
模型
-
一阶优化算法启发,北大林宙辰团队提出具有万有逼近性质的神经网络架构的设计方法

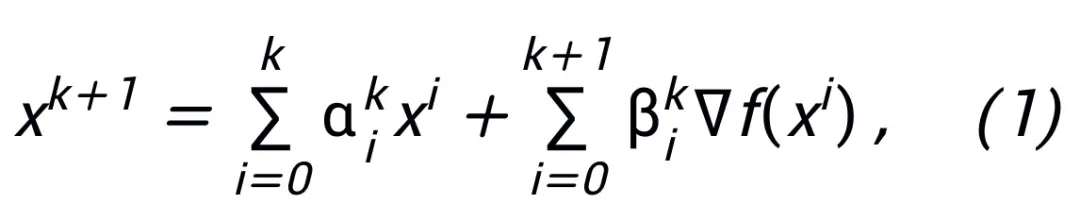
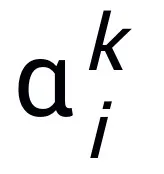
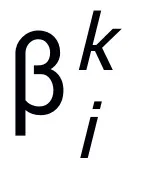
神经网络作为深度学习技术的基础已经在诸多应用领域取得了有效成果。在实践中,网络架构可以显著影响学习效率,一个好的神经网络架构能够融入问题的先验知识,确立网络训练,提高计算效率。目前,经典的网络架构设计方法包括人工设计、神经网络架构搜索(NAS)[1]、以及基于优化的网络设计方法 [2]。人工设计的网…
