
智能零售结算系统,其目的旨在于利用计算机视觉领域中国的图像识别及目标检测技术,精准地对顾客购买的商品进行智能化、自动化的价格结算。当顾客将自己选购的商品放置在制定区域的时候,一个理想的智能零售结算系统应当能够精准地识别每一个商品,并且能够返回完整地购物清单及顾客应付的实际商品总价格。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于PaddleDetection的智能零售柜商品识别
一、赛题背景
智能零售结算系统,其目的旨在于利用计算机视觉领域中国的图像识别及目标检测技术,精准地对顾客购买的商品进行智能化、自动化的价格结算。当顾客将自己选购的商品放置在制定区域的时候,一个理想的智能零售结算系统应当能够精准地识别每一个商品,并且能够返回完整地购物清单及顾客应付的实际商品总价格。
二、赛题任务
通过PaddleDetection实现智能零售结算系统,其目的旨在于利用计算机视觉领域中国的图像识别及目标检测技术,精准地对顾客购买的商品进行智能化、自动化的价格结算。

三、数据集介绍
本数据集采用VOC格式,符合大多深度学习开发套件对数据集格式的要求,可满足paddlex或PaddleDetection的训练要求。本数据集总数据量为5422张,且所有图片均已标注,共有113类商品。本数据集以对数据集进行划分,其中训练集3796张、验证集1084张、测试集542张。!
四、提交实例
参赛者需要将所有模型检测结果放入一个csv文件中,命名为submission.csv,文件内容格式如下表所示: 每一行为一个待检测图像的信息和结果,其中第一列存储待检测的图像名称(不包含后缀名),第二列存储检测的垂直边框信息,具体边框信息格式为[目标矩形中心点相对横坐标 目标矩形中心点相对纵坐标 目标矩形相对长度比例 目标矩形相对宽度比例](数字间用英文空格隔开),如果有多个垂直边框,用英文的“;”将边框信息进行分离。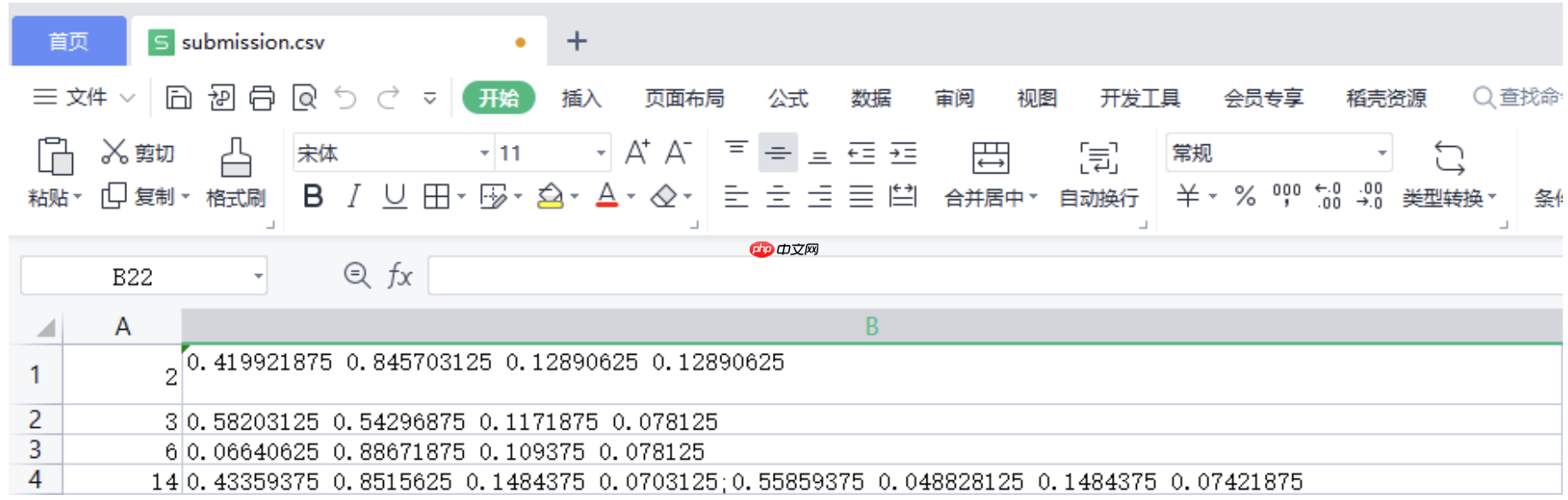
五、数据预处理
竞赛训练数据集中包括两类数据文件,第一类是.jpg格式的图像文件,第二类是xml格式的商品标注信息xml文件,两者通过相同的名称进行关联,名称命名规则可忽略。
下载数据集(训练集和测试集) 数据集已制作上传,可以直接引用。
其次解压数据集 执行以下命令解压数据集,解压之后将压缩包删除,保证项目空间小于100G。否则项目会被终止。
In [ ]
# 1.安装依赖%cd work/!git clone https://gitee.com/PaddlePaddle/PaddleDetection.git -b develop%cd PaddleDetection/
In [ ]
