
csv文件
-
sql中如何导入数据 数据导入的常见问题解决方案




导入数据到sql的方法包括使用命令行工具、图形化界面工具、编程语言和数据库自带工具;具体选择取决于数据源、数据库类型及对速度和灵活性的要求。常见方法有:1.使用mysql的mysql客户端或postgresql的psql执行sql脚本,适合小批量数据;2.利用navicat、dbeaver等图形化工…
-
SQL语言如何构建数据血缘分析 SQL语言在元数据追踪中的关系映射技巧




sql语言通过解析语句构建数据血缘,核心步骤包括sql语句收集、sql解析生成ast、关系抽取与映射、转换逻辑识别、血缘图谱构建与存储、可视化与查询;2. 表级血缘追踪源表与目标表依赖,列级血缘分析字段间的转换与依赖;3. 面临挑战包括sql方言差异、复杂结构(嵌套查询、cte)、动态sql、存储过…
-
Apache Camel集成AWS S3文件处理与日志配置指南
本教程详细介绍了如何使用Apache Camel从AWS S3存储桶中读取CSV文件并进行处理。文章通过一个实际案例,展示了Camel S3组件的配置和路由构建,并重点解决了在开发过程中常见的日志输出不生效问题,提供了确保Camel日志系统正常工作的关键依赖配置,帮助开发者顺利实现S3文件集成。 A…
-
如何在CentOS上备份SQL Server数据
centos系统下sql server数据库备份指南 本文将指导您如何在CentOS系统上安全地备份SQL Server数据库。 我们将涵盖手动备份和自动化备份两种方法。 第一步:安装必要软件包 首先,请确保您的CentOS系统已安装以下软件包:mssql-tools 和 unixODBC-deve…
-
PySpark CSV写入:保留字符串中的 \r\n 字面量而非换行符




当使用pyspark将包含 “(回车换行符)的字符串列写入csv文件时,pyspark默认会将其解释为实际的行分隔符,导致数据被错误地拆分成多行。本教程将详细介绍如何通过定义一个pyspark用户自定义函数(udf),在写入csv前将字符串中的 “ 和 “ 字符替…
-
lterator 怎么使用?有什么特点?




迭代器是一种统一访问集合元素的标准接口,1. 核心是通过symbol.iterator获取迭代器对象并调用next()方法返回{value, done}结构;2. for…of循环基于此协议自动遍历可迭代对象如数组、字符串等;3. 自定义可迭代对象需实现symbol.iterator方法…
-
Apache Camel集成AWS S3文件读取与日志配置实战指南
本教程深入探讨如何使用Apache Camel从AWS S3存储桶读取文件,并处理消息。重点解决在Camel路由中log组件不输出信息的问题,揭示其根本原因在于缺少必要的日志实现库。通过提供详细的代码示例和Maven依赖配置,帮助开发者正确配置Camel环境,确保路由行为可观测,从而高效地实现S3文…
-
2018-11-19 Neo4j百万级数据导入只能用neo4j-import

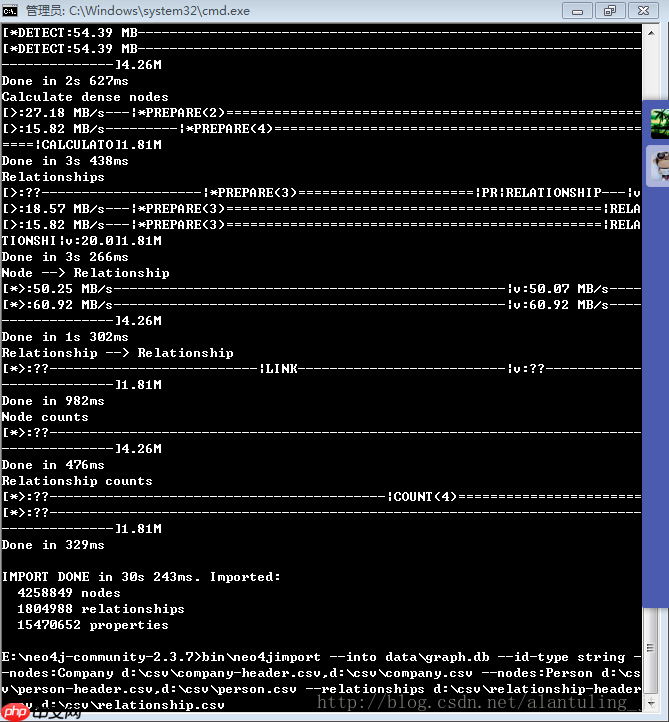
在处理大规模数据导入到neo4j时,尤其是涉及到百万级的数据量,使用合适的导入工具和方法至关重要。以下是一些建议和步骤来解决您遇到的问题: 使用neo4j-import工具 对于大规模数据导入,Neo4j官方推荐使用 neo4j-import 工具。这是一个专为大数据导入设计的高效工具,可以一次性导…
-
深入理解Snowflake外部表PATTERN参数的大小写敏感性及解决方案


本文探讨snowflake外部表在定义`pattern`参数时遇到的文件扩展名大小写敏感问题。通过引入正则表达式的字符集匹配机制,详细阐述如何配置`pattern`以实现对不同大小写文件扩展名(如`.csv`和`.csv`)的灵活匹配,确保外部表能正确识别和加载所有符合条件的数据文件。 Snowfl…
-
解决Pandas DataFrame行比较与重复值处理中的ValueError


在Pandas数据处理中,用户经常会遇到需要比较DataFrame中特定行或移除重复行的情况。然而,在执行这些操作时,尤其是在数据合并(concat)之后,可能会遭遇ValueError或发现drop_duplicates功能未能按预期工作。本文将详细解析这些问题,并提供专业的解决方案。 理解Dat…


