本文围绕Transformer展开,先介绍其相较CNN与RNN的优势,如并行计算、自注意力机制等。接着讲解构建Transformer的五个零件及算法,包括嵌入、位置编码、掩码等。还给出了数据预处理、各组件实现及组装训练的代码,展示了结果,提及进步与不足,指出位置编码处理欠佳。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Abstract(摘要)
在transformer出现之前,主要的序列转导模型是基于复杂的递归或卷积神经网络,其中包括一个编码器和一个解码器。性能最好的模型也通过一个注意力机制来连接编码器和解码器。然而,好景不长,谷歌的大佬们提出了transformer,一来可以进行并行计算,提高训练推理速度;二来可以加入了自注意力机制,可以更好的关注序列间的时间维度上的关系。transformer同时兼备了CNN与RNN的优点,既实现了参数局部共享,降低了参数量(CNN最大的特点),同时又可以关注序列中的任意两个单词间的依赖关系,彻底解决了RNN对于长期依赖关系的无力感,真可谓万物皆可联。但很遗憾的是,谷歌大佬们的这篇attention is all you need写的太过晦涩,很难读懂,因此笔者查阅了各种资料,才将transformer略微搞懂。下面让我们开始transformer的学习吧~
Introduction(介绍)
transformer摒弃了原先的CNN与RNN的架构,仅仅使用了全连接层与自注意力机制,因此训练速度很快。同时在encoder部分,我们对src进行并行计算,与使用RNN相比,速度也有了大大的提升。那么,要搭建一个我们自己的transformer,需要五个零件,分别是
Embedding the inputsThe Positional EncodingsCreating MasksThe Multi-Head Attention layerThe Feed-Forward layer
下面让我们一步步地开始学习吧
Algorithm(算法)
1)Embedding
嵌入单词目前已成为主流的做法,嵌入向量蕴含的信息量远比one-hot向量大的多。而且实作也很简单,直接调用API即可。当每个单词输入网络时,此代码将执行查找并检索其嵌入向量。 然后,这些向量将被模型作为参数学习,并随梯度下降的每次迭代进行调整。
2)position-encoding
刚才的embedding是为了让机器理解单词的意思,这一步是为了让机器理解各个单词的位置。当然,其实这一步本论文处理得不是很好,只是使用了三角函数进行了映射,当然这只是权宜之计,下面让我们看看作者的做法。
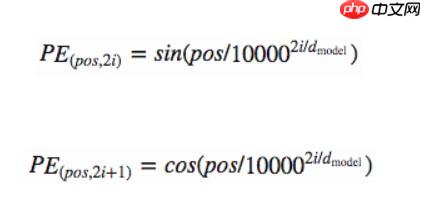
这是该trick的示意图,行为pos,列为i
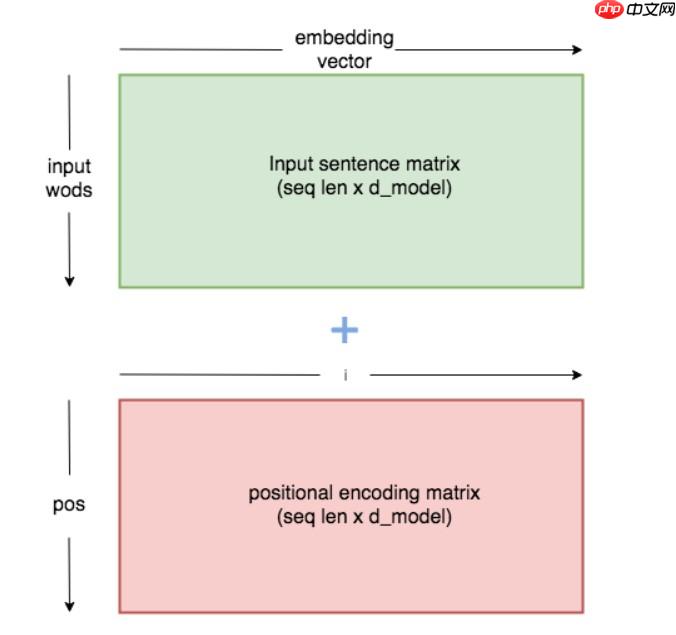
这就是本文的位置编码,虽然直观感觉这很离谱,但实作起来效果还行.下面是大佬画出的示意图,显示了大佬对于该编码方式的不解。当然具体实现见下面的Implement部分。
算出位置编码之后,我们就可以将位置编码与变换后的嵌入向量相加。
至于这里为什么要将嵌入向量进行变换,除以根号d_k,有大佬认为这是一个经验trick。简单的说就是原本的嵌入向量的值偏小,而位置编码的值可以视为[-1,1],如果带入d_k的值,除以根号d_k,位置编码的范围可以缩小为[-0.307,0.307],那么相加后可以缓解嵌入向量受到的影响。
详情大家可以看一下大佬的原话知乎大佬
3)create our mask
说到掩码(mask),我们就不得不提一下注意力机制了,所谓掩码,即遮掩住部分信息,在本文中,我们在encoder部分需要将填充的pad部分进行遮掩,毕竟学习了大半天,总不能让机器只关注pad吧,那也太离谱了。而在实际运算中,因为要保证矩阵的一致性,我们需要加入pad,因此使用了掩码这个折中的方法。但是,在decoder部分,我们不止需要对pad进行遮掩,我们还要遮住机器的眼睛,不能让机器在生成的时候看到之后的单词。举个栗子,就好比我们不能在考试的时候一边让考生看答案,一边考试吧,肯定要把答案藏起来丫。在这里也是同样的意思,只不过操作有点骚,使用了下三角矩阵,行和列都是句子的长度sen_len,笔者当时也不能理解,直到。。。这里要感谢闫哥哥对我的指导,即在训练过程中,机器是一次性预测出所有句子的,因此没有时间步上的差距。矩阵的每一行只负责一步的预测结果,当然这里肯定是异步操作的。矩阵的列,代表了机器对一个序列的第一位的预测,第一列即对序列第一位的预测,第二列即对序列第二位的预测。
下面是掩码的一个栗子

4)MutiHeadAttention
