
llama
-
超火迷你GPT-4视觉能力暴涨,GitHub两万星,华人团队出品
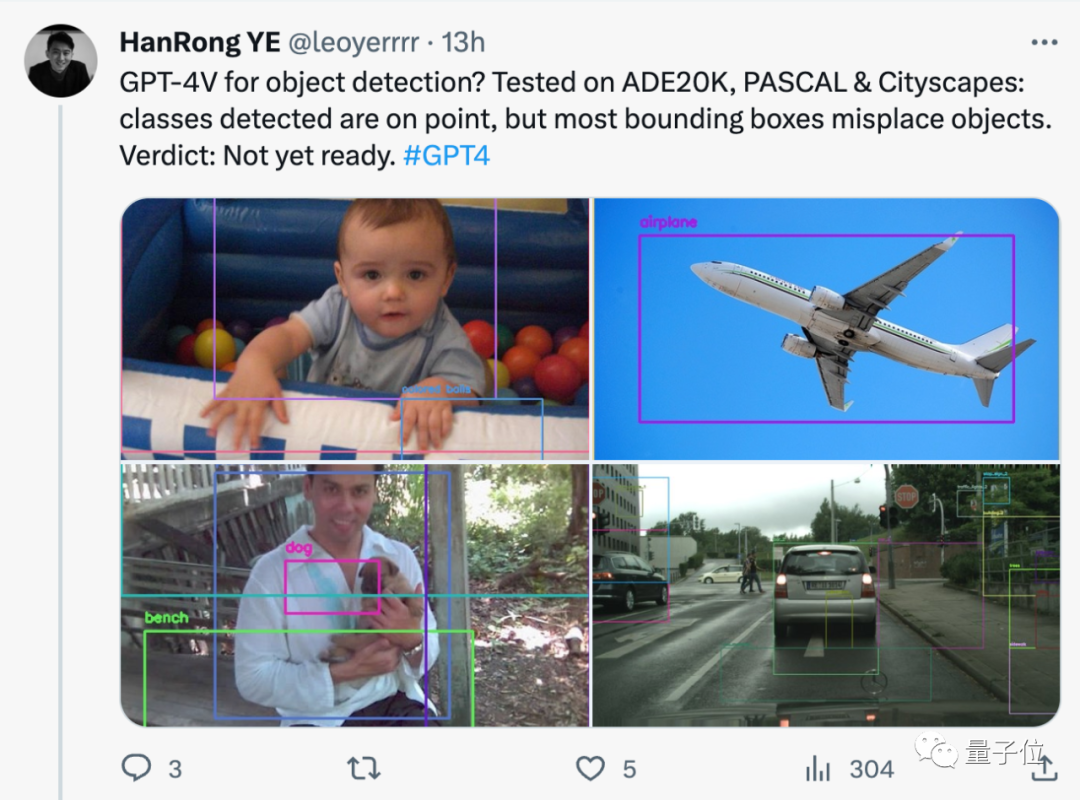
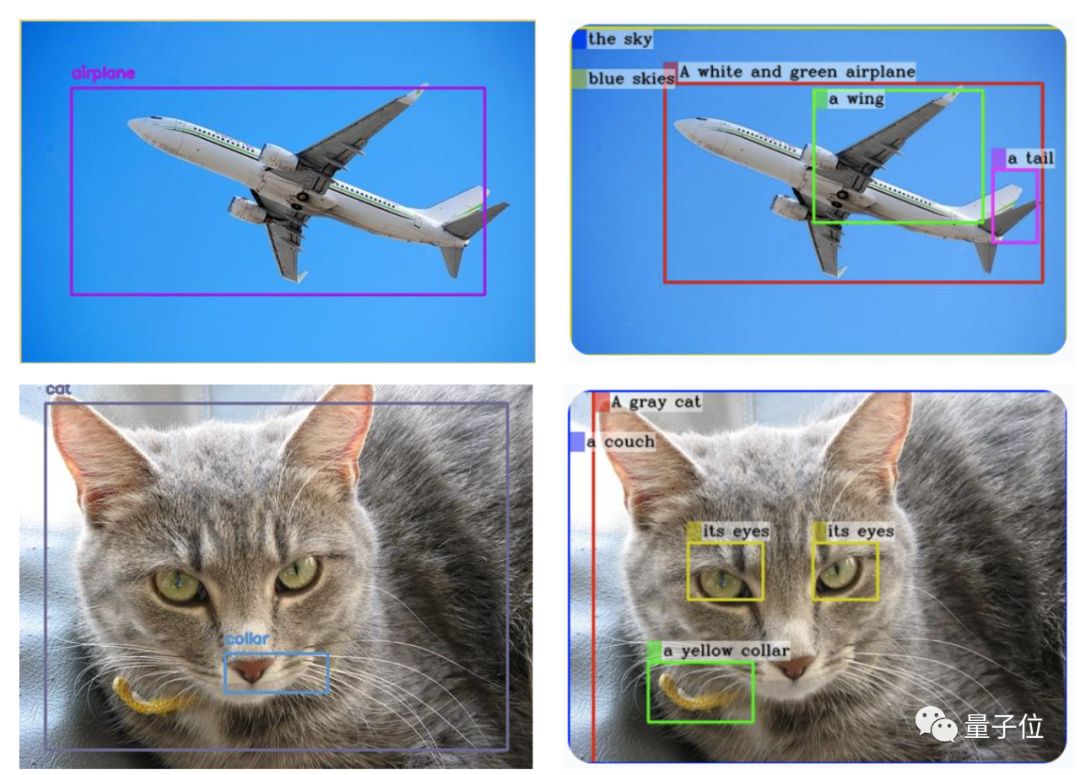

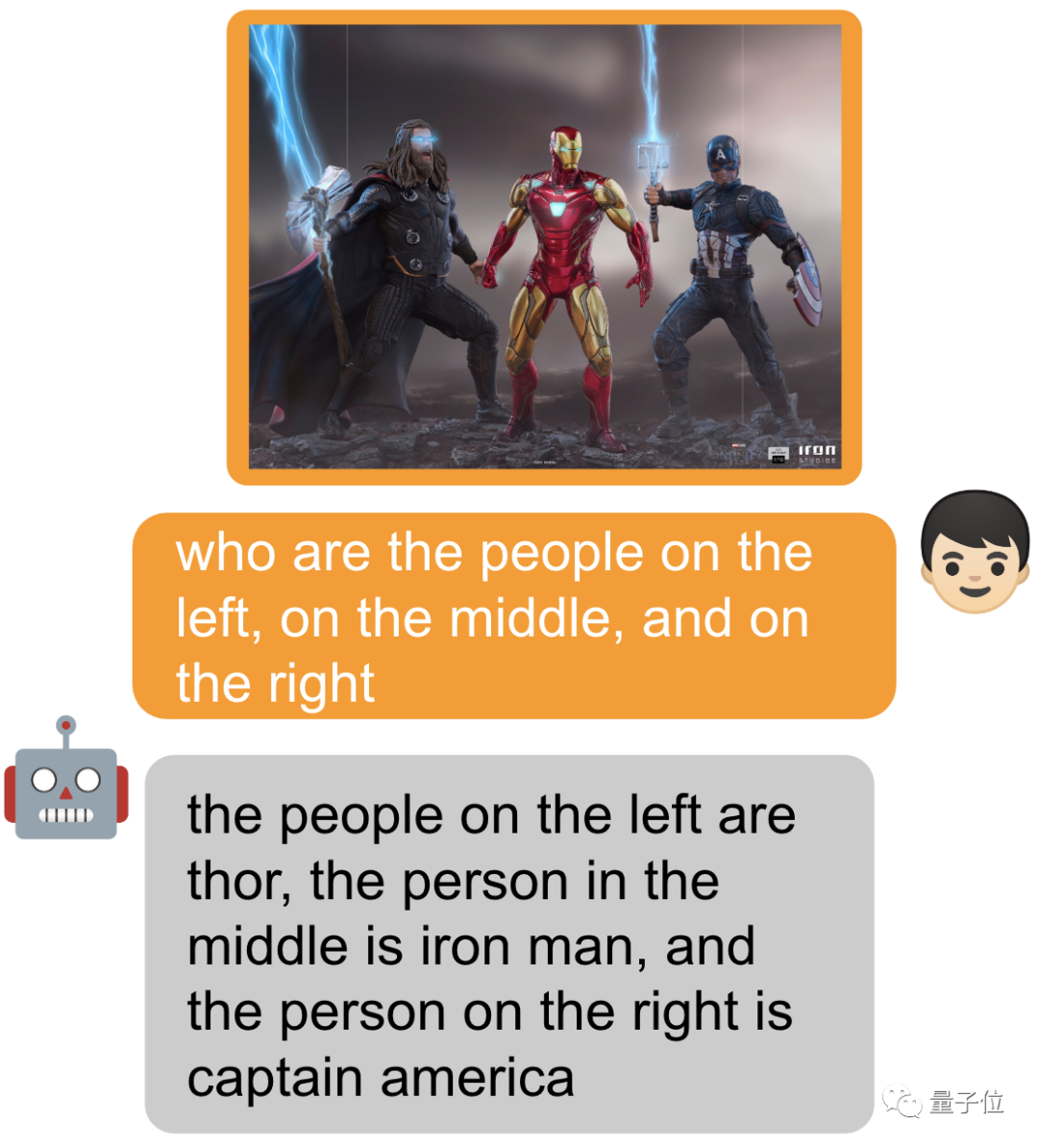
gpt-4v来做目标检测?网友实测:还没有准备好。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 %ignore_a_1%☜☜☜ 虽然检测到的类别没问题,但大多数边界框都错放了。 没关系,有人会出手! 那个抢跑GPT-4看图能力几个月的迷你GPT-4升…
-
掌握商业人工智能:使用 RAG 和 CRAG 构建企业级人工智能平台
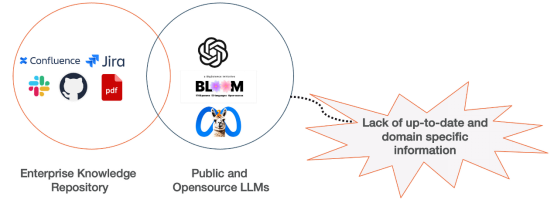
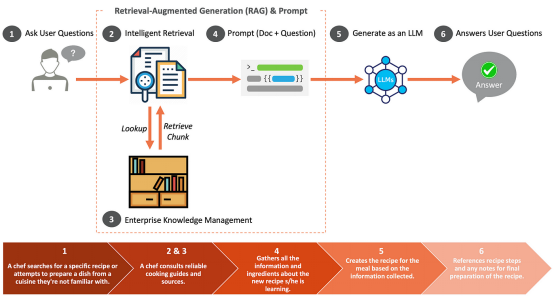
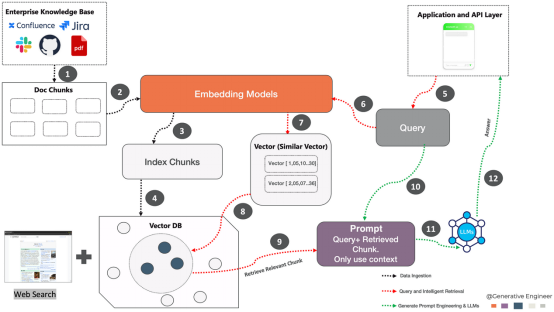
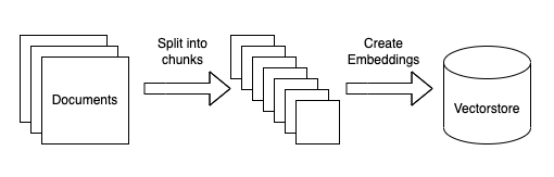
浏览我们的指南,掌握如何让您的企业充分利用人工智能技术。了解 rag 和 crag 集成、矢量嵌入、llm 和提示工程等内容,这对那些希望负责任地应用人工智能的企业来说非常有益。 为企业打造AI-Ready平台 企业在引入生成式人工智能时,会遇到许多需要战略管理的业务风险。这些风险通常是相互关联的,…