-
谷歌出手整顿大模型“健忘症”!反馈注意力机制帮你“更新”上下文,大模型无限记忆力时代将至
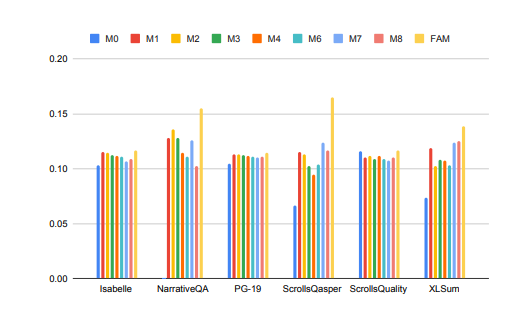



编辑|伊风 出品 | 51CTO技术栈(微信号:blog51cto) 谷歌终于出手了!我们将不再忍受大模型的“健忘症”。 TransformerFAM横空出世,放话要让大模型拥有无限记忆力! 话不多说,先来看看TransformerFAM的“疗效”: …
-
清华团队推出新平台:用去中心化AI打破算力荒
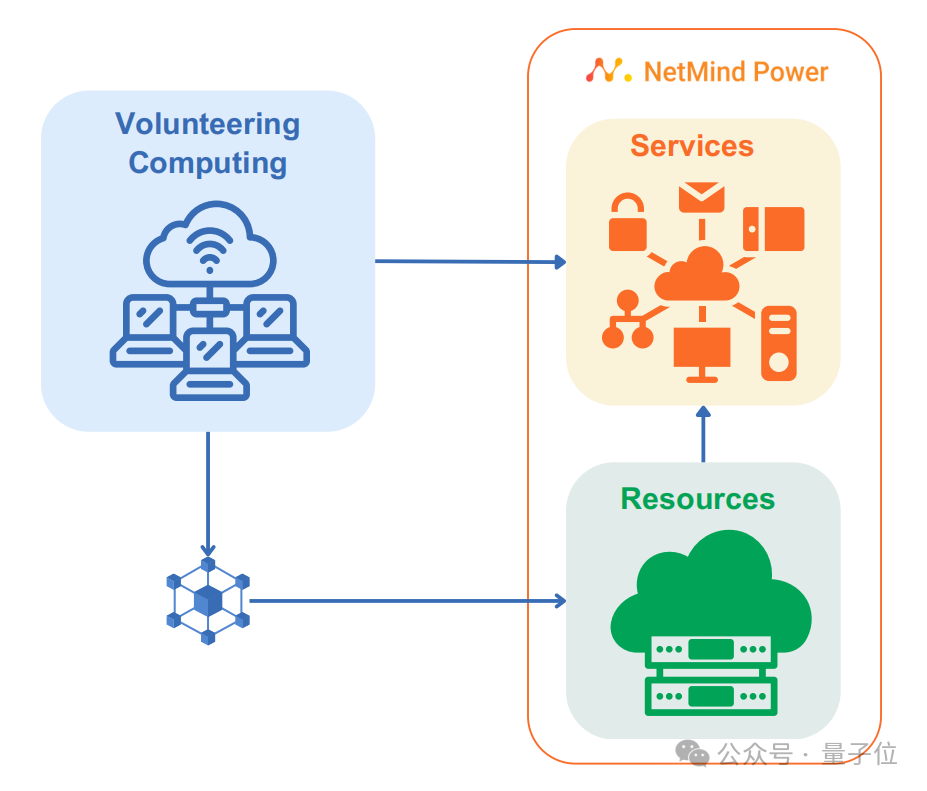
