
llama
-
4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议
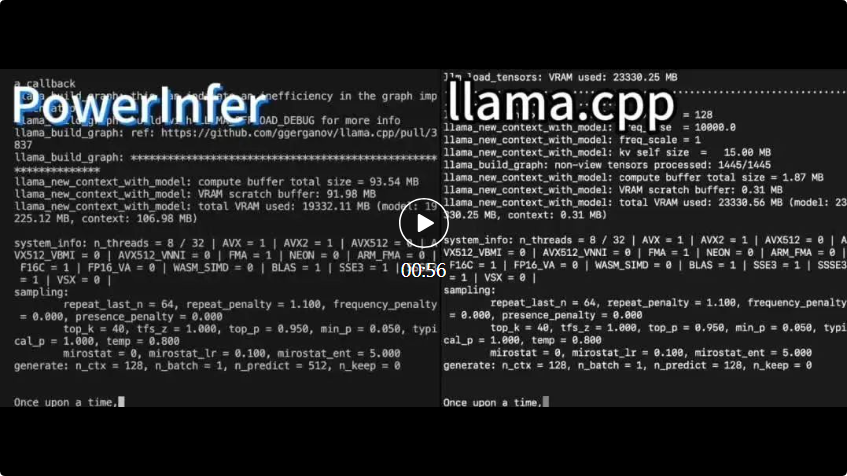

powerinfer 提高了在消费级硬件上运行 ai 的效率 上海交大团队最新推出了超强 CPU/GPU LLM 高速推理引擎 PowerInfer。 PowerInfer 和 llama.cpp 都在相同的硬件上运行,并充分利用了…
-
MoE与Mamba携手合作,将状态空间模型推广至数十亿参数规模

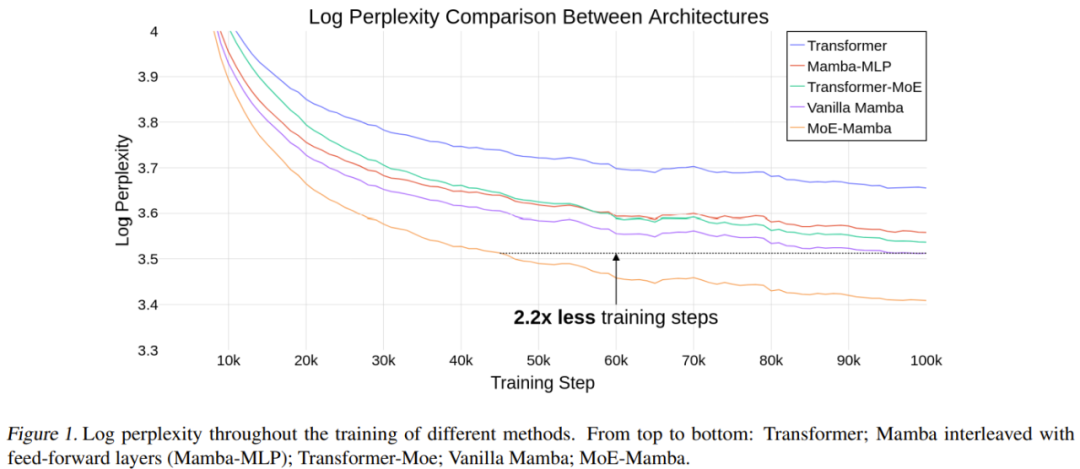


状态空间模型(SSM)是一种备受关注的技术,它被认为是Transformer的替代选择。相比于Transformer,SSM在处理长上下文任务时能够实现线性时间的推理,同时具备并行化训练和出色的性能。特别是基于选择性SSM和硬件感知型设计的Mamba,更是展现出了卓越的表现,成为了基于注意力的Tra…
-
元象首个MoE大模型开源:4.2B激活参数,效果堪比13B模型

