
llama
-
OpenAI霸榜前二!大模型代码生成排行榜出炉,70亿LLaMA拉跨,被2.5亿Codex吊打
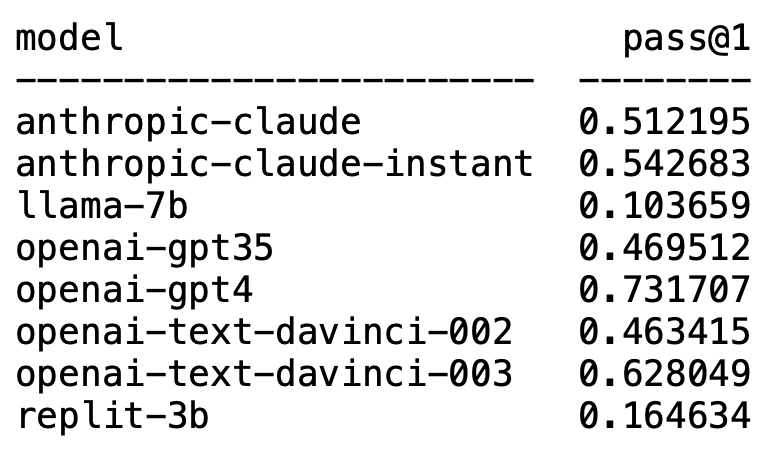


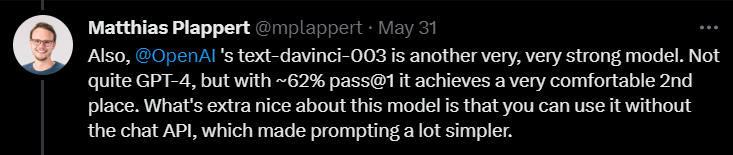
最近,Matthias Plappert的一篇推文点燃了LLMs圈的广泛讨论。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ Plappert是一位知名的计算机科学家,他在HumanEval上发布了自己对AI圈主流的LLM进行的基准测试结果…
-
如何应对生成式大模型「双刃剑」?之江实验室发布《生成式大模型安全与隐私白皮书》




当前,生成式大模型已经为学术研究甚至是社会生活带来了深刻的变革,以 ChatGPT 为代表,生成式大模型的能力已经显示了迈向通用人工智能的可能性。但同时,研究者们也开始意识到 ChatGPT 等生成式大模型面临着数据和模型方面的安全隐患。 今年 5 月初,美国白宫与谷歌、微软、OpenAI、Anth…
-
将330亿参数大模型「塞进」单个消费级GPU,加速15%、性能不减

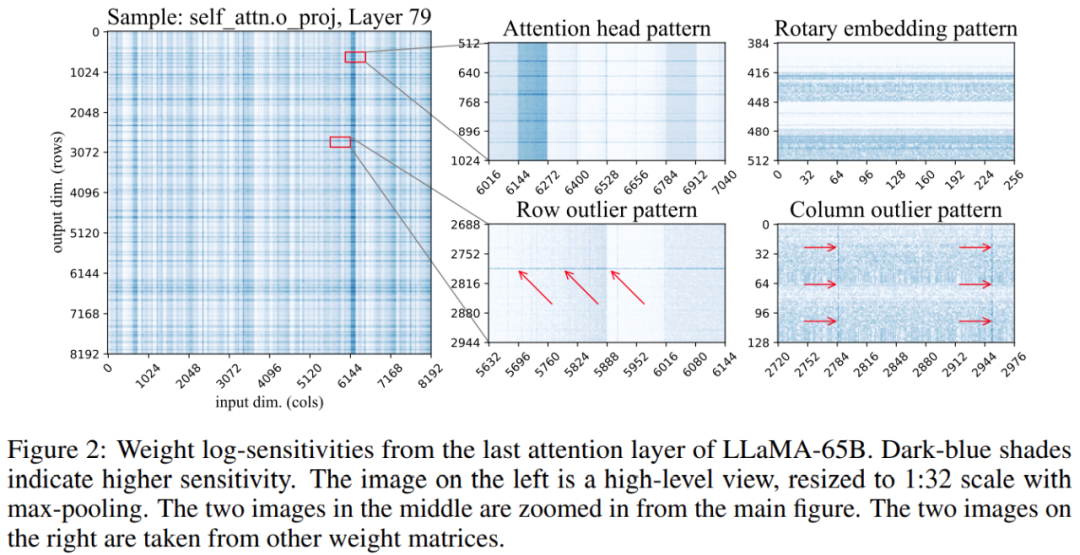
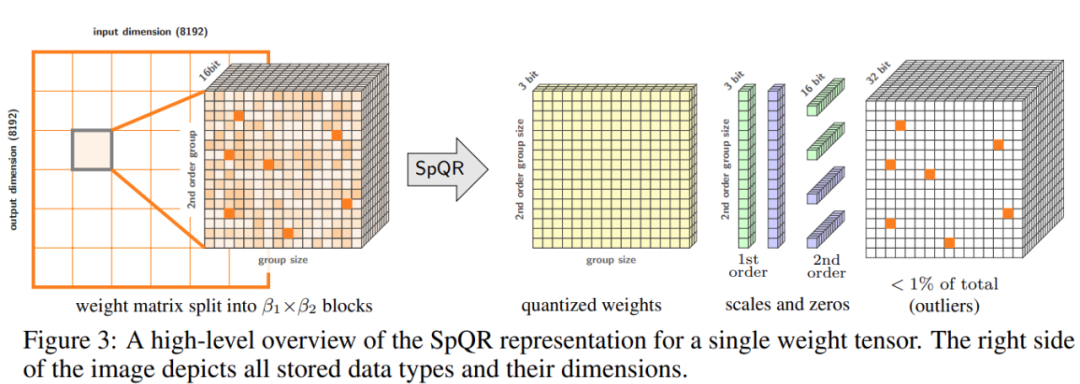