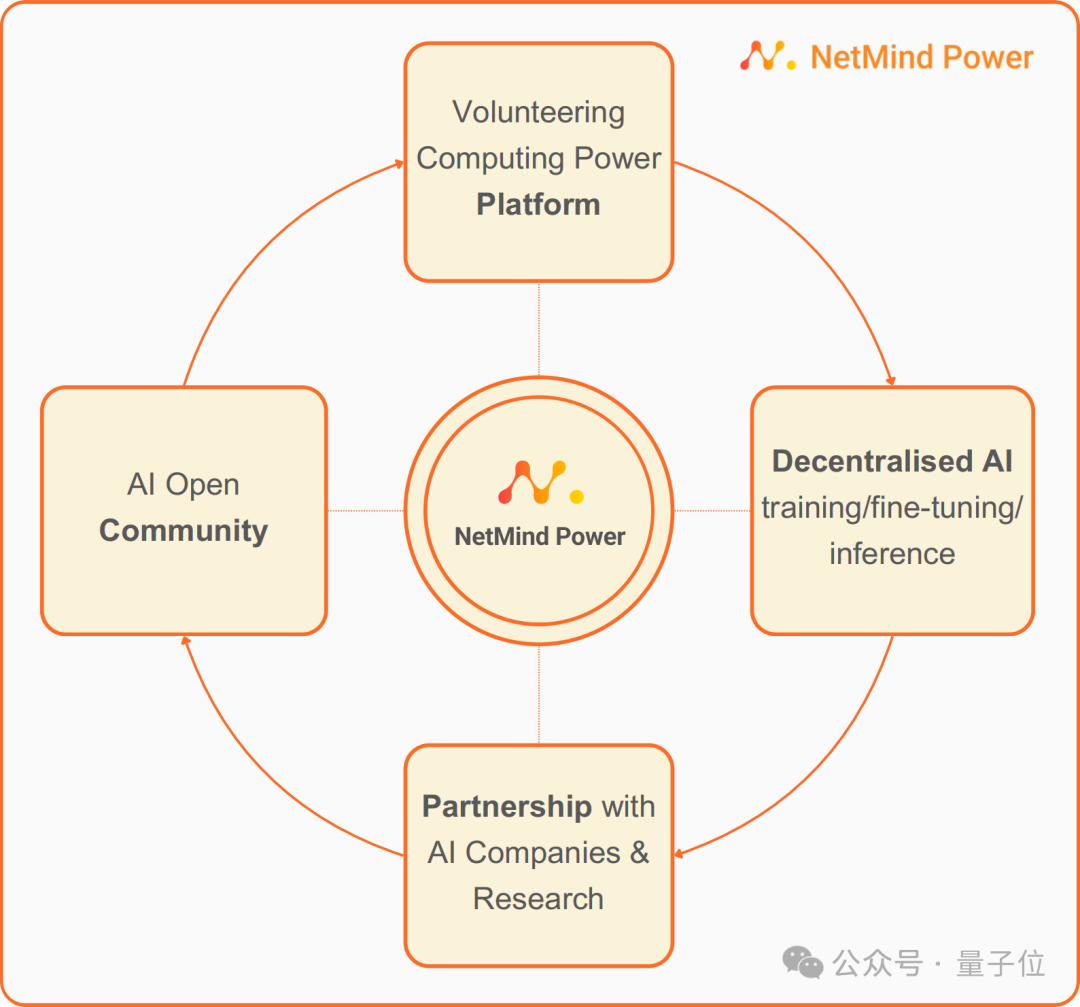


最近,一则数据点出了AI领域算力需求的惊人增长—— 根据业内专家的预估,OpenAI推出的Sora在训练环节大约需要约4200-10500张NVIDIA H100上训练1个月,并且当模型生成到推理环节以后,计算成本还将迅速超过训练环节。 照这个趋势发展下去,GPU的供给或许很难满足大模型持续的需求。…
-
用MoE横扫99个子任务!浙大等提出全新通用机器人策略GeRM


多任务机器人学习在应对多样化和复杂情景方面具有重要意义。然而,当前的方法受到性能问题和收集训练数据集的困难的限制。 