%cd PaddleDetection/!pip install -r requirements.txt# !pip install paddlex
In [4]
# 2.解压数据集!unzip -oq /home/aistudio/data/data91732/VOC.zip -d /home/aistudio/PaddleDetection/dataset/shoping
六、模型训练
1.利用PaddleDetection套件中的faster_rcnn_swin_tiny_fpn_1x_coco模型完成货柜中商品识别任务的训练,首先在https://gitee.com/PaddlePaddle/PaddleDetection.git 里,进行克隆,下载项目。
2.模型介绍: Faster RCNN其实可以分为4个主要内容:
(1)Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
(2)Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
(3)Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
(4)Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。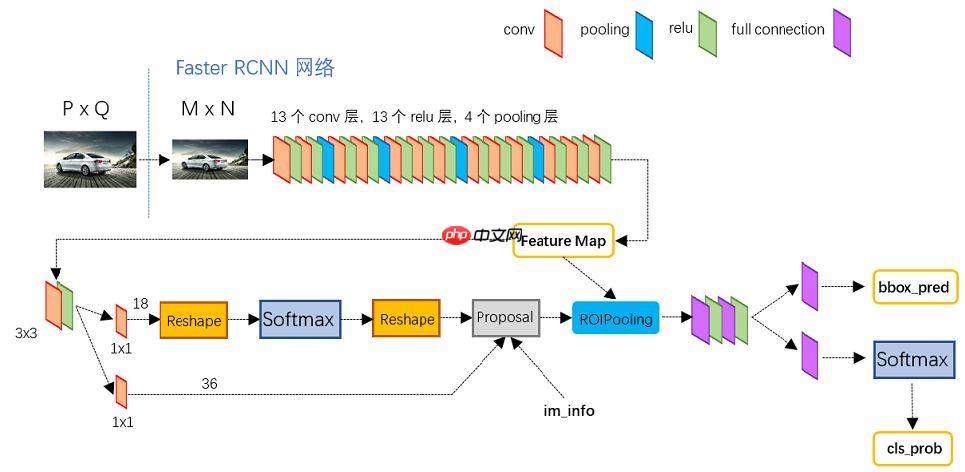 上图展示了模型中的faster_rcnn(backbone为vgg16)的网络结构,可以清晰的看到该网络对于一副任意大小PxQ的图像:
上图展示了模型中的faster_rcnn(backbone为vgg16)的网络结构,可以清晰的看到该网络对于一副任意大小PxQ的图像:
首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3×3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
在本文中所选用的模型是PaddleDetection套件中的faster_rcnn_swin_tiny_fpn_3x_coco模型,backbone选用了Swin_Transformer,其余结构均与上述相同。引入Swin_transformer的优点主要有:将层次性、局部性和平移不变性等先验引入Transformer网络结构设计。
 爱图表
爱图表
AI驱动的智能化图表创作平台