预训练大语言模型(LLM)在特定任务上的性能不断提高,随之而来的是,假如 prompt 指令得当,其可以更好的泛化到更多任务,很多人将这一现象归功于训练数据和参数的增多,然而最近的趋势表明,研究者更多的集中在更小的模型上,不过这些模型是在更多数据上训练而成,因而在推理时更容易使用。 举例来说,参数量…
-
「多模态LLM」最新介绍!数据、论文集直接打包带走


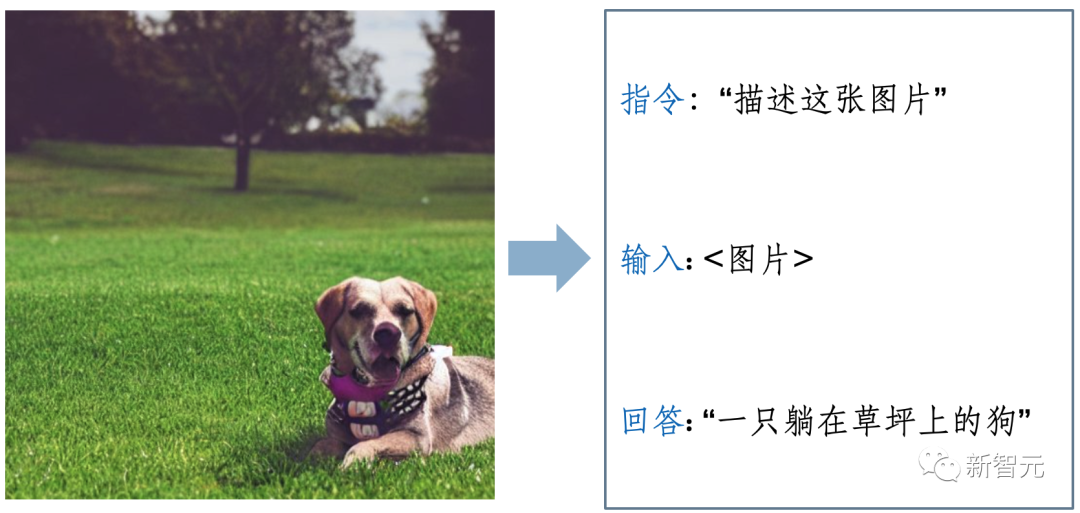

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 进展跟踪链接(awesome-mllm,实时更新):https://github.com/bradyfu/awesome-multimodal-large-language-models 近年来…
-
DeepMind用AI重写排序算法;将33B大模型塞进单个消费级GPU

目录: Faster sorting algorithms discovered using deep reinforcement learningVideo-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Unde…
-
CREATOR制造、使用工具,实现LLM「自我进化」


