
大数据
-
GBAnexus粤港澳大湾区大数据中心贵阳数博会重磅发布



(贵阳8月28日电)今天上午,2025中国国际大数据产业博览会主会场迎来重磅发布——由深圳国家高技术产业创新中心负责建设与运营的gbanexus粤港澳大湾区大数据中心正式亮相。作为国家“双区建设”战略的关键支撑平台,该中心被定位为国家级公共数据基础设施,创新推出“数算用一体化”服务模式,标志着我国数…
-
美国能源部与 AMD 达成十亿合作,共建超级计算机和 AI 项目


美国能源部长克里斯・赖特(chris wright)与超威半导体公司(amd)首席执行官苏姿丰(lisa su)近日向媒体宣布,双方签署了一项价值10亿美元的合作协议,计划共同建设两台超级计算机。这两台设备将致力于应对核能开发、癌症疗法及国家安全等关键领域的重大科学难题。 赖特指出,这些新型超级计算…
-
AI越多越好?中国工业机器人探索“有用则灵”的差异化路径


对于当前的工业机器人来说,ai真的是越多越好吗?在近日举行的第八届虹桥论坛智能制造分论坛上,一个日益清晰的共识是:与海外机器人企业相比,中国的工业机器人企业正依托国内多样化的供应链场景,探索出一条更贴近工厂实际需求的差异化发展路径。 核心挑战:在效率与柔性之间寻求平衡 中国工业具身智能企业“微亿智造…
-
在Django中灵活处理QuerySet数据:手动添加记录并进行序列化


本文详细介绍了在django应用中,如何在将数据库查询结果(queryset)发送给序列化器之前,手动向其中添加自定义数据。核心方法是将queryset转换为可修改的python列表,然后追加所需字典数据,最后将此列表传递给序列化器进行处理。此技巧适用于需要将非数据库来源的辅助信息与查询结果合并的场…
-
Pandas数据框高效批量比较多列并生成差异指示列


本文详细介绍了如何在pandas数据框中高效地比较具有特定命名模式(如`_x`和`_y`后缀)的多对列,并自动生成指示差异的新列(如`_change`后缀)。通过识别列名中的共同特征,结合pandas的向量化操作,该方法显著提升了处理大量列时的效率和代码简洁性,避免了繁琐的手动定义和行级应用。 在数…
-
在Polars中高效利用列值作为字典键进行数据筛选


本文探讨了在polars dataframe中,如何解决直接使用`expr`作为字典键导致`typeerror`的问题。我们提供了两种解决方案:一种是使用`map_elements`结合`pl.struct`实现直接但效率较低的列值到字典键映射;另一种是推荐的优化方案,通过将嵌套字典扁平化为pola…
-
Scikit-learn二分类模型:核心算法与应用指南


本文旨在深入探讨scikit-learn库中用于二分类任务的核心机器学习模型。我们将澄清二分类与异常检测的区别,并详细介绍逻辑回归、支持向量机、决策树、随机森林、梯度提升机、神经网络、k近邻和朴素贝叶斯等主流算法的原理及其在scikit-learn中的实现。此外,文章还将提供模型选择、数据预处理和评…
-
2018-11-19 Neo4j百万级数据导入只能用neo4j-import

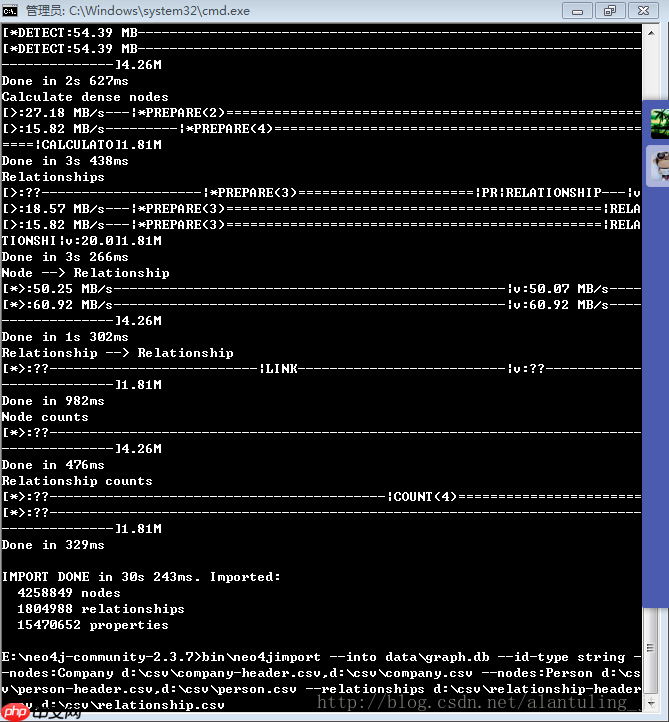
在处理大规模数据导入到neo4j时,尤其是涉及到百万级的数据量,使用合适的导入工具和方法至关重要。以下是一些建议和步骤来解决您遇到的问题: 使用neo4j-import工具 对于大规模数据导入,Neo4j官方推荐使用 neo4j-import 工具。这是一个专为大数据导入设计的高效工具,可以一次性导…
-
python如何查看hdf5文件


使用h5py库可查看HDF5文件内容,先通过pip install h5py安装,再用h5py.File()打开文件,遍历组和数据集结构,访问特定数据集并转为NumPy数组读取数据,还可结合h5view、vitables或h5dump工具快速查看。 要查看HDF5文件的内容,Python中常用的库是…
-
redis 有哪些功能?


Redis最常用的数据结构包括字符串、哈希、列表、集合和有序集合。字符串适合缓存和计数器;哈希用于存储对象,如用户信息;列表基于双向链表,适用于消息队列;集合支持去重和交并差运算,适用于关系分析;有序集合通过分数排序,广泛用于排行榜和范围查询。这些结构结合Redis的高性能内存操作,使其在缓存、会话…