 305 查看详情
305 查看详情 
核心创新:移位窗口(shifted window)设计:
1)自注意的计算在局部的非重叠窗口内进行。这一设计有两方面的好处,一是复杂度从此前的和图像大小的平方关系变成了线性关系,也使得层次化的整体结构设计、局部先验的引入成为可能,二是因为采用非重叠窗口,自注意计算时不同query会共享同样的key集合,从而对硬件友好,更实用。
2)在前后两层的Transformer模块中,非重叠窗口的配置相比前一层做了半个窗口的移位,这样使得上一层中不同窗口的信息进行了交换。 相比于卷积网络以及先驱的自注意骨干网络(Local Relation Net和SASA)中常见的滑动窗(Sliding window)设计,这一新的设计牺牲了部分平移不变性,但是实验发现平移不变性的部分丢失不会降低准确率,甚至以为正则效应效果更好。同时,这一设计对硬件更友好,从而更实用而有希望成为主流。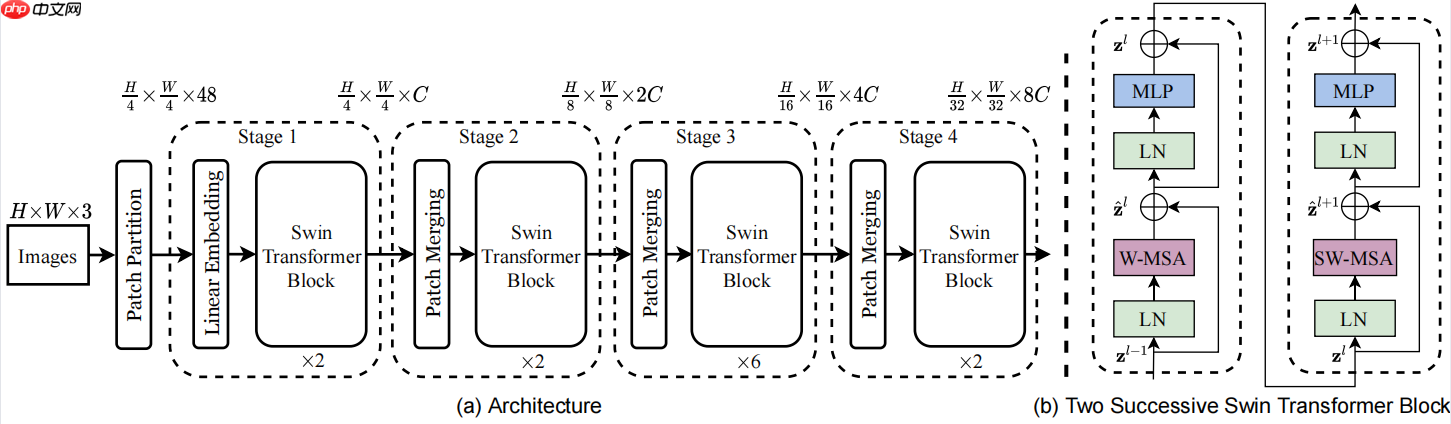 本文中所选用模型所使用的backbone参数解释:
本文中所选用模型所使用的backbone参数解释:
SwinTransformer: embed_dim: 96 depths: [2, 2, 6, 2] num_heads: [3, 6, 12, 24] window_size: 7 ape: false drop_path_rate: 0.1 patch_norm: true out_indices: [0,1,2,3] pretrained: https://paddledet.bj.bcebos.com/models/pretrained/swin_tiny_patch4_window7_224.pdparams
patch_size=4对应的是之前在网络结构中Patch Partition之后下采样多少倍;embed_dim=96对应原网络结构中通过Linear Embedding之后得到的C;depths=(2, 2, 6, 2)对应每一个stage中重复Swin Transformer Block的次数;num_heads=(3, 6, 12, 24)对应的是每一个Swin Transformer Block当中所采用的Multi head的head个数;window_sizw=7对应的是W-MSA或SW-MSA中采用window的大小;mlp_ratio=4是在MLP模块中第一个全连接层将我们的channel翻多少倍;qkv_bias=True代表说在multi-self attention中是否使用偏置;第一个drop_rate是接在我们PatchEmbed后面的;第二个attn_drop_rate对应的是在attention中采用的droprate;第三个drop_path_rate对应的是在每一个swin transformer中采用的droprate。