这里到了本项目最核心的地方,自注意力机制。要理解多头注意力,我们首先要理解最初的Scaled Dot-Product Attention,而要理解Scaled Dot-Product Attention,我们首先通俗地了解一下,到底什么是注意力,什么是自注意力。举个栗子,假设我们进行经典的文本翻译,src为“我是中国人”,trg为“I am Chinese”。
一般情况下的注意力:机器会关注我与I的关系,中国人与Chinese的关系。自注意力:机器会关注我与中国人的关系,I与Chinese的关系。
好,了解了自注意力的通俗含义,我们再来理解自注意力的计算过程。
 Levity
Levity
AI帮你自动化日常任务
 206 查看详情
206 查看详情 
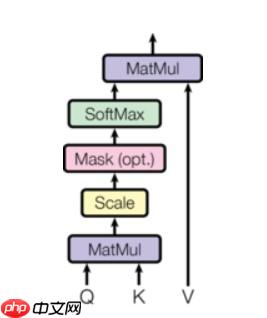
首先,我们将嵌入向量与三个矩阵进行点乘,得到query,key,value三个新向量,这里query是待匹配的向量,key是被匹配的向量,然后将query与key进行点乘,得到它们的匹配程度,然后将是pad这个token的地方进行遮掩,根据我们先前得到的掩码,之后使用softmax进行大小的缩放,最后将结果与value进行点乘,即机器到底要注意哪些内容。注意,这里都是矩阵的点乘运算,实际上发生的过程解决了RNN的一大瓶颈,q0与k0,k1,k2…进行相乘,在将q1与k0,k1,k2…进行相乘,这个操作的意义太伟大了,它代表每两个单词之间都会计算他们的关系,即使距离再遥远,它们的相对距离也只是n(1),堪称触手可及。
这是query,key,value向量计算的示意图

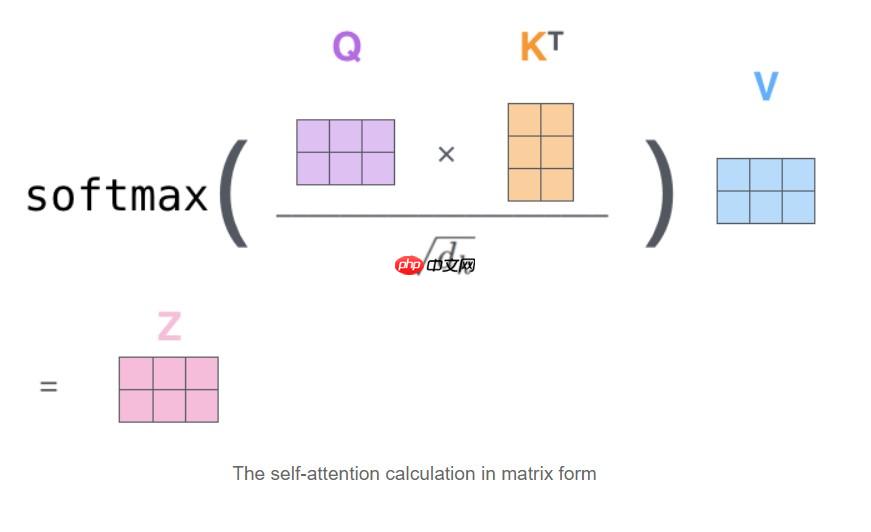
下面再讲讲自注意力的进阶版本,多头注意力,这里对q,k,v三个向量进行切分,分为heads份,每一份都去做刚才的attention计算,最后再将它们进行拼接,这极大程度上提高了机器注意力的效果。

这是整个多头注意力的流程示意图
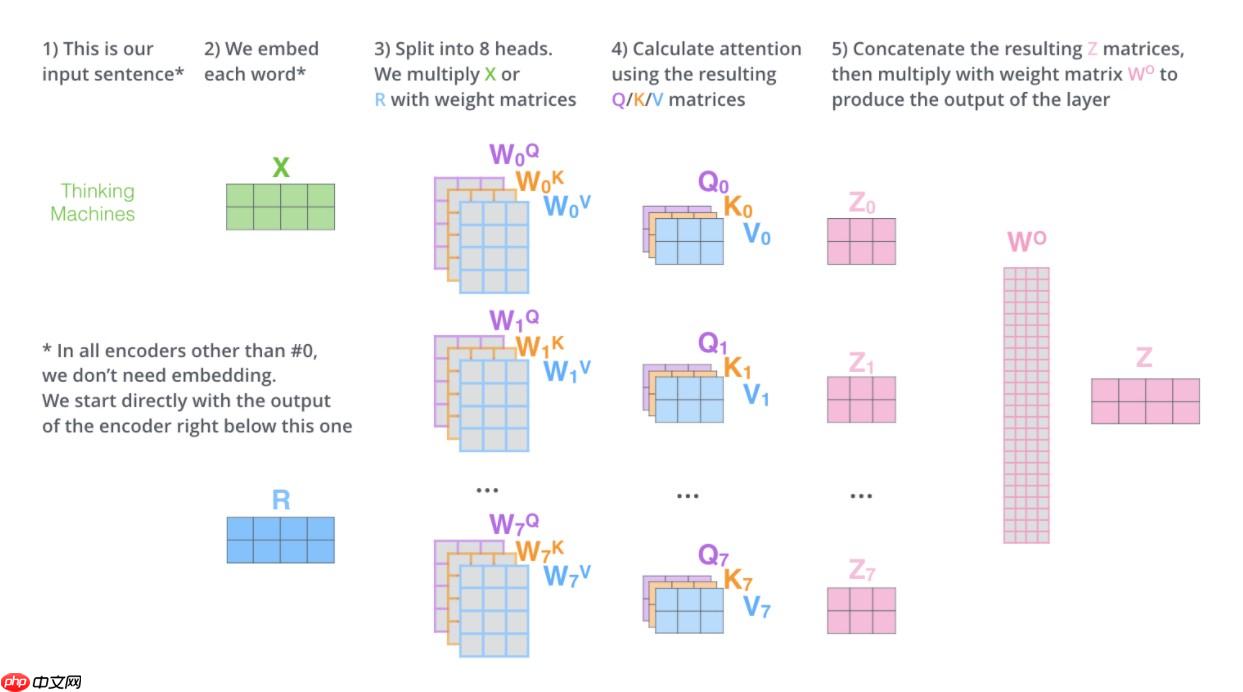
看到这里,该为你自己祝贺了,五个零件的讲解还剩最后一个非常简单的操作,让我们开始吧~
5)FeedForward
这个零件很简单,就是将输入经过一个全连接层,在经过一个ReLU激活,再通过一个全连接层,结束了~~~
组装
零件制作完了,下面就是组装了,具体大家可以看下面的实现
EncoderLayer与DecoderLayerEncoder与DecoderTransformer
transformer的整体架构

Implement(实作)
数据预处理
In [1]
import numpy as npimport re#将无效字符去掉with open("data/data86810/human_chat.txt","r",encoding="utf-8") as f: data=f.read().replace("Human 1"," ").replace("Human 2"," ").replace("."," ").replace("*"," ").replace("@"," ").replace("^"," ").replace("&"," ").replace("!"," ").replace("#"," ").replace("$"," ").replace("?"," ").replace(";"," ").replace(":"," ").replace(","," ").replace('"',' ').replace("%"," ").replace("/"," ").replace("@"," ").replace("("," ").replace(")"," ").replace("'"," ").lower()data=list(data.split("n"))#print(len(data))lst=[]#分割出单词,连成序列for obj in data: sen=list(obj.split(" ")) lst.append(sen)#print(len(lst))#将字符连接起来,制作字典string=" ".join(data)#将特殊字符添入string1="pad sos eos"#合并字符串string=string+string1#string=string.replace(''," ")#使用正则分割,防止有多个空格words=re.split(" +",string)#使用集合,防止单词重复words=list(set(words))print(len(words))#获取字典dic=dict([(word,i) for i,word in enumerate(words)])#存储对话序列index_data=[]#每句话的长度,短句添加"pad",长句切至30sen_len=30for i,sen in enumerate(lst): #token映射至index,并防止出现空字符 sen=[dic[word] for word in sen if word!