrossEntropyLoss(), paddle.metric.Accuracy())
In [10]
model.fit(train_loader, eval_loader, epochs=100, batch_size=1, # 是否打乱样本集 callbacks=callbacks, verbose=1) # 日志展示格式
⑤模型训练效果展示
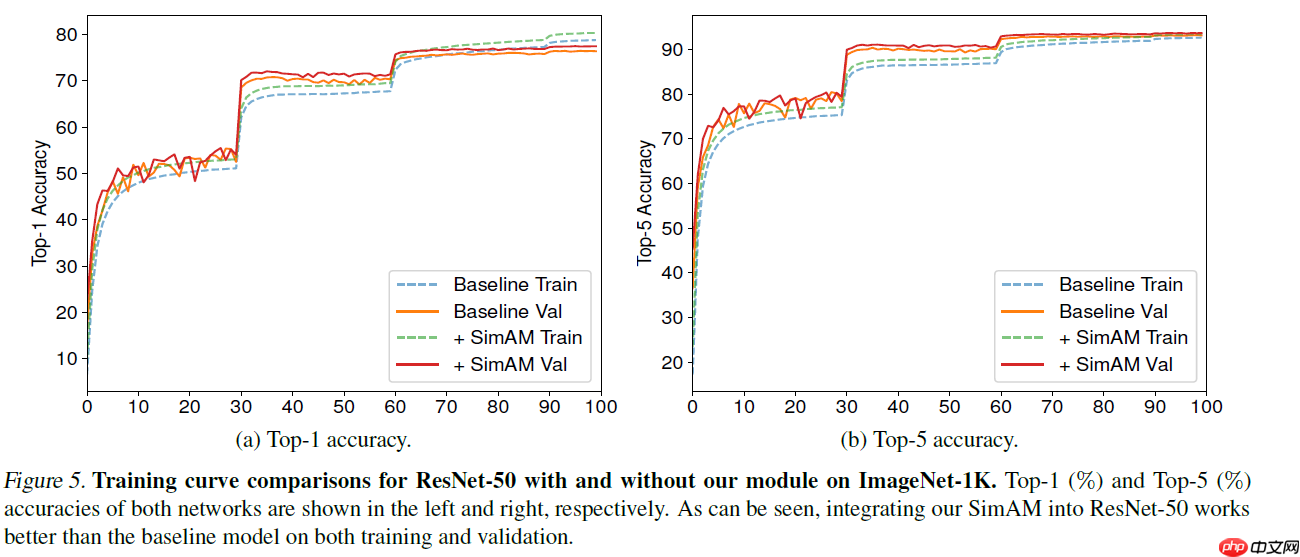
在增加了simam_module模块的注意力机制后,性能有了较大幅度的提升,模型也更鲁棒(蓝色曲线为添加SimAM注意力机制后)。
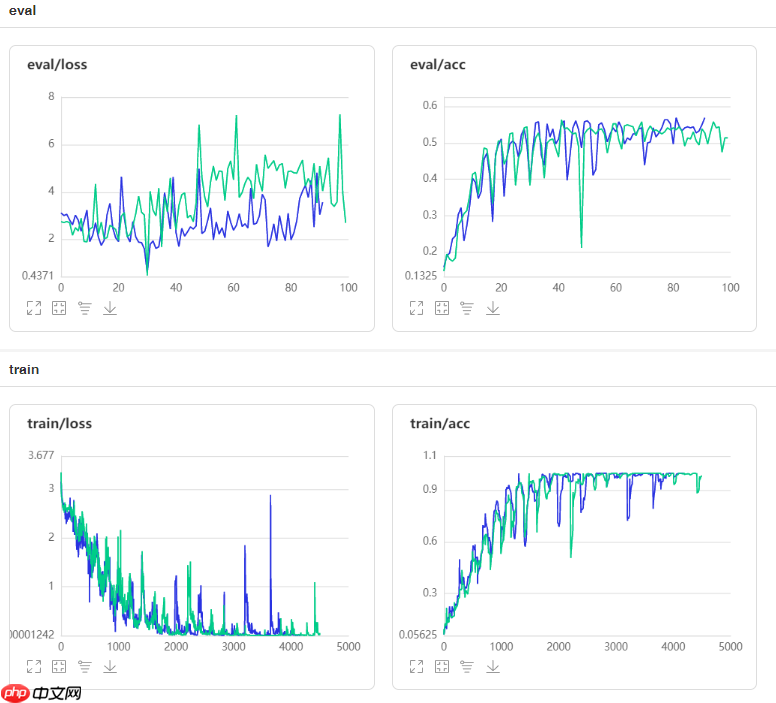
⑥项目总结
1.受启发于人脑注意力机制,本文提出一种3D注意力模块并设计了一种能量函数用于计算注意力权值;2.该文献推导出了能量函数的解析解加速了注意力权值的计算并得到了一种轻量型注意力模块;3.将所提注意力嵌入到现有ConvNet中在不同任务上进行了灵活性与有效性的验证。 
以上就是SimAM:无参数Attention!助力分类/检测/分割涨点!的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/68209.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