-
干货满满!大神Karpathy两小时AI大课文字版第一弹,全新工作流自动把视频转成文章
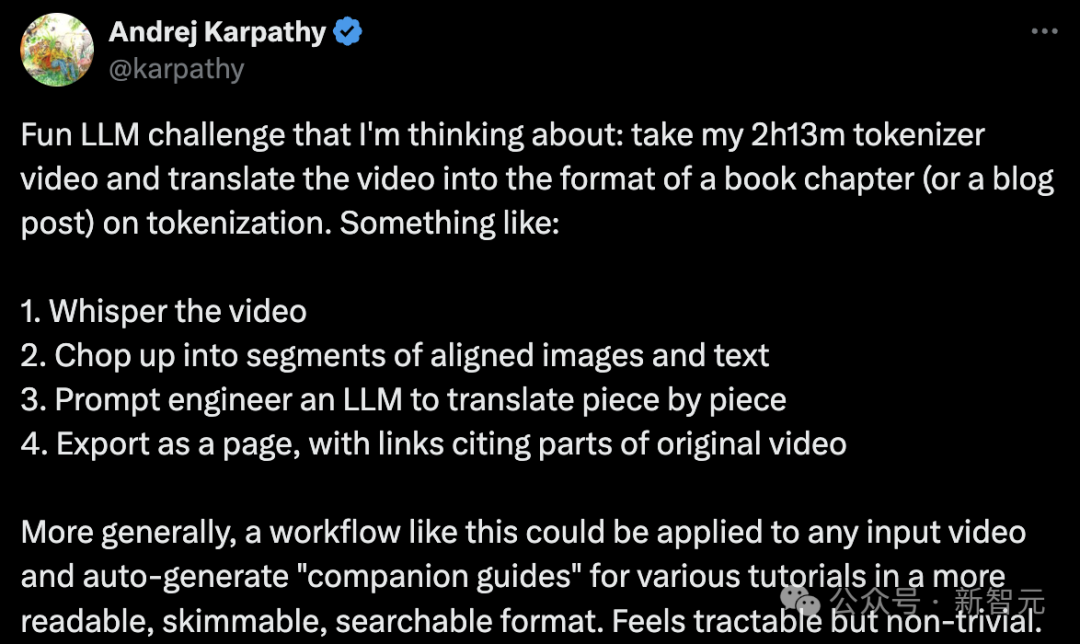
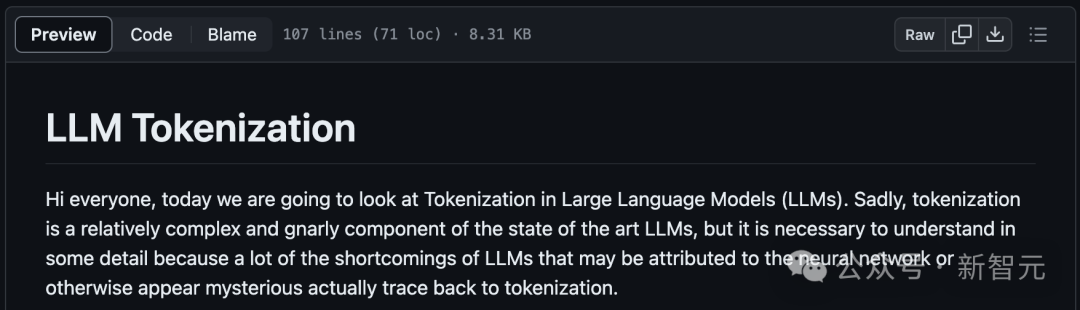
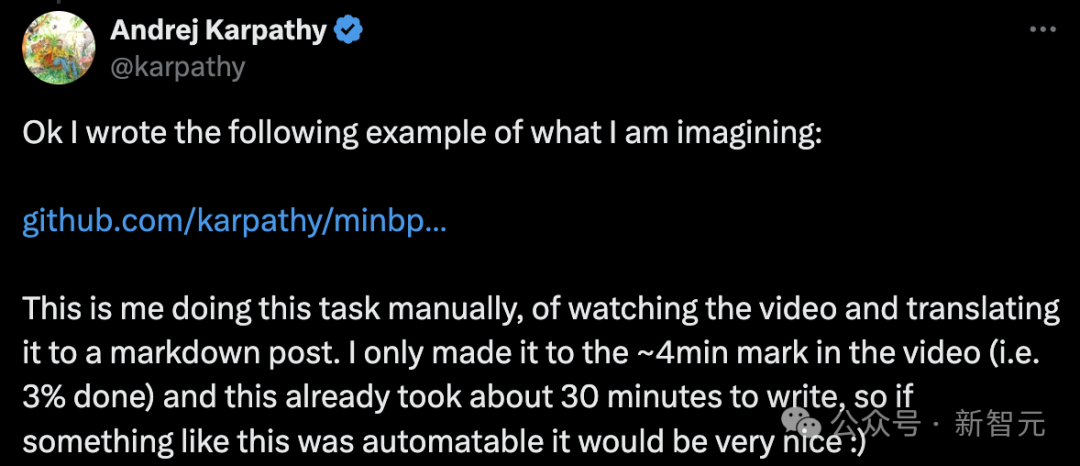
前段时间,AI大神Karpathy上线的AI大课,已经收获了全网15万次播放量。 当时还有网友表示,这2小时课程的含金量,相当于大学4年。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 就在这几天,Karpathy又萌生了一个新的想法: 将…
-
