
大数据
-
一文看懂“存算一体”
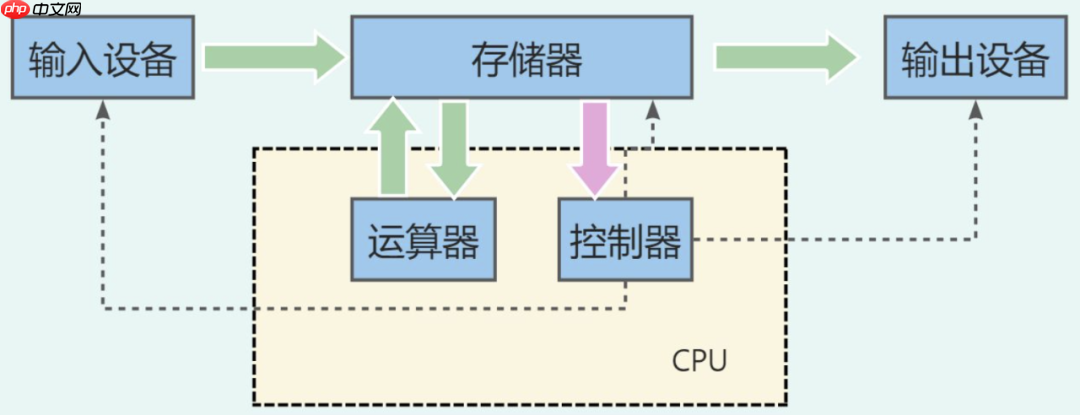
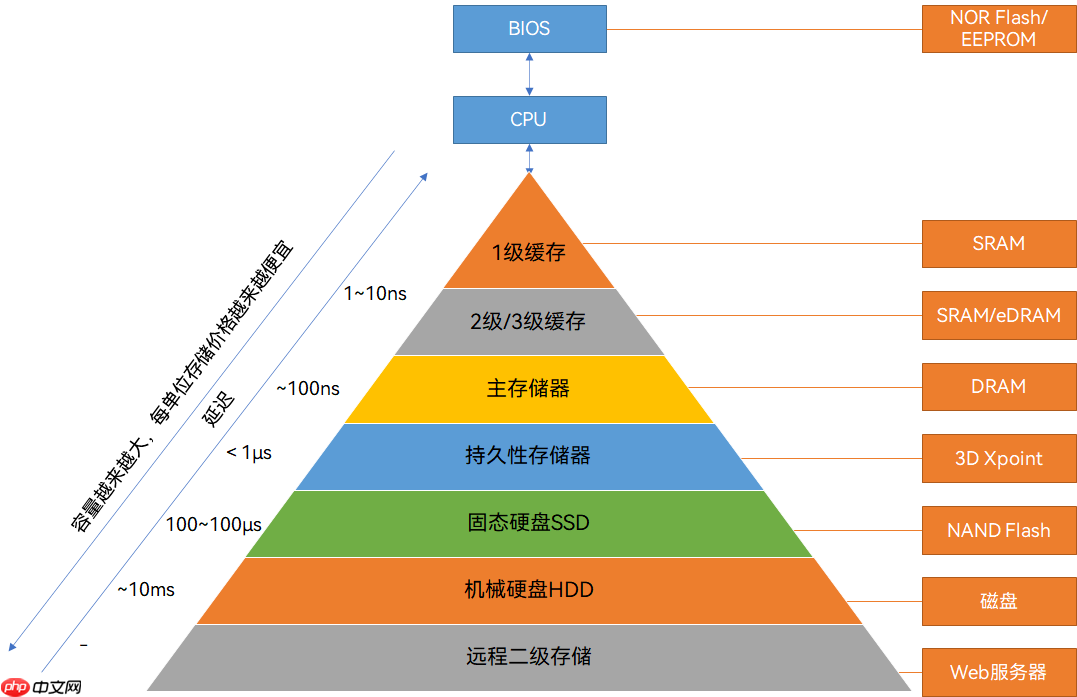
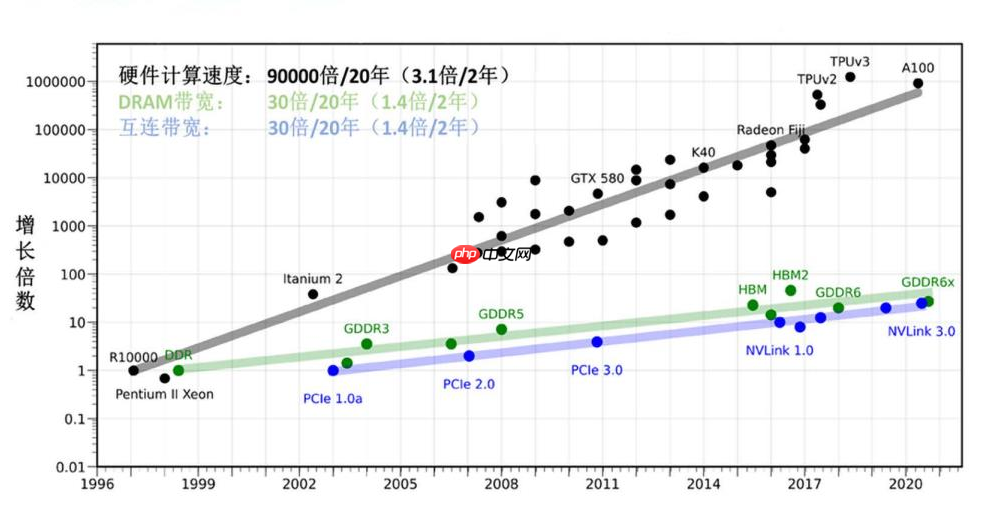
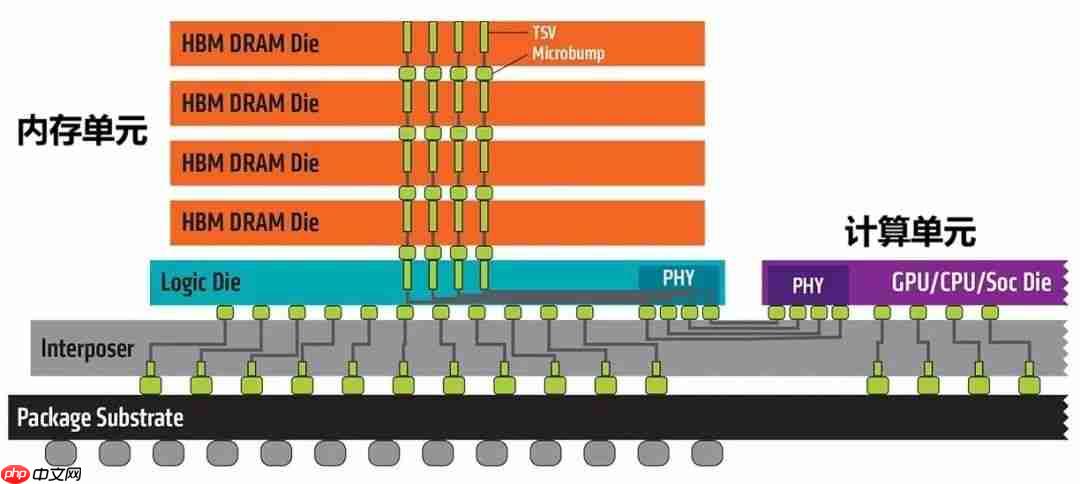
今天这篇文章,我们来聊一个最近几年很火的概念 —— 存算一体。 █ 为什么会提出“存算一体”? 存算一体,英文叫 Compute In Memory,简称 CIM。顾名思义,就是将存储和计算放在一起。 大家都知道,存储和计算,是我们处理数据的两种基本方式。自从计算机诞生以来,我们采用的主流计算架构,…
-
SQL 分组查询如何处理字符串分组?