=''] #在开头添加"sos" sen.insert(0,dic["sos"]) while len(sen)<sen_len-1: #填充"pad",防止长度不够 sen.append(dic["pad"]) #切取sen_len-1个词 sen=sen[:sen_len-1] #末尾添加"eos" sen.append(dic["eos"]) #将ask与answer分割 if i%2==0: one=[] one.append(sen) else: one.append(sen) index_data.append(one)#print(len(index_data))index_data=np.array(index_data)print(index_data.shape)print(index_data[0])#挑一个看看效果ask,ans=index_data[3]#将index序列转化为字符串ask_str=[words[i] for i in ask]ans_str=[words[i] for i in ans]print(ask_str)print(ans_str)#print(dic)
定义超参
In [2]
#单词嵌入的维度d_model=512#多头自注意力的个数heads=8#batch大小batch_size=128#encoder或decoder有多少层N=8#词典大小vocab_size=len(dic)dropout=0.1
定义数据读取器
In [3]
import paddlefrom paddle.io import Dataset,DataLoaderimport paddle.nn as nnimport randomclass Mydataset(Dataset): def __init__(self,index_data,dic): super(Mydataset, self).__init__() self.index_data=index_data self.dic=dic def __getitem__(self,index): ask_data,ans_data=self.index_data[index] #ask部分倒序,引入更多短期依赖关系 ask_data,ans_data=ask_data[:][::-1],ans_data return ask_data,ans_data def __len__(self): return self.index_data.shape[0]#实例化读取器dataset=Mydataset(index_data,dic)#封装为迭代器dataloader=DataLoader(dataset,batch_size=batch_size,shuffle=True,drop_last=True)#看看效果ask,ans=next(dataloader())print(ask)
Embedding
In [4]
import paddleimport paddle.nn as nn#定义嵌入层class Embedder(nn.Layer): def __init__(self,vocab_size,d_model): super(Embedder, self).__init__() self.emb=nn.Embedding(vocab_size,d_model) def forward(self,x): x=paddle.to_tensor(x,dtype="int64") return self.emb(x)
PositionalEncoder
In [5]
import mathclass PositionalEncoder(nn.Layer): def __init__(self,d_model,max_seq_len=80): #d_model为嵌入维度 super(PositionalEncoder, self).__init__() self.d_model=d_model #保持位置编码与嵌入向量的形状可以相同 #嵌入向量[batch,sen_len,d_model] #位置编码[max_seq_len,d_model] #下面经过调整与广播使两者形状相同 position=paddle.zeros([max_seq_len,d_model]) #行为pos for pos in range(max_seq_len): #列为i for i in range(d_model,2): #公式 position[pos,i]=paddle.sin(pos/(10000**(2*i/d_model))) position[pos,i+1]=paddle.cos(pos/(10000**((2*i+1)/d_model))) self.position=position def forward(self,x): #对嵌入向量进行放缩,原因在前面的理论部分已讲 x=x*math.sqrt(self.d_model) seq_len=x.shape[1] #调整大小 x=x+self.position[:seq_len,:] return xx=paddle.randn([128,30,512])# model=PositionalEncoder(512)# print(model(x))