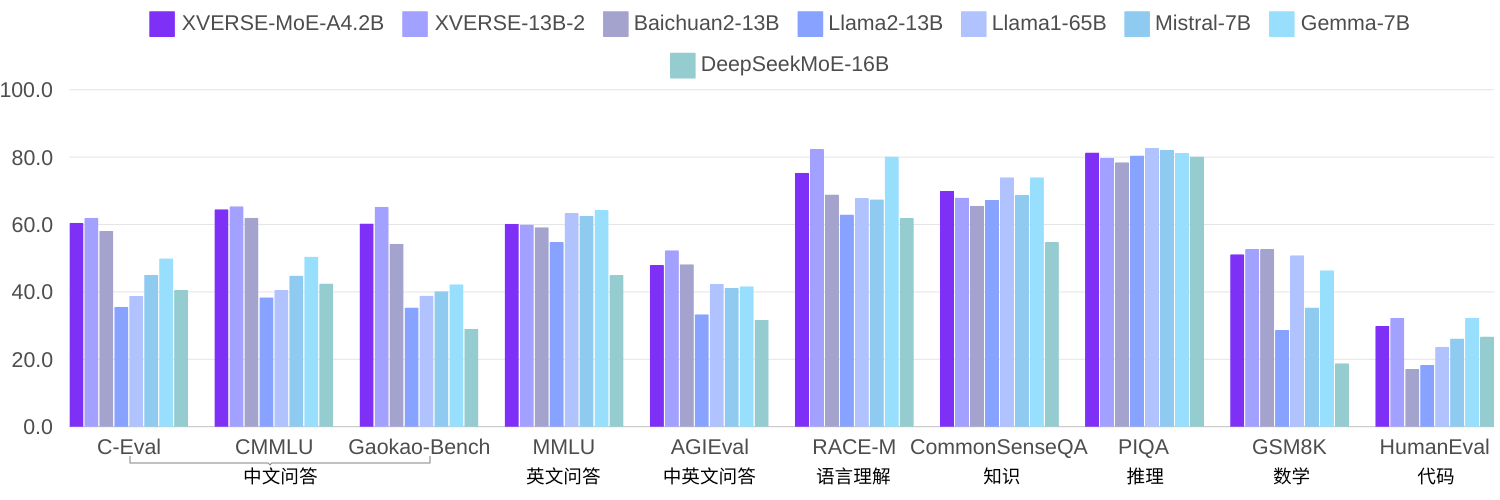

元象发布xverse-moe-a4.2b大模型 , 采用业界最前沿的混合专家模型架构 (mixture of experts),激活参数4.2b,效果即可媲美13b模型。该模型全开源,无条件免费商用,让海量中小企业、研究者和开发者可在元象高性能“全家桶”中按需选用,推动低成本部署。 ☞☞☞AI 智能…
-
OpenAI生成文本速度慢怎么办_OpenAI生成速度慢的优化方法与解决方案



首先优化API参数以提升响应速度,具体包括降低max_tokens、设置temperature接近0及启用stream模式;其次通过高性能GPU如RTX 4090或A100并启用FP16/INT8精度与torch.compile()优化推理性能;再者采用轻量化模型如Phi-3或Llama-3-8B-…
-
芯原超低能耗NPU可为移动端大语言模型推理提供超40 TOPS算力
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 2025年6月9日,中国上海——芯原股份(芯原,股票代码:688521.SH)今日宣布其高性能且超低功耗的神经网络处理器(NPU)IP现已可在移动设备上实现大语言模型(LLM)推理,AI算力可扩…
-
Qianfan-VL— 百度开源的视觉理解模型