LLMLingua: 整合LlamaIndex,压缩提示并提供高效的大语言模型推理服务
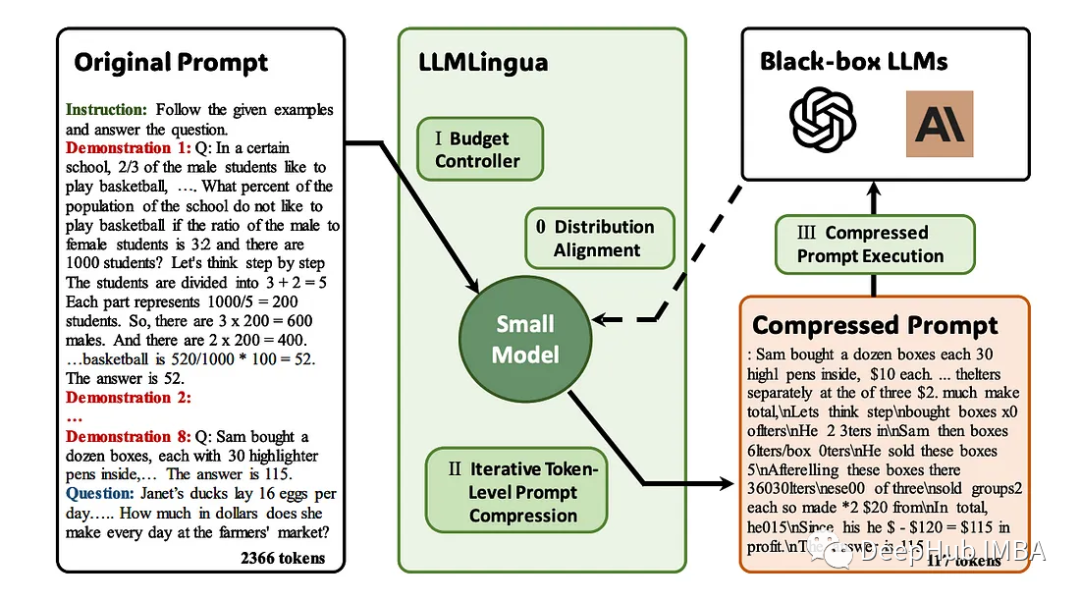
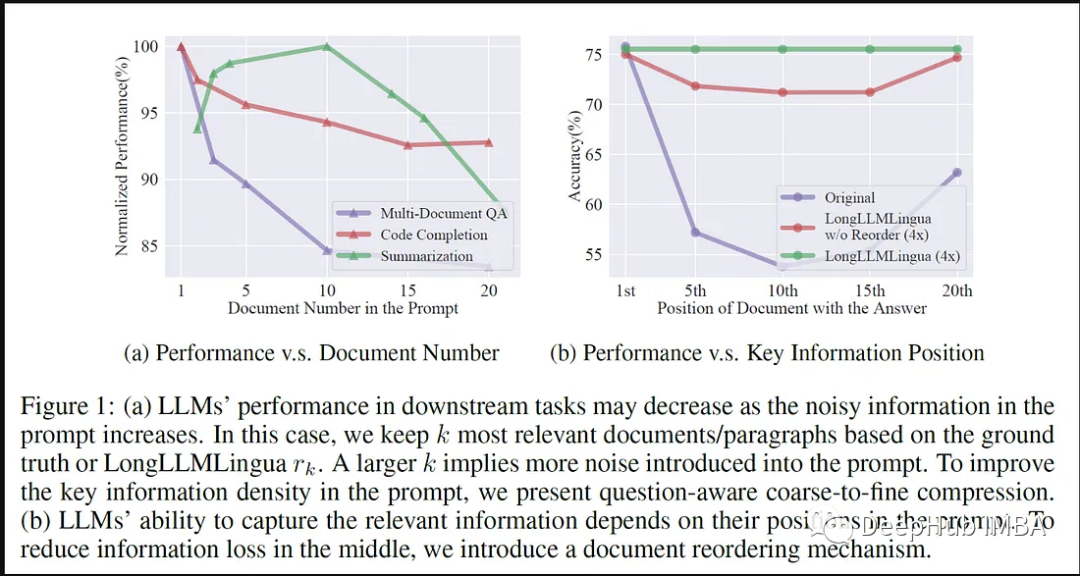


大型语言模型(llm)的出现刺激了多个领域的创新。然而,在思维链(cot)提示和情境学习(icl)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。这些冗长的提示需要大量的资源来进行推理,因此需要高效的解决方案。本文将介绍llmlingua与专有的llamaindex的集成执行高效推理 ☞☞…
-
让大模型“瘦身”90%!清华&哈工大提出极限压缩方案:1bit量化,能力同时保留83%