这篇论文提出了GeRM(通用机器人模型),研究人员利用离线强化学习来优化数据利用策略,从演示和次优数据中学习,从而超越了人类演示的局限性。 ☞☞☞AI 智能聊天, 问答助手, AI 智…
-
大模型下B端前端代码辅助生成的思考与实践
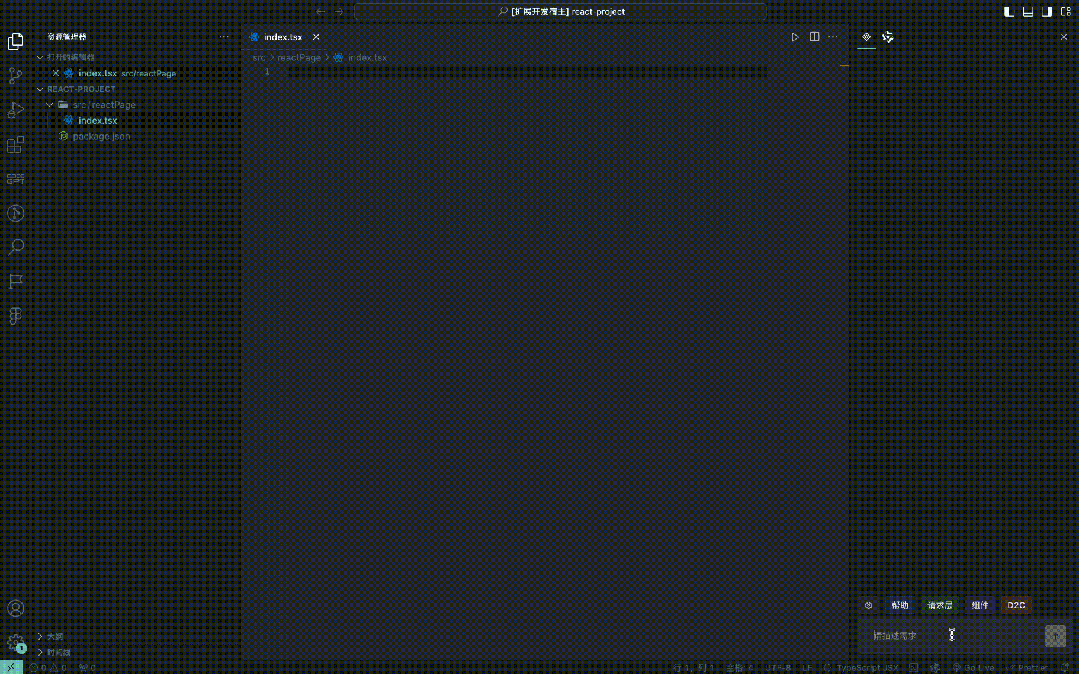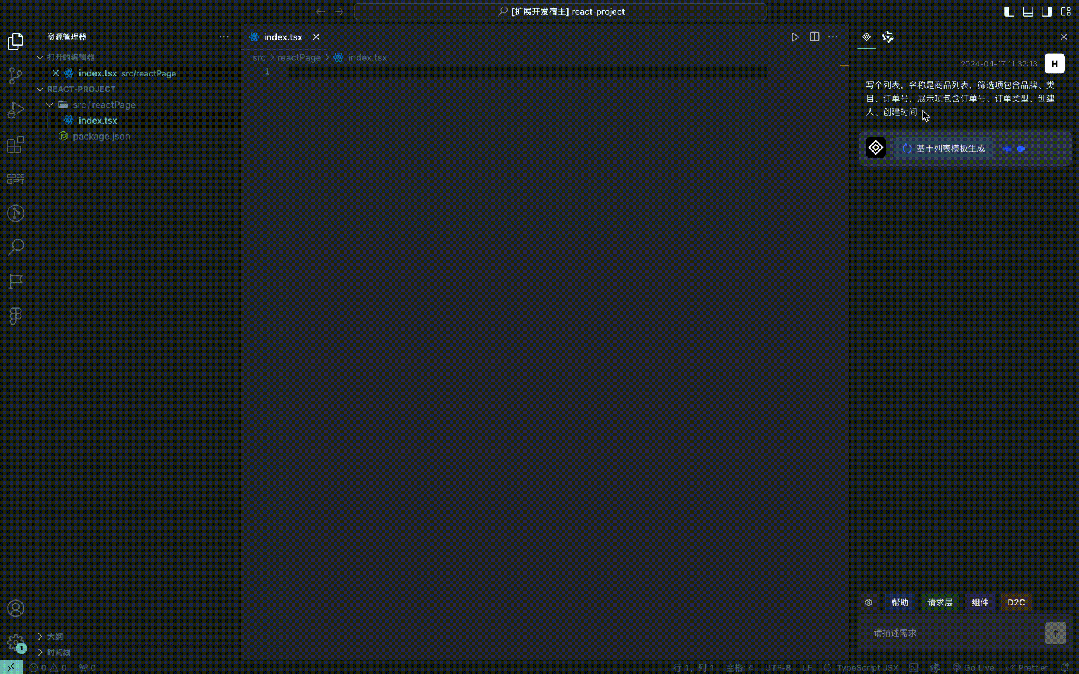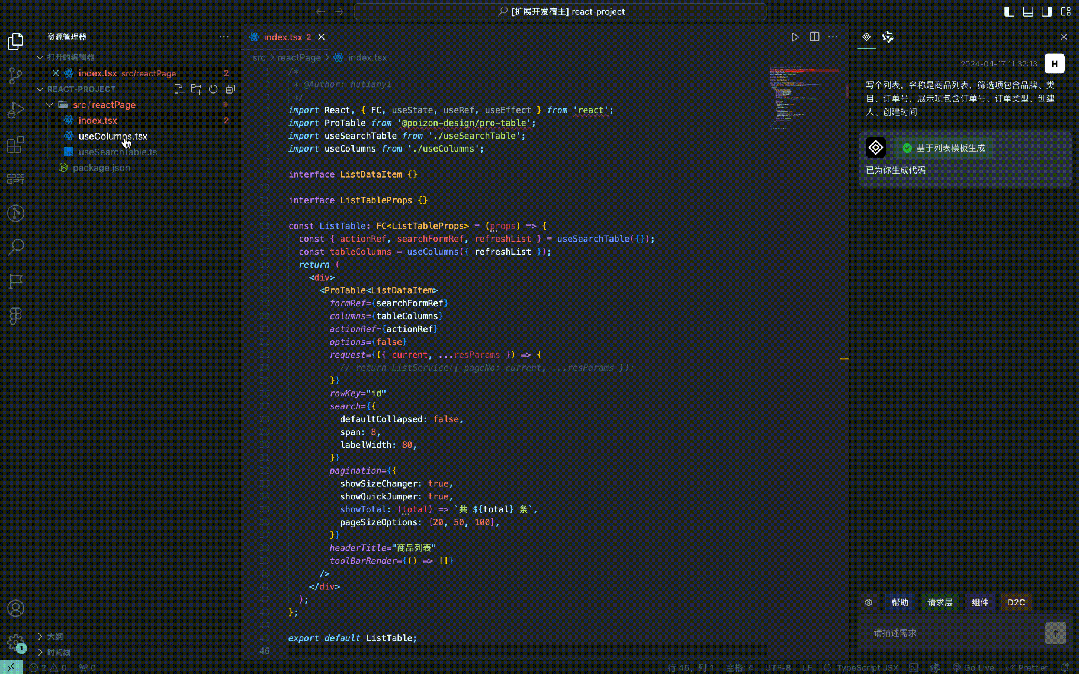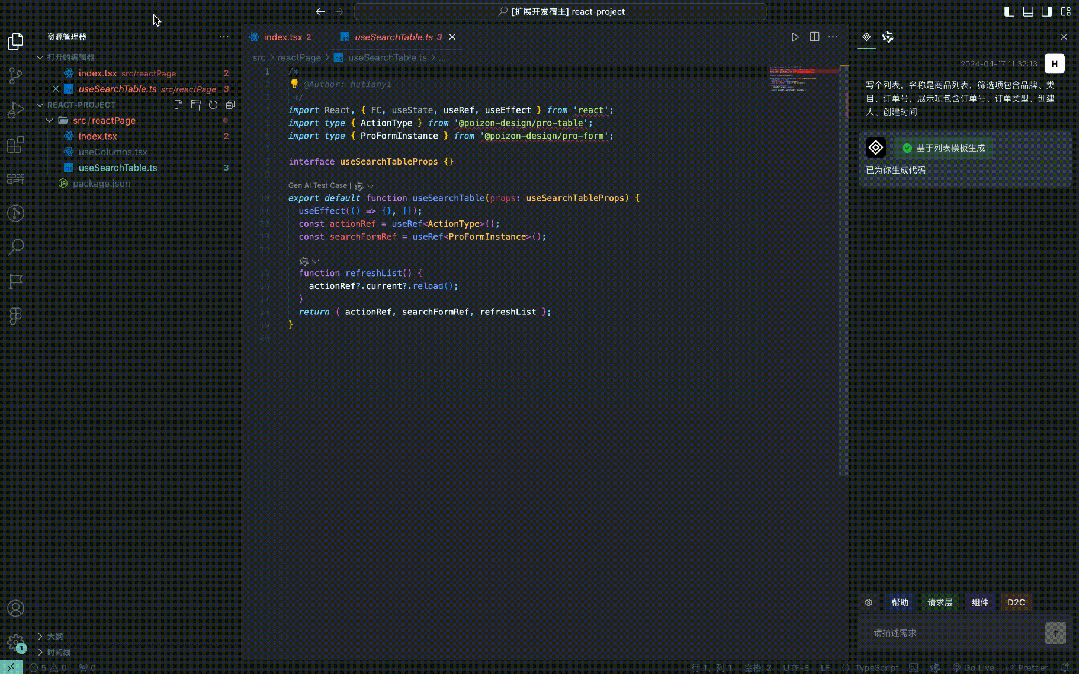

一、背景 重构工作中,代码规范:b端前端开发过程中开发者总会面临重复开发的痛点,很多crud页面的元素模块基本相似,但仍需手动开发,将时间花在简单的元素搭建上,降低了业务需求的开发效率,同时因为不同开发者的代码风格不一致,使得迭代时其他人上手成本较高。 AI代替简单脑力:AI大模型的不断发展,已经具…
-
CVPR 2024 | 面向真实感场景生成的激光雷达扩散模型


原标题:towards realistic scene generation with lidar diffusion models 论文链接:https://hancyran.github.io/assets/paper/lidar_diffusion.pdf 代码链接:https://lidar…
-
量化、剪枝、蒸馏,这些大模型黑话到底说了些啥?