Create mask
In [6]
def create_mask(src,trg): #得到pad的token pad=dic["pad"] #得到对应的布尔矩阵 input_mask=src!=pad #True->1,False->0 input_mask=paddle.cast(paddle.to_tensor(input_mask),dtype="int64") #得到trg的布尔矩阵 trg_mask=trg!=pad trg_mask=paddle.cast(paddle.to_tensor(trg_mask),dtype="int64") #初始化掩码矩阵(下三角) nopeak_mask=paddle.ones(trg.shape) for i in range(trg.shape[0]): for j in range(trg.shape[1]): #下三角 nopeak_mask[i,j]=(i>=j) nopeak_mask=paddle.cast(paddle.to_tensor(trg_mask),dtype="int64") #将两个掩码矩阵相加 trg_mask=trg_mask+nopeak_mask return input_mask,trg_maskask_mask,ans_mask=create_mask(ask,ans)print(ans_mask)
计算Attention
In [7]
import paddle.nn.functional as Fdef attention(q,k,v,d_k,mask=None,dropout=dropout): #q:query,k:key,v:value,d_k:d_model//heads #得到q与k的相似程度并做放缩 #print(q.shape,k.shape) similarity=paddle.matmul(q.transpose([0,3,1,2]),k.transpose([0,3,2,1]))/math.sqrt(d_k) similarity=similarity.transpose([0,2,3,1]) if mask is not None: #广播 mask=mask.unsqueeze(-1).unsqueeze(-1) #print(mask.shape) #print(similarity.shape) mask=paddle.broadcast_to(mask,similarity.shape) mask=paddle.cast(mask,dtype="int64") #得到布尔矩阵 zero_one=mask==0 #调整无需注意的地方为负无穷 similarity[zero_one.numpy()]=-1e9 #对矩阵值进行softmax,使sum为1 similarity=F.softmax(similarity) drop=nn.Dropout(dropout) similarity=drop(similarity) #求出对每个单词注意的程度 atten=paddle.matmul(similarity.transpose([0,3,1,2]),v.transpose([0,3,1,2])) return attenq=k=v=paddle.randn([batch_size,sen_len,8,64])print(attention(q,k,v,8,ask_mask).shape)
MutiHeadAttention
In [8]