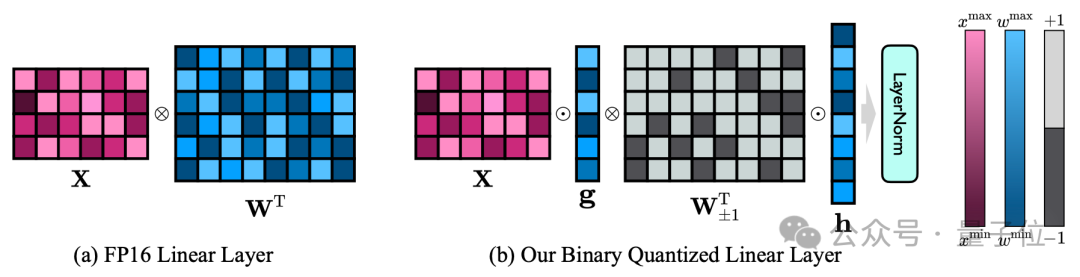
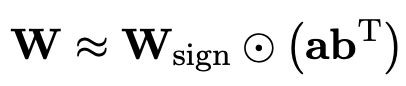

对大模型进行量化、剪枝等压缩操作,是部署时最常见不过的一环了。 不过,这个极限究竟有多大? 清华大学和哈工大的一项联合研究给出的答案是: 90%。 他们提出了大模型1bit极限压缩框架OneBit,首次实现大模型权重压缩超越90%并保留大部分(83%)能力。 可以说,玩儿的就是“既要也要”~ ☞☞☞…
-
媲美OpenAI事实性基准,这个中文评测集让o1-preview刚刚及格



☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢…