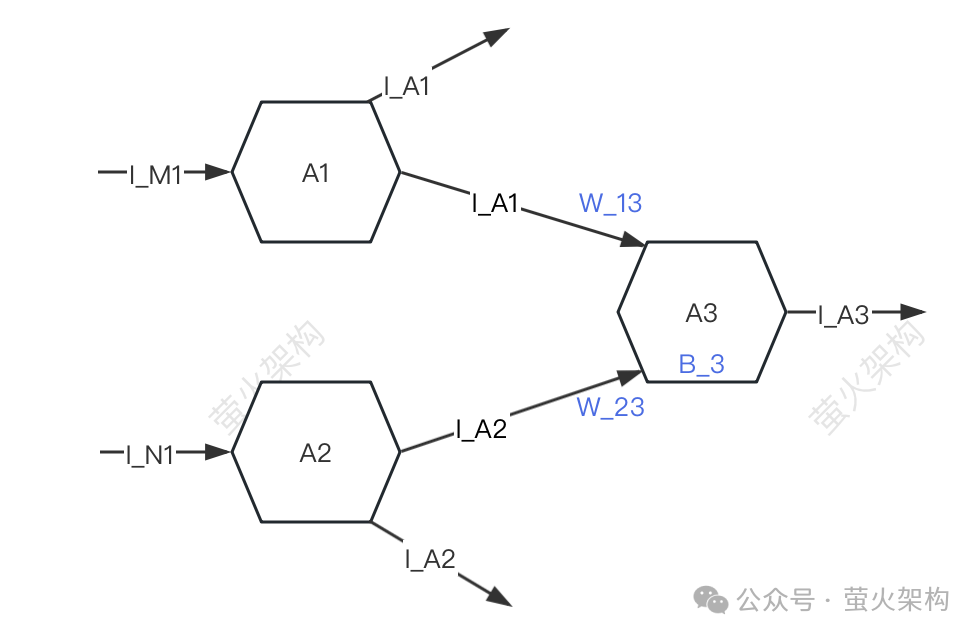
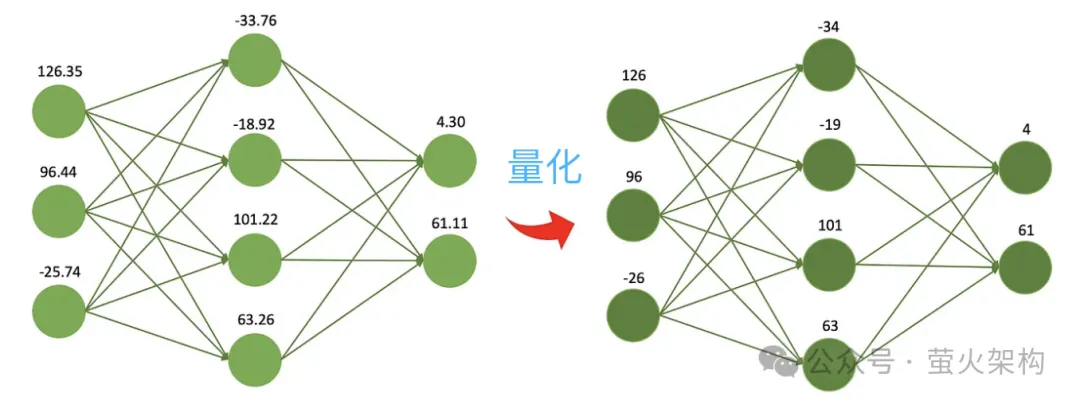
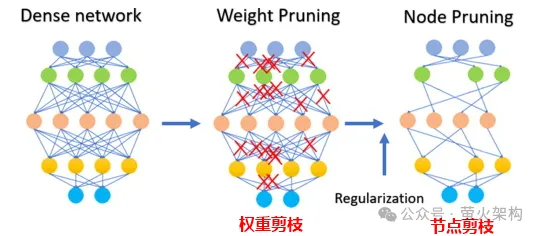

量化、剪枝、蒸馏,如果你经常关注大语言模型,一定会看到这几个词,单看这几个字,单看这几个字,我们很难理解它们都干了什么,但是这几个词对于现阶段的大语言模型发展特别重要。这篇文章就带大家来认识认识它们,理解其中的原理。 模型压缩 量化、剪枝、蒸馏,其实是通用的神经网络模型压缩技术,不是大语言模型专有的…
-
Docker三分钟搞定LLama3开源大模型本地部署

概述 llama-3(large language model meta ai 3)是由meta公司开发的大型开源生成式人工智能模型。它在模型结构上与前一代llama-2相比没有大的变动。 LLaMA-3模型分为不同规模的版本,包括小型、中型和大型,以适应不同的应用需求和计算资源。小型模型参参数规模…
-
FisheyeDetNet:首个基于鱼眼相机的目标检测算法