class MutiHeadAttention(nn.Layer): def __init__(self,d_model,heads,dropout=dropout): super(MutiHeadAttention, self).__init__() self.d_model=d_model self.h=heads self.d_k=d_model//heads #线性变换 self.q_linear=nn.Linear(d_model,d_model) self.k_linear=nn.Linear(d_model,d_model) self.v_linear=nn.Linear(d_model,d_model) self.dropout=dropout self.out=nn.Linear(d_model,d_model) def forward(self,q,k,v,mask): batch_size=q.shape[0] #求得query,key,value向量,并分组给各个头注意力 self.q=self.q_linear(q).reshape([batch_size,-1,self.h,self.d_k]) self.k=self.k_linear(k).reshape([batch_size,-1,self.h,self.d_k]) self.v=self.v_linear(v).reshape([batch_size,-1,self.h,self.d_k]) #获取注意的程度 atten=attention(self.q,self.k,self.v,self.d_k,mask,self.dropout) atten=atten.reshape([batch_size,-1,self.d_model]) out=self.out(atten) return out# model=MutiHeadAttention(512,8,0.1)# x=paddle.randn([batch_size,sen_len,512])# y=model(x,x,x,ask_mask)# print(y.shape)
FeedForward
In [9]
class FeedForward(nn.Layer): def __init__(self,d_model,d_ff=2048,dropout=dropout): super(FeedForward, self).__init__() #两个全连接,一个ReLU self.model=nn.Sequential( nn.Linear(d_model,d_ff), nn.ReLU(), nn.Dropout(dropout), nn.Linear(d_ff,d_model) ) def forward(self,x): return self.model(x)# model=FeedForward(512,2048)# x=paddle.randn([batch_size,sen_len,512])# y=model(x)# print(y.shape)
组装
EncoderLayer
In [10]
class EncoderLayer(nn.Layer): def __init__(self,d_model,heads,dropout=dropout): super(EncoderLayer, self).__init__() #归一化层 self.norm1=nn.LayerNorm(d_model) self.norm2=nn.LayerNorm(d_model) #多头自注意力层 self.attention=MutiHeadAttention(d_model,heads,dropout) #前馈层 self.feedforward=FeedForward(d_model,dropout=dropout) self.drop1=nn.Dropout(dropout) self.drop2=nn.Dropout(dropout) def forward(self,x,mask): y=self.norm1(x) #残差块,防止梯度消失 x=x+self.drop1(self.attention(y,y,y,mask)) y=self.norm2(x) #残差块,防止梯度消失 x=x+self.drop2(self.feedforward(y)) return x# model=EncoderLayer(d_model,heads)# x=paddle.randn([batch_size,sen_len,d_model])# y=model(x,ask_mask)# print(y.shape)
DecoderLayer
In [11]