字符串分组的核心是将相同字符串值的行聚合,但需处理大小写、空格、排序规则等问题。通过TRIM()、LOWER()、COLLATE等函数标准化数据,并在索引优化和预处理基础上提升性能,确保分组准确高效。 SQL 分组查询处理字符串分组的核心,其实就是将具有相同字符串值的行聚合在一起。这听起来直接,但在…
-
SQL 分组查询如何优化 COUNT 统计?


优化SQL分组查询中的COUNT统计需综合索引设计、COUNT形式选择、查询重构与预聚合策略。首先,为GROUP BY列创建复合索引,优先将分组列置于索引前导位置,并考虑覆盖索引以避免回表;其次,优先使用COUNT(*)而非COUNT(列名),因其不检查NULL值,可利用任意非空索引高效计数,而CO…
-
SQL SELECT 如何处理大数据量查询?


应避免SELECT *,通过限定字段、分页查询、建立索引、分区表、异步导出和采样等手段优化大数据量查询。1. 只查必要字段减少I/O;2. 用键值分页替代OFFSET避免深分页性能问题;3. 在WHERE、ORDER BY字段建索引,避免函数干扰;4. 大表按时间或范围分区,减少扫描量;5. 非实时…
-
SQL COUNT DISTINCT 怎么用才正确?


COUNT(DISTINCT 列名)用于统计非空唯一值的数量,如SELECT COUNT(DISTINCT city) FROM users返回不重复城市数;NULL值被自动忽略,多列去重需用子查询实现,大数据量时建议建索引或使用近似函数优化性能。 在使用 SQL 的 COUNT(DISTINCT …
-
SQL SELECT 如何使用 EXISTS 判断是否存在?


EXISTS用于判断子查询是否返回结果,只要有一行即返回true,否则false,常用于WHERE子句中。语法为SELECT 字段列表 FROM 表名 WHERE EXISTS(子查询);适用于检查关联数据,如查找有订单的客户:SELECT c.客户ID, c.姓名 FROM 客户 c WHERE …
-
AI执行SQL日期函数的方法_利用AI处理时间查询教程


AI通过自然语言处理与数据库Schema理解,将用户的时间查询需求转化为精确的SQL语句,并适应不同数据库方言、时区及业务逻辑,实现高效的时间数据交互。 AI在处理SQL日期函数时,核心能力在于将自然语言请求转化为精确的数据库时间查询语句,或者反过来,解释复杂的时间查询逻辑。这就像是给数据库和人类用…
-
SQL变量使用如何优化_变量使用最佳实践与性能影响


答案:SQL变量优化需关注作用域、生命周期及对执行计划的影响,避免在关键查询中使用变量导致基数估计不准,引发索引失效或次优执行计划。应确保变量与列数据类型匹配,防止隐式转换,并优先使用参数化查询以支持计划重用。警惕参数嗅探问题,可通过OPTION (RECOMPILE)、OPTIMIZE FOR或局…
-
SQL 聚合函数计算多列总和怎么做?


计算多列总和需先处理NULL值,常用SUM(COALESCE(col,0))实现行级加法后聚合,或用SUM(col1)+SUM(col2)先聚合再相加,二者在有NULL时结果一致;对于多列或动态列场景,可用CROSS APPLY或UNION ALL将列转为行再求和,提升可维护性;性能上直接加法最优,…
-
稻壳阅读器官网最新访问地址 稻壳阅读器在线阅读平台主页入口链接

稻壳阅读器官网最新访问地址是http://www.daokeyuedu.com/,该平台支持PDF、XDF、EPUB等三十余种文档格式解析,集成海量学术资料与办公资源,提供智能检索、多模式阅读、全文复制及云端共享功能,无需下载即可在线流畅阅读。 稻壳阅读器官网最新访问地址在哪里?这是不少网友都关注的…