-
ChatGPT分享-如何开发一个LLM应用
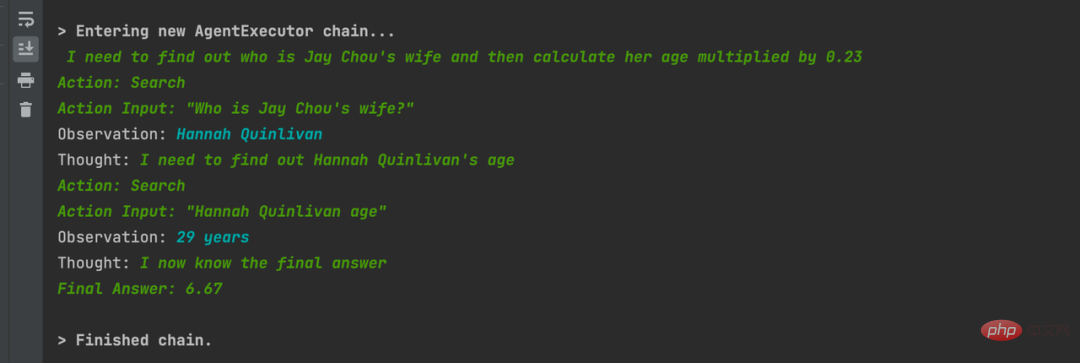
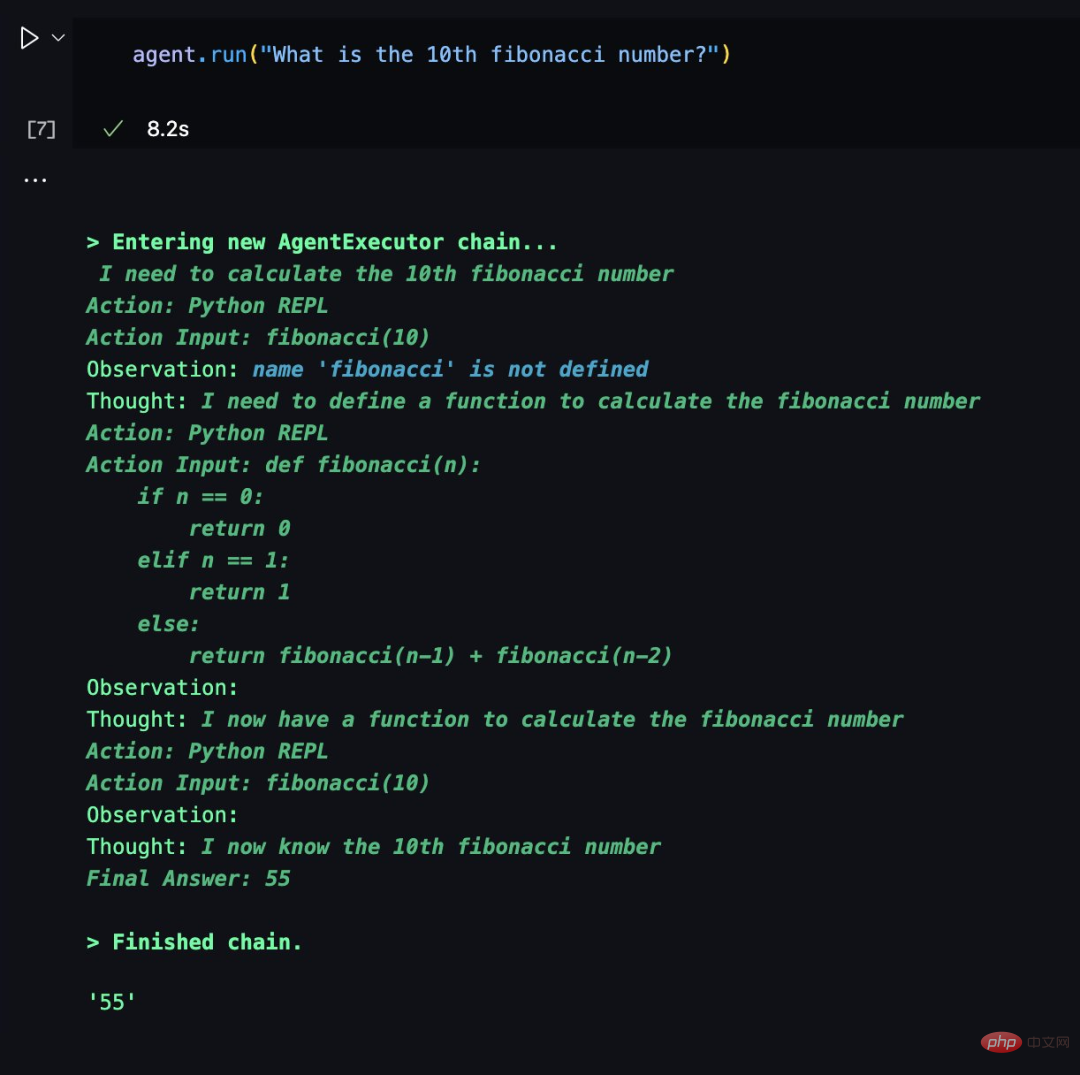
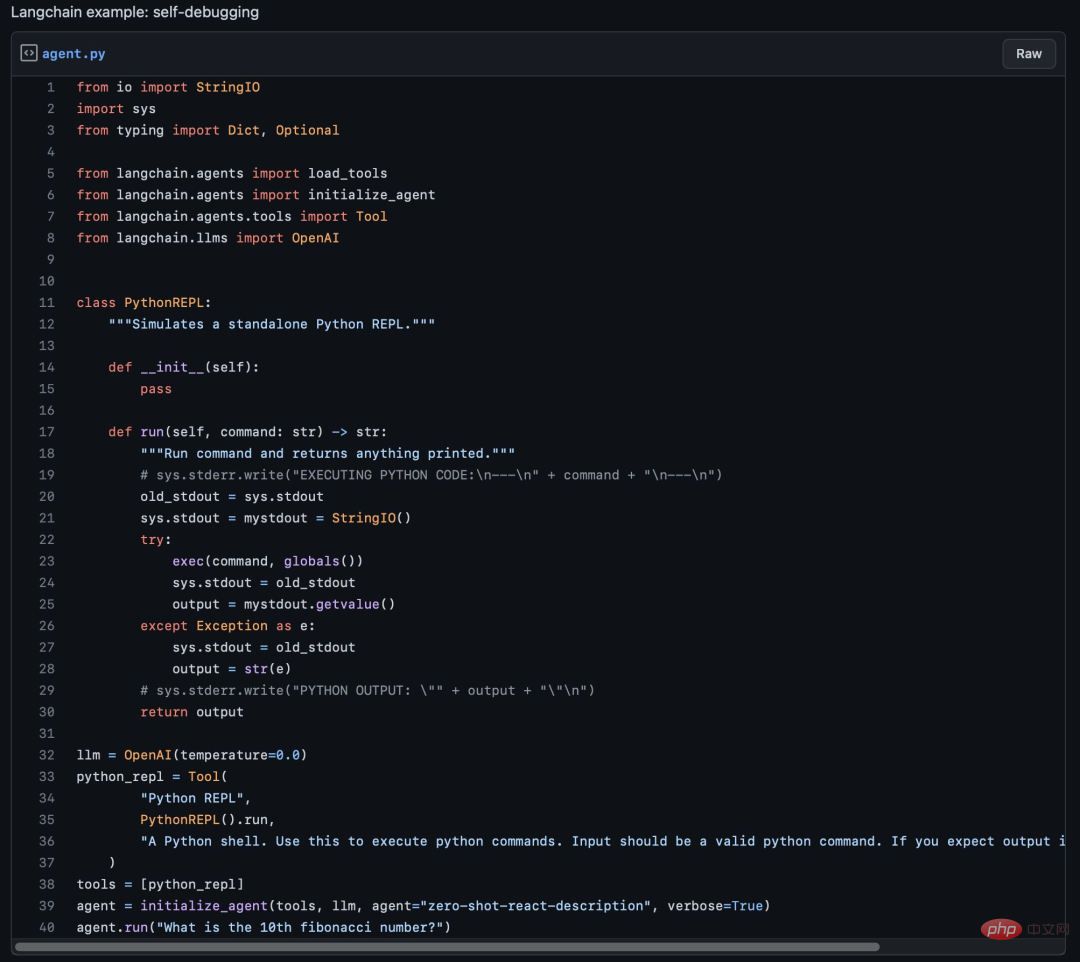
1背景 ChatGPT引起巨大的业界震撼,各行各业都在讨论大语言模型、通用人工智能。AI经历了五十多年的发展,现在正处于产业结构水平化发展的关键时期。这一变化源于NLP领域范式的转变,从“预训练+微调”向“预训练、提示、预测”模式演进。在这一新模式下,下游任务适应预训练模型,使得一个大型模型能适…
-