class DecoderLayer(nn.Layer): def __init__(self,d_model,heads,dropout=dropout): super(DecoderLayer, self).__init__() #归一化层 self.norm1=nn.LayerNorm(d_model) self.norm2=nn.LayerNorm(d_model) self.norm3=nn.LayerNorm(d_model) #掩码自注意力层与前馈层 self.attention1=MutiHeadAttention(d_model,heads,dropout) self.attention2=MutiHeadAttention(d_model,heads,dropout) self.feedforward=FeedForward(d_model,dropout=dropout) self.drop1=nn.Dropout(dropout) self.drop2=nn.Dropout(dropout) self.drop3=nn.Dropout(dropout) def forward(self,x,encoder_output,src_mask,trg_mask): #x=paddle.broadcast_to(x,encoder_output.shape) y=self.norm1(x) #残差块 #这里为多头注意力层 x=x+self.drop1(self.attention1(y,y,y,trg_mask)) y=self.norm2(x) #这里为掩码多头注意力,同时将encoder的output输入 x=x+self.drop2(self.attention2(y,encoder_output,encoder_output,src_mask)) y=self.norm3(x) #前馈 x=x+self.drop3(self.feedforward(y)) return x# model=DecoderLayer(d_model,heads)# x=paddle.randn([batch_size,sen_len,d_model])# e_output=paddle.randn([batch_size,sen_len,d_model])# y=model(x,e_output,ask_mask,ans_mask)# print(y.shape)
定义拷贝函数
In [12]
import copydef clone_module(module,N): return nn.LayerList([copy.deepcopy(module) for i in range(N)])# module=EncoderLayer(d_model,heads)# print(clone_module(module,3))
Encoder
In [13]
class Encoder(nn.Layer): def __init__(self,vocab_size,d_model,heads,N): super(Encoder, self).__init__() #总体的层数 self.N=N self.emb=Embedder(vocab_size,d_model) #位置编码层 self.posi_encoder=PositionalEncoder(d_model) #注意力加前馈多层重叠 self.layers=clone_module(EncoderLayer(d_model,heads),N) self.norm=nn.LayerNorm(d_model) def forward(self,src,mask): x=self.emb(src) x=self.posi_encoder(x) for i in range(self.N): x=self.layers[i](x,mask) x=self.norm(x) return x# model=Encoder(vocab_size,d_model,heads,N)# x=paddle.randn([batch_size,sen_len])# y=model(x.astype("int64"),ask_mask.astype("int64"))# print(y.shape)
Decoder
In [14]
class Decoder(nn.Layer): def __init__(self,vocab_size,d_model,heads,N): super(Decoder, self).__init__() self.N=N self.emb=Embedder(vocab_size,d_model) self.posi_encoder=PositionalEncoder(d_model) self.layers=clone_module(DecoderLayer(d_model,heads),N) self.norm=nn.LayerNorm(d_model) def forward(self,trg,encoder_output,src_mask,trg_mask): x=self.emb(trg) x=self.posi_encoder(x) #调整数据类型 x,encoder_output=x.astype("float32"),encoder_output.astype("float32") for i in range(self.N): x=self.layers[i](x,encoder_output,src_mask,trg_mask) x=self.norm(x) return x# model=Decoder(vocab_size,d_model,heads,N)# x=paddle.randint(0,vocab_size,[batch_size,sen_len])# en_output=paddle.randn([batch_size,sen_len,d_model])# y=model(x.astype("int64"),en_output,ask_mask,ans_mask)# print(y.shape)