Qianfan-VL是什么 qianfan-vl是百度智能云千帆推出的一款专为企业级多模态应用打造的视觉理解大模型。该模型提供3b、8b和70b三种参数规模版本,兼具强大的通用视觉理解能力,并在ocr识别、教育解题等垂直领域进行了专项优化。基于开源架构研发,qianfan-vl在百度自研的昆仑芯p8…
-
笔记本RTX 5090、5080、5070Ti谁最坑?实测给你答案
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 英伟达推出的RTX 50系列笔记本电脑GPU高端型号,包括RTX 5070 Ti、RTX 5080和RTX 5090,已经全面进入市场,为发烧级游戏玩家带来了全新的性能体验。然而,各大媒体测试显…
-
【曝光】iPhone 17 Air 电池容量和重量信息泄漏
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ iPhone 17 Air 电池容量和重量信息泄露 笔记本RTX 5090、5080、5070Ti哪个性价比最高?实测给你答案 美国官员对苹果在中国的AI合作计划表示担忧 1. iPhone 1…
-
让GenAI提供更好答案的诀窍


☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ genai作为一种界面具有巨大的潜力,可以让用户以独特的方式查询数据,获取满足他们需求的答案。例如,作为一个查询助手,genai工具可以帮助客户通过简单的问答格式更有效地浏览广泛的产品知识库。通…
-
清华NLP组发布InfLLM:无需额外训练,「1024K超长上下文」100%召回!