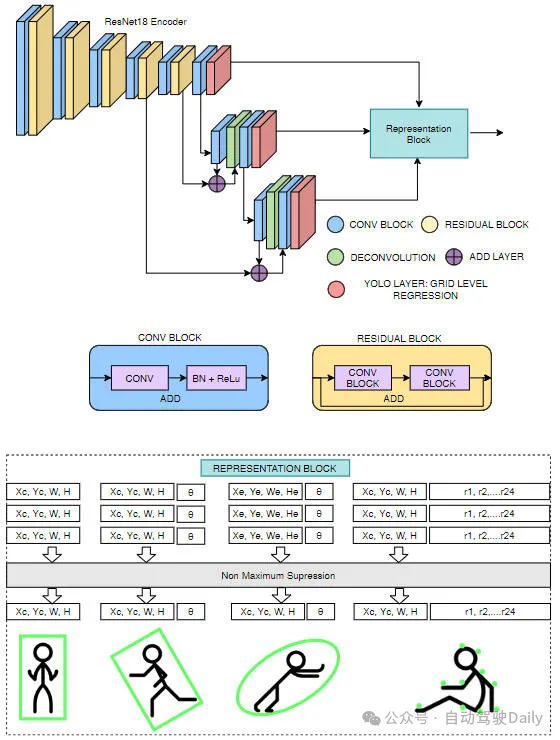

目标检测在自动驾驶系统当中是一个比较成熟的问题,其中行人检测是最早得以部署算法之一。在多数论文当中已经进行了非常全面的研究。然而,利用鱼眼相机进行环视的距离感知相对来说研究较少。由于径向畸变大,标准的边界框表示在鱼眼相机当中很难实施。为了缓解上述描述,我们探索了扩展边界框、椭圆、通用多边形设计为极坐…
-
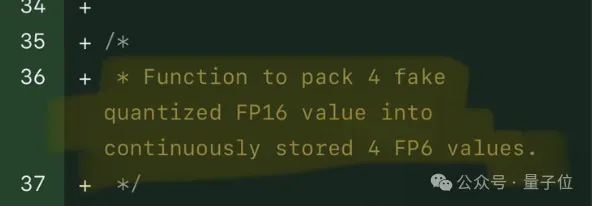
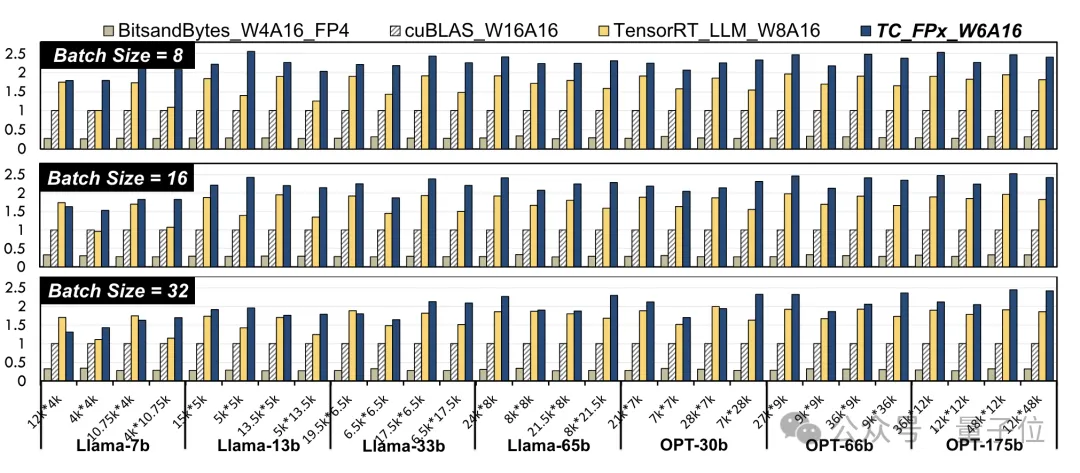
单卡跑Llama 70B快过双卡,微软硬生生把FP6搞到了A100里 | 开源

fp8和更低的浮点数量化精度,不再是h100的“专利”了! 老黄想让大家用INT8/INT4,微软DeepSpeed团队在没有英伟达官方支持的条件下,硬生生在A100上跑起FP6。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 测试结果表明…