Transformer
In [15]
class Transformer(nn.Layer): def __init__(self,vocab_size,d_model,heads,N): super(Transformer, self).__init__() #初始化 nn.initializer.set_global_initializer(nn.initializer.XavierNormal(),nn.initializer.Constant(0.)) #编码器 self.encoder=Encoder(vocab_size,d_model,heads,N) #解码器 self.decoder=Decoder(vocab_size,d_model,heads,N) #全连接 self.out=nn.Linear(d_model,vocab_size) def forward(self,src,trg,src_mask,trg_mask): encoder_output=self.encoder(src,src_mask) decoder_output=self.decoder(trg,encoder_output,src_mask,trg_mask) output=self.out(decoder_output) return outputmodel=Transformer(vocab_size,d_model,heads,N)y=model(ask,ans,ask_mask,ans_mask)print(y.shape)
In [16]
def trans(out): out=F.softmax(out,axis=-1) seq=out.argmax(axis=-1) sen=seq[100,:] sen=[words[i] for i in sen] sen=" ".join(sen) return sen
开启训练
In [ ]
num_epoch=1000learning_rate=1e-4pad=dic["pad"]model=Transformer(vocab_size,d_model,heads,N)opt=paddle.optimizer.Adam(parameters=model.parameters(),learning_rate=learning_rate,beta2=0.98,epsilon=1e-9)for epoch in range(num_epoch): for i,(src,trg) in enumerate(dataloader()): model.train() #获取掩码 src_mask,trg_mask=create_mask(src,trg) #获取预测值 pred=model(src,trg,src_mask,trg_mask) #展开 trg_=trg.reshape([-1]) #展开 pred_=pred.reshape([-1,pred.shape[-1]]) #求损失,并去除pad的影响 loss=F.cross_entropy(pred_,trg_,ignore_index=pad) opt.clear_grad() loss.backward() opt.step() if i%10==0: print("epoch:%d,i:%d,loss:%f,perlexity:%f"%(epoch,i,loss,math.exp(loss))) print(trans(pred)) #print(answer(model,index_data[random.randint(0,700),0])) if (epoch+1)%2==0: paddle.save(model.state_dict(),"work/transformer.pdparams")
结果展示
In [19]