3.利用PaddleDetection套件中的目标检测模型完成货柜中商品识别任务,修改参数以及数据集路径,这里选用配置文件中的configs/faster_rcnn/faster_rcnn_swin_tiny_fpn_1x_coco.yml对数据进行训练。
(1)修改work/PaddleDetection/configs/datasets/voc.yml中的voc数据集所在路径和num_classes。
metric: VOCmap_type: 11pointnum_classes: 113TrainDataset: !VOCDataSet dataset_dir: dataset/shoping anno_path: train_list.txt label_list: labels.txt data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']EvalDataset: !VOCDataSet dataset_dir: dataset/shoping anno_path: test_list.txt label_list: labels.txt data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']TestDataset: !ImageFolder anno_path: dataset/voc/labels.txt
(2)修改work/PaddleDetection/configs/faster_rcnn/faster_rcnn_swin_tiny_fpn_1x_coco.yml中数据集格式
_BASE_: [ '../datasets/voc.yml', '../runtime.yml', '_base_/optimizer_swin_1x.yml', '_base_/faster_rcnn_swin_tiny_fpn.yml', '_base_/faster_rcnn_swin_reader.yml',]weights: output/faster_rcnn_swin_tiny_fpn_1x_coco/model_final
In [ ]
# 4.选用PaddleDetection中的目标检测模型,修改参数以及数据集路径,这里选用faster_rcnn_swin_tiny_fpn_1x_coco.yml对数据进行训练。%cd ~/PaddleDetection!python ./tools/train.py -c ./configs/faster_rcnn/faster_rcnn_swin_tiny_fpn_1x_coco.yml --use_vdl True --vdl_log_dir ./log --eval
七、模型预测
将预测txt和jpg保存到/home/aistudio/test_a/
In [ ]
# 5.模型预测!python tools/infer.py -c ./configs/faster_rcnn/faster_rcnn_swin_tiny_fpn_1x_coco.yml --infer_dir=/home/aistudio/work/PaddleDetection/dataset/shoping/JPEGImages/ --save_txt=True --output_dir=/home/aistudio/work/PaddleDetection/output_img/
八、模型【评估】
使用训练好的模型在验证集上进行评估,具体代码如下:
In [ ]
# 评估!export CUDA_VISIBLE_DEVICES=0''' -c:指定模型配置文件 -o weights:加载训练好的模型'''!python tools/eval.py -c configs/faster_rcnn/faster_rcnn_swin_tiny_fpn_1x_coco.yml -o weights=output/faster_rcnn_swin_tiny_fpn_1x_coco/best_model.pdparams
九、模型调优
预训练模型:使用预训练模型可以有效提升模型精度,faster_rcnn_swin_tiny_fpn_1x_coco.yml模型提供了在COCO数据集上的预训练模型修改loss:将目标检测中的GIOU loss改为DIOU loss修改lr:调整学习率,这里将学习率调小一半修改lr再训练:当模型不再提升,可以加载训练好的模型,把学习率调整为十分之一,再训练。
十、模型导出
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型。
In [ ]
!export CUDA_VISIBLE_DEVICES=0!python tools/export_model.py -c configs/faster_rcnn/faster_rcnn_swin_tiny_fpn_1x_coco.yml -o weights=output/faster_rcnn_swin_tiny_fpn_1x_coco/best_model.pdparams --output_dir=inference_model