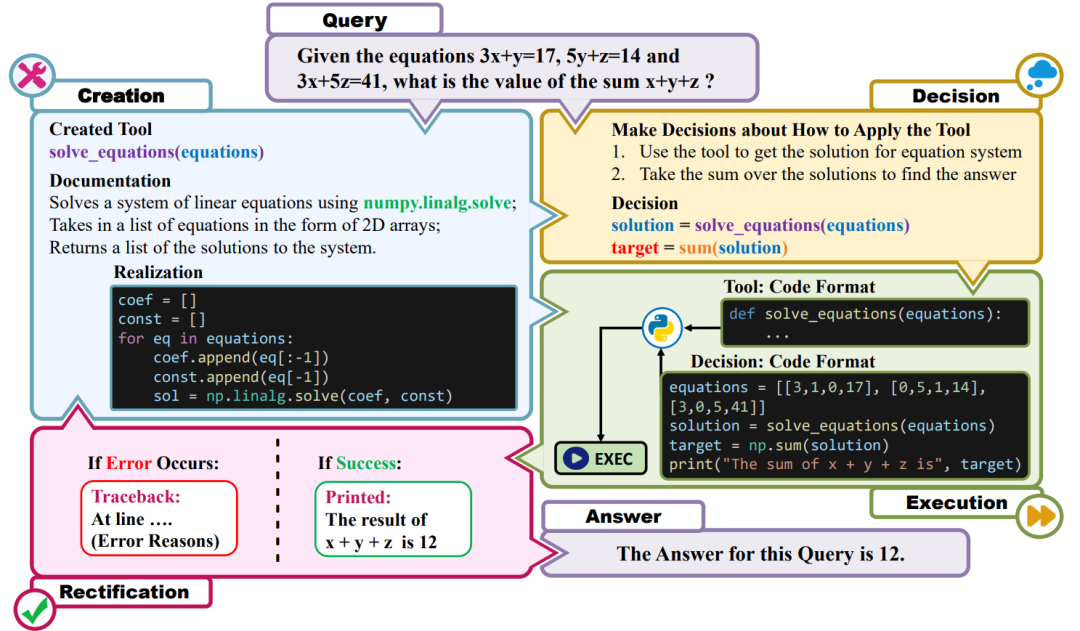

自古以来,工具的使用被视为区分人与其他物种的一大区别,也被视为是智能的一种根本体现。而当下,人工智能已不再局限于对工具的简单使用,它们已然能够根据问题创造性地建立自己的工具来寻求解决方案。在思维上,这代表着当下大模型已经能够掌握更高层次的抽象思维认知,并将其与具象思维划分,共同解决问题;而在能力上,…
-
650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了