图灵奖得主LeCun:ChatGPT局限巨大,自回归模型寿命不超5年


今年上半年,可谓是AI届最波澜壮阔的半年。 在急速发展的各类GPT甚至AGI的雏形背后,是持不同观点的两大阵营的人们。 一派认为,以ChatGPT为首的生成式AI非常强大,能带动一大波革命性的风潮,继续推进没有问题。 另一派认为,咱发展的有点太快了。不说禁止,也得停一停。而且道德方面,相匹配的约束也…
-
少用ChatGPT,多支持开源!纽约大学教授Nature发文:为了科学界的未来
免费的ChatGPT用的是很爽,但这种闭源的语言模型最大的缺点就是不开源,外界根本无法了解背后的训练数据以及是否会泄露用户隐私等问题,也引发了后续工业界、学术界联合开源了LLaMA等一系列羊驼模型。 最近Nature世界观栏目刊登了一篇文章,纽约大学政治与数据科学教授Arthur Spirling呼…
-
可复现、自动化、低成本、高评估水平,首个自动化评估大模型的大模型PandaLM来了
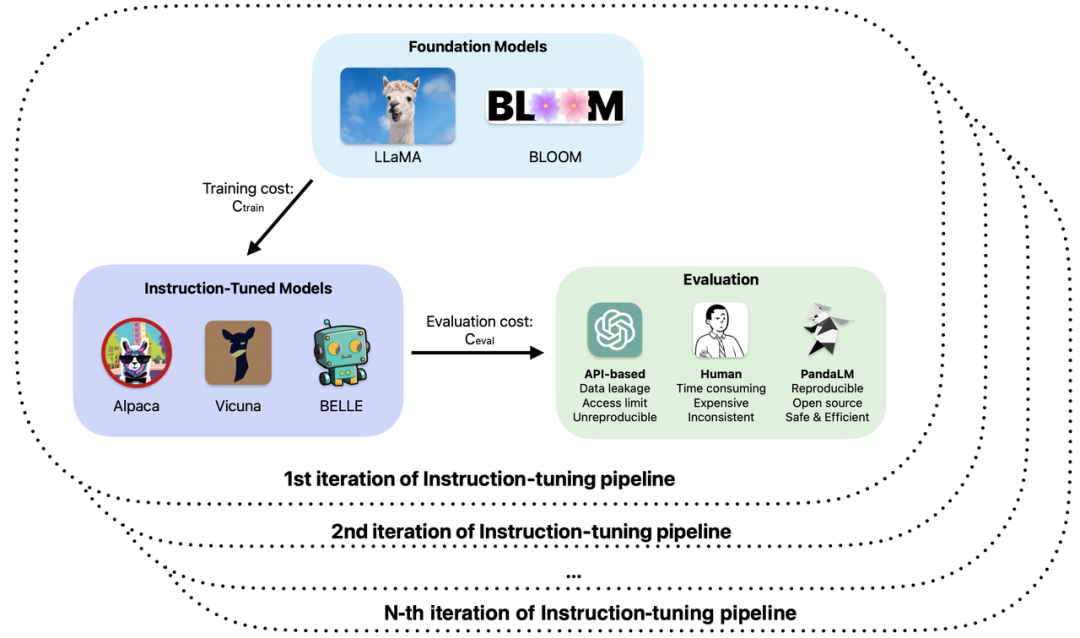

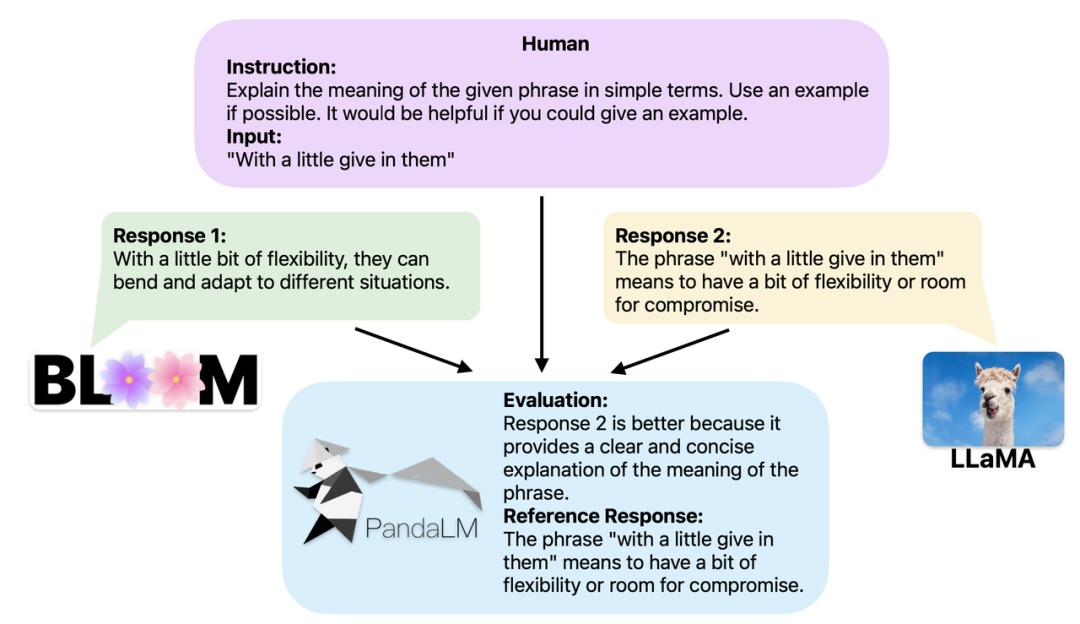

大模型的发展可谓一日千里,指令微调方法犹如雨后春笋般涌现,大量所谓的 ChatGPT “平替” 大模型相继发布。在大模型的训练与应用开发中,开源、闭源以及自研等各类大模型真实能力的评测已经成为提高研发效率与质量的重要环节。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 Dee…