十一、模型推理
在终端输入以下命令进行预测,详细教程请参考Python端预测部署:
In [ ]
!export CUDA_VISIBLE_DEVICES=0''' --model_dir: 上述导出的模型路径 --image_file:需要测试的图片 --image_dir:也可以指定要测试的文件夹路径 --device:运行时的设备,可选择CPU/GPU/XPU,默认为CPU --output_dir:可视化结果保存的根目录,默认为output/'''!python deploy/python/infer.py --model_dir=./inference_model/faster_rcnn_swin_tiny_fpn_1x_coco --image_file=/home/aistudio/PaddleDetection/dataset/shoping/JPEGImages/ori_XYGOC2021042116153323901IK-3_0.jpg --device=GPU
预测模型会导出到inference_model/目录下,包括model.pdmodel、model.pdiparams、model.pdiparams.info和infer_cfg.yml四个文件,分别表示模型的网络结构、模型权重、模型权重名称和模型的配置文件(包括数据预处理参数等)的流程配置文件。
使用用全量数据集上训练的模型,在包含542张图片的验证集上评估,效果如下,mAP(0.5)=99.29%:
十二、数据可视化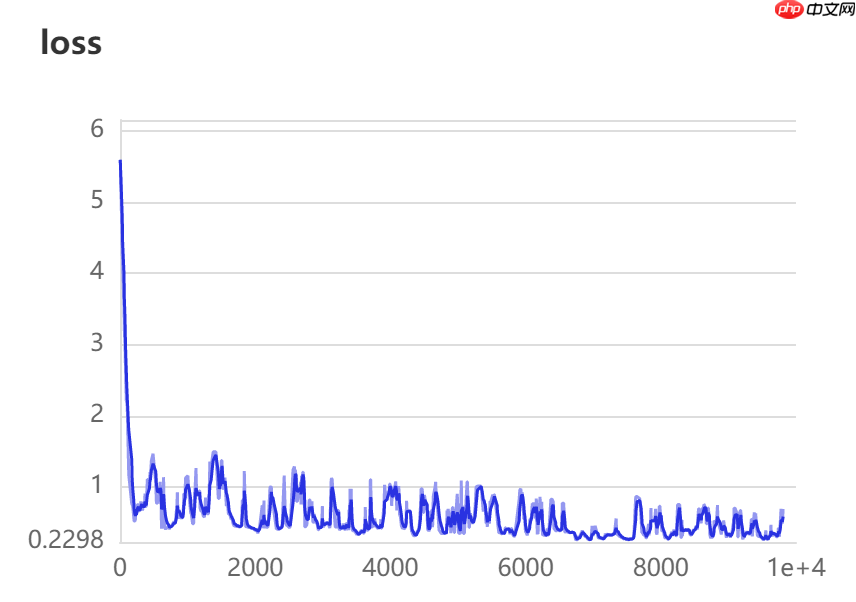
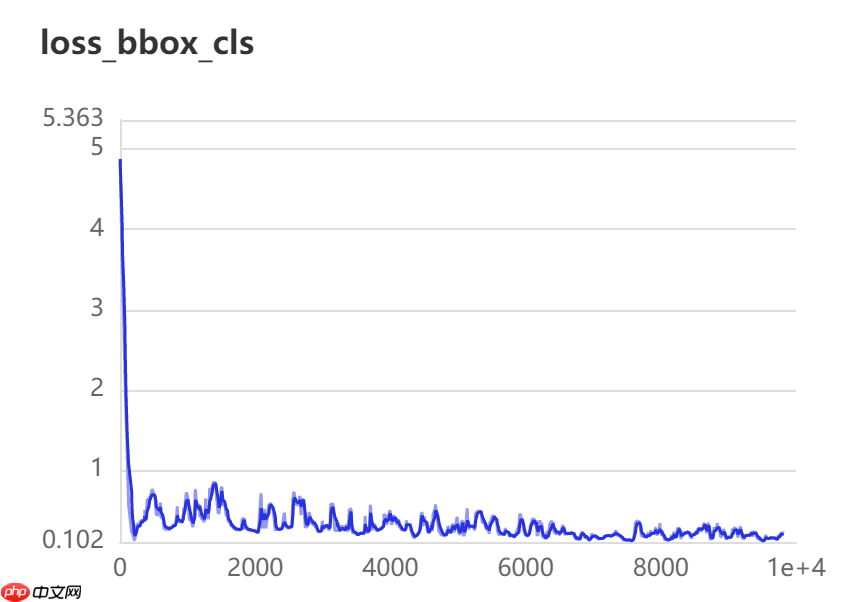
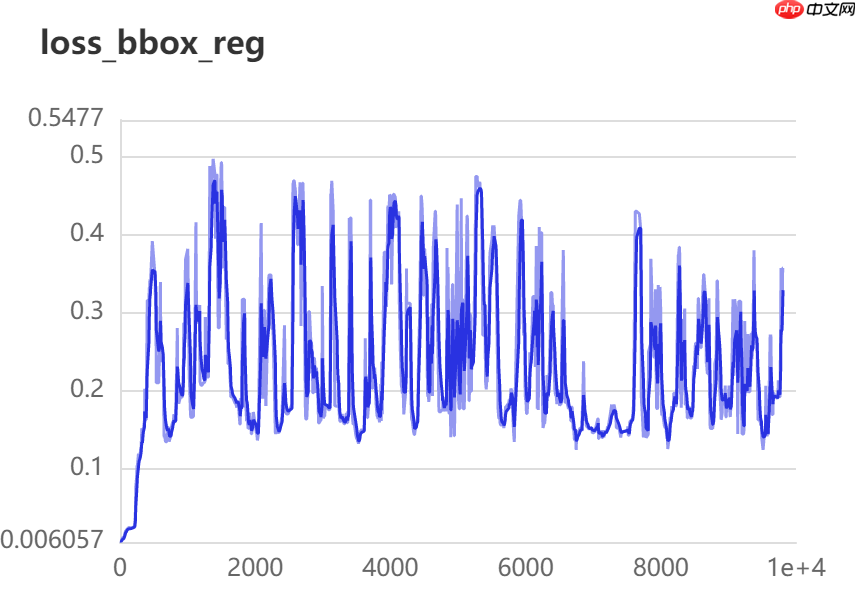
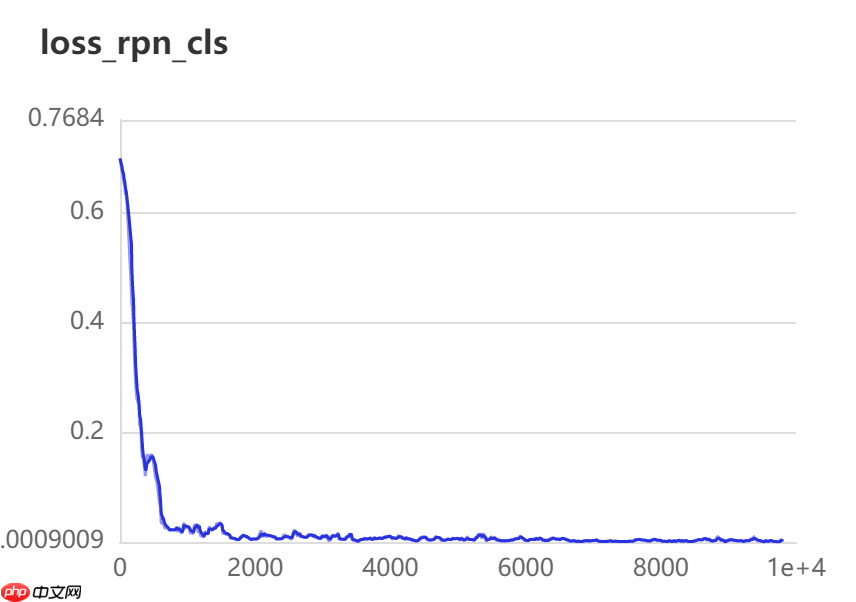
 训练20轮检测效果如下图所示:
训练20轮检测效果如下图所示:

以上就是基于PaddleDetection的智能零售柜商品识别+部署的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/744348.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