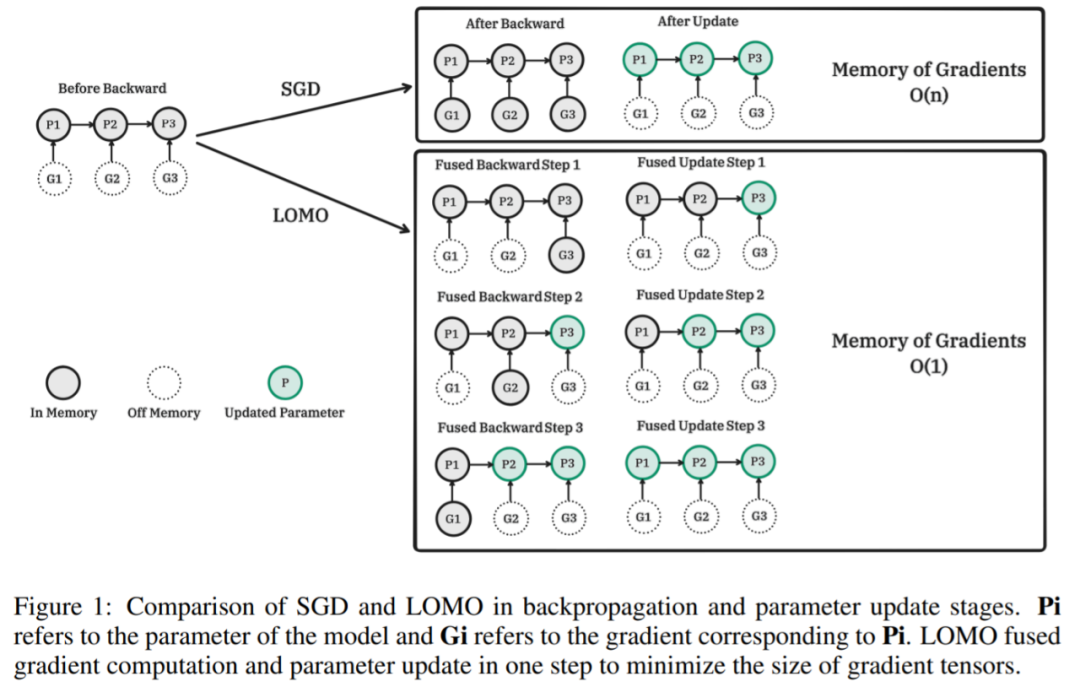

在大模型方向上,科技巨头在训更大的模型,学界则在想办法搞优化。最近,优化算力的方法又上升到了新的高度。 大型语言模型(LLM)彻底改变了自然语言处理(NLP)领域,展示了涌现、顿悟等非凡能力。然而,若想构建出具备一定通用能力的模型,就需要数十亿参数,这大幅提高了 NLP 研究的门槛。在 LLM 模型…
-
中国最强AI研究院的大模型为何迟到了
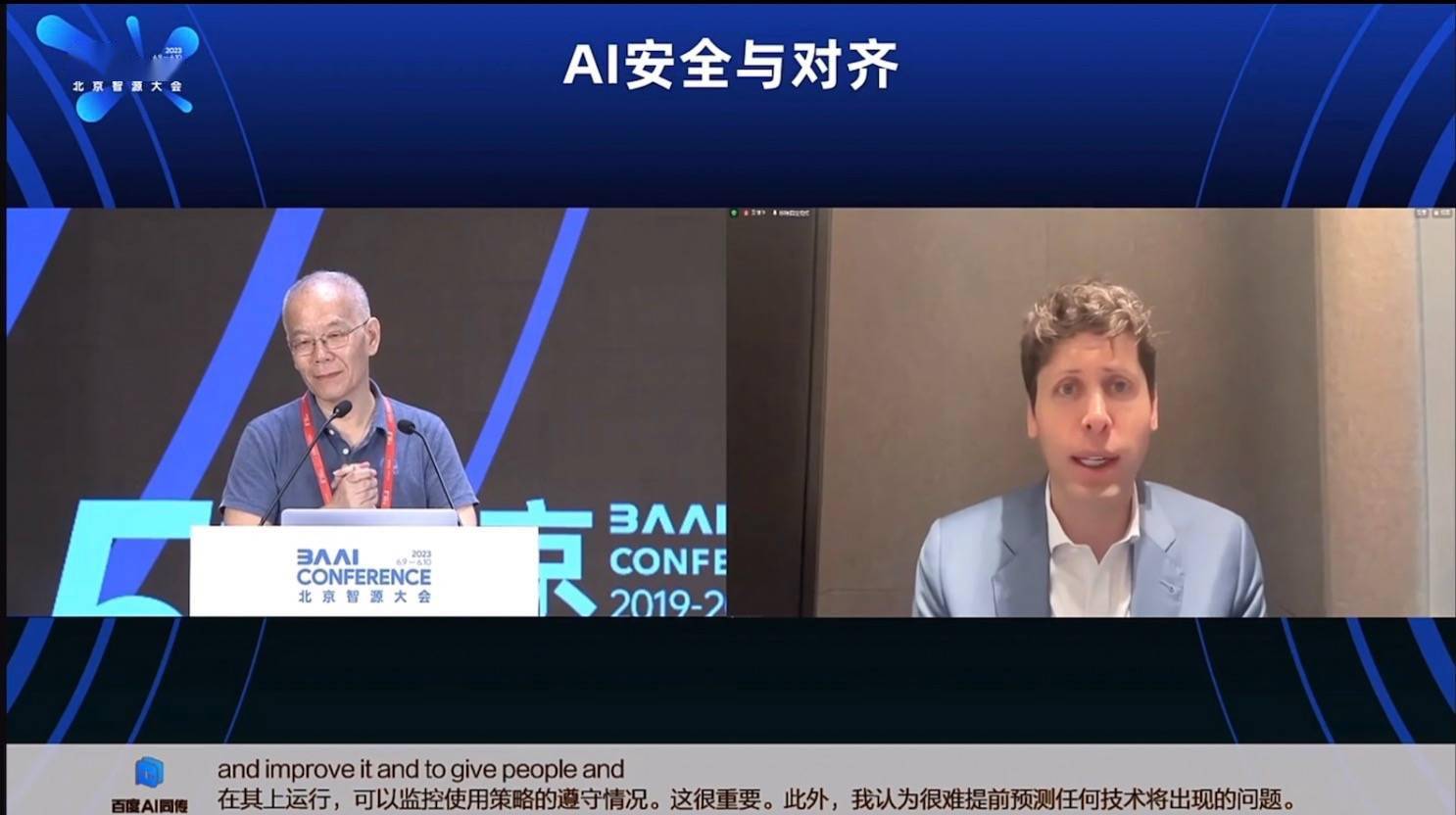


☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 出品|虎嗅科技组 作者|齐健 编辑|陈伊凡 头图|FlagStudio “OpenAI会再开源大模型吗?” 当智源研究院理事长张宏江向线上参加2023年智源大会的OpenAI首席执行官Sam A…
-
轻量级的深度学习框架Tinygrad


tinygrad是一种精简的深度学习库,它提供了一种简单易懂的方式来学习和实现神经网络。在本文中,我们将探讨tinygrad及其主要功能,以及它如何成为那些开始深度学习之旅的人的有价值的工具。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ …
-
羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品

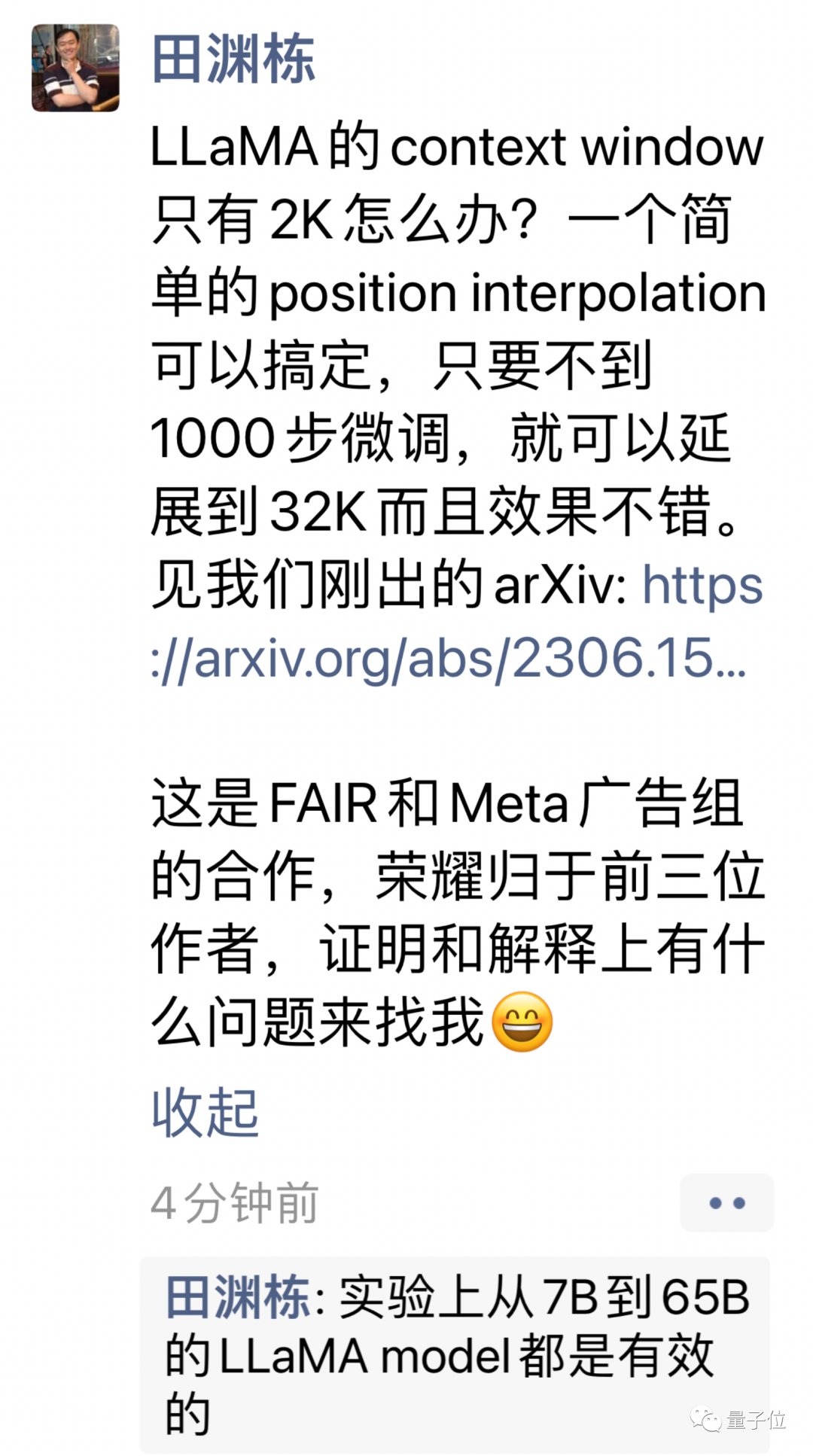

开源羊驼大模型llama上下文追平gpt-4,只需要一个简单改动! Meta AI这篇刚刚提交的论文表示,LLaMA上下文窗口从2k扩展到32k后只需要小于1000步的微调。 与预训练相比,成本忽略不计。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 …