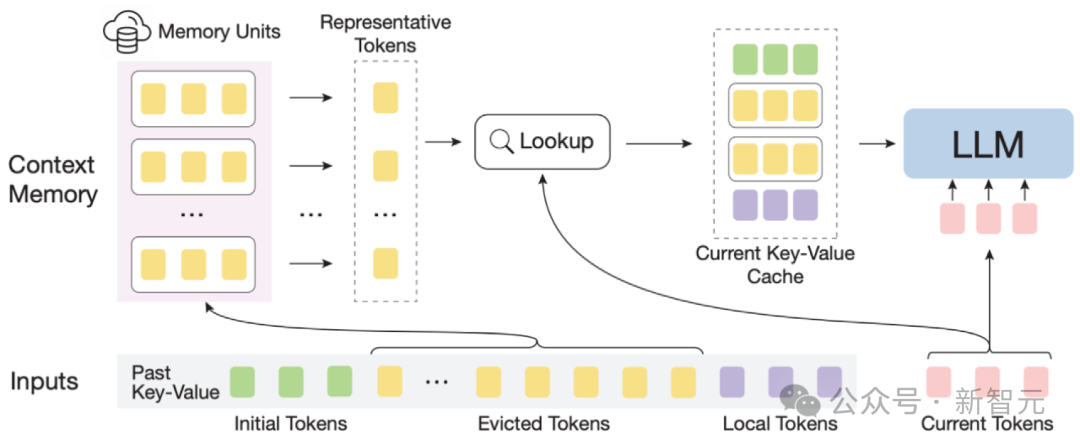
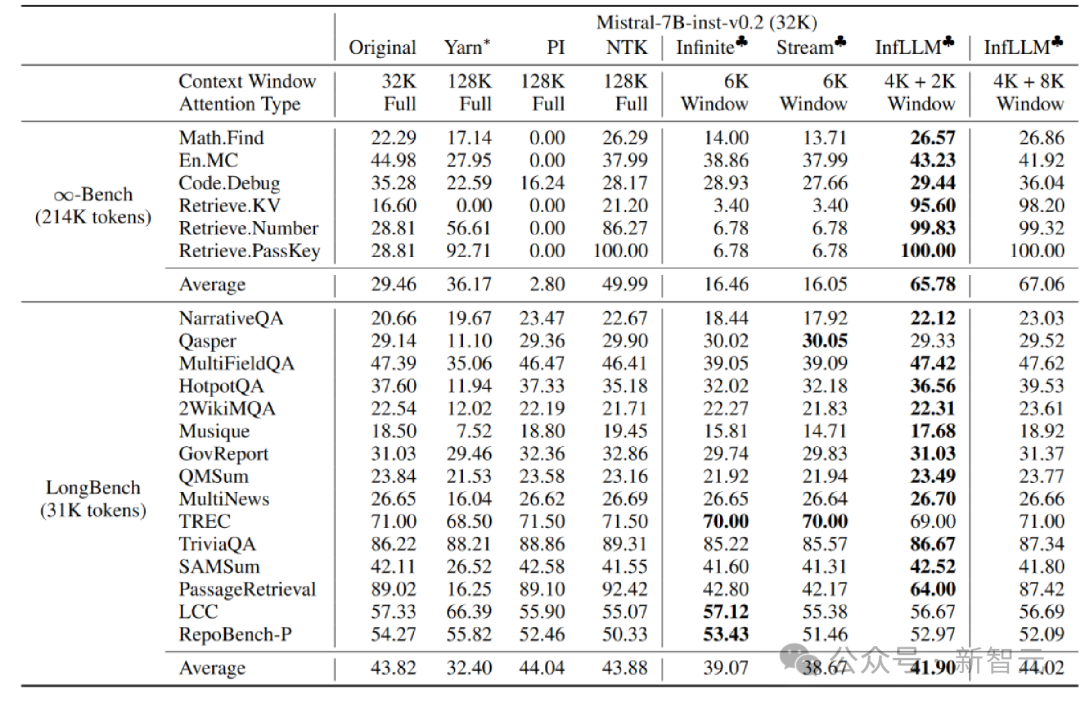
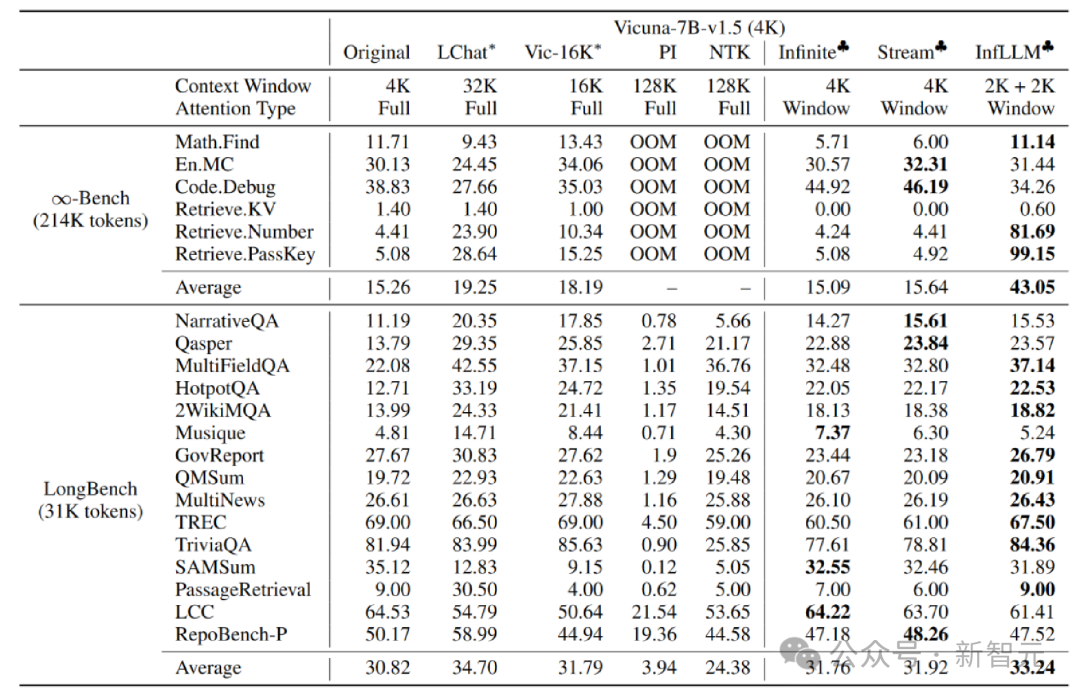
大型模型仅能记忆和理解有限的上下文,这已成为它们在实际应用中的一大制约。例如,对话型人工智能系统常常无法持久记忆前一天的对话内容,这导致利用大型模型构建的智能体表现出前后不一致的行为和记忆。 为了让大型模型能够更好地处理更长的上下文,研究人员提出了一种名为InfLLM的新方法。这一方法由清华大学、麻…