model=Transformer(vocab_size,d_model,heads,N)state_dict=paddle.load("work/transformer.pdparams")model.load_dict(state_dict)ask,ans=next(dataloader())src_mask,trg_mask=create_mask(ask,ans)pred=model(ask,ans,src_mask,trg_mask)ask_1,ask_2,ask_3=ask[1],ask[10],ask[100]ask_1,ask_2,ask_3=[words[i] for i in ask_1],[words[i] for i in ask_2],[words[i] for i in ask_3]ask_1,ask_2,ask_3=" ".join(ask_1)," ".join(ask_2)," ".join(ask_3)ans_1,ans_2,ans_3=pred[1],pred[10],pred[100]ans_1,ans_2,ans_3=ans_1.argmax(-1),ans_2.argmax(-1),ans_3.argmax(-1)ans_1,ans_2,ans_3=[words[i] for i in ans_1],[words[i] for i in ans_2],[words[i] for i in ans_3]ans_1,ans_2,ans_3=" ".join(ans_1)," ".join(ans_2)," ".join(ans_3)print("Human1:",ask_1)print("Human2:",ans_1)print("##############")print("Human1:",ask_2)print("Human2:",ans_2)print("##############")print("Human1:",ask_3)print("Human2:",ans_3)
Human1: eos pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad here do you did what sosHuman2: sos oh everything jigglypuff ideas to an conversations the fish market disney land and giant robot fighting show haha pad pad pad pad pad pad pad pad pad pad push##############Human1: eos pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad like look saturday your does what sure sosHuman2: sos saturday looks social good impersonate we shoot for regardless in the morning pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad push##############Human1: eos pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad it like you do work of lot a like sounds that sosHuman2: sos well jigglypuff actually innovation pulled college photography but it s really expected pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad pad push
进步与不足与彩蛋
可以看到结果还是喜人的,比起上一期的seq2seq,使用了注意力机制使得模型预测的句子的多样性与规范性有了大大的提升。当然,有时也会出一点小毛病,不停地输出同一个词。经分析,通过加大炼丹的轮数,可以改善这一现象,使其出现的频率降低,或者减少句子的长度。也可以进行算法的进一步改进,通过对时间维度的进一步优化(下期预告:复现李宏毅老师的StepGAN,一个糅合了GAN的神妙,DRL的奥妙,以及自注意力机制的美妙,让我们尽请期待),可以解决这一问题
Disadvantage(缺点)
positional encoder未能解决位置的编码,transformer只关注了单词的含义以及单词间的相互关系,但是对于单词在句子中原本的位置,处理的不是很好,只是用很离谱的三角函数缓解了一下
以上就是『NLG学习』(二)教你搭建自己的Transformer的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/740905.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