
内存占用
-
什么是Windows内存压缩? win10/11系统启用和禁用内存压缩的教程

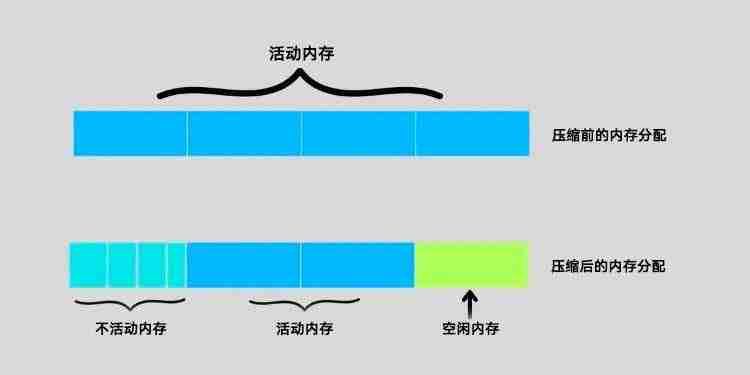

windows 内存压缩:利弊权衡内存压缩是一种技术,可让 windows 压缩计算机内存中未使用的数据。这可能会提高性能,因为有更多可用的 ram 来运行应用程序。然而,压缩也可能增加 cpu 负载,从而降低某些情况下系统的整体速度。了解 windows 内存压缩的潜在好处和缺点非常重要。本文将深…
-
Linux下Node.js日志分析工具推荐
在linux环境下,node.js的日志分析工具有很多,以下是一些常用的工具: Glogg: 特点:Glogg是一个跨平台的日志分析工具,使用Rust底层优化和零内存加载技术,能够实现性能突破。它支持磁盘级流式处理,可以秒级加载大文件,内存占用稳定在100MB以内。Glogg还提供双窗口智能交互、跨…
-
Java中Deque接口及ArrayDeque使用
答案:Deque是Java中支持两端操作的线性集合,ArrayDeque为其高效实现,适用于栈、队列及双端队列场景。 在Java中,Deque(双端队列)是一种允许从两端插入和删除元素的线性集合。它扩展了Queue接口,提供了更灵活的操作方式,既可以作为队列使用,也可以作为栈来操作。ArrayDeq…
-
RNN模型挑战Transformer霸权!1%成本性能比肩Mistral-7B,支持100+种语言全球最多


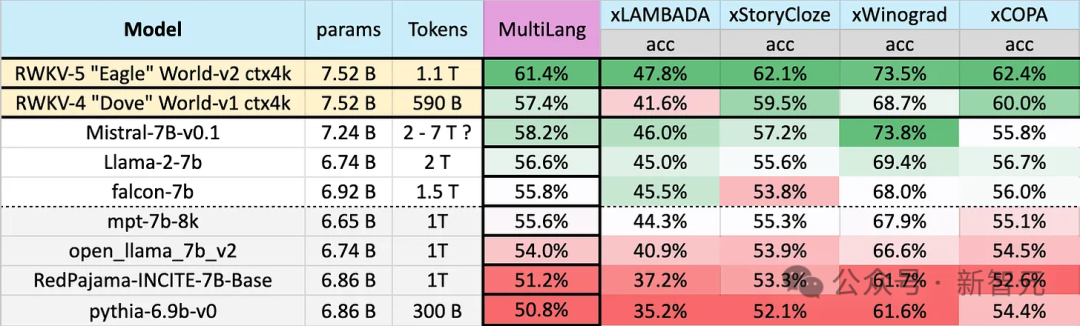

在大模型内卷的同时,transformer的地位也接连受到挑战。 近日,RWKV发布了Eagle 7B模型,基于最新的RWKV-v5架构。 Eagle 7B在多语言基准测试中脱颖而出,在英语测试中与顶尖模型不相上下。 同时,Eagle 7B用的是RNN架构,相比于同尺寸的Transformer模型,…
-
只需少量计算和内存资源即可运行的小型 Llama 大模型

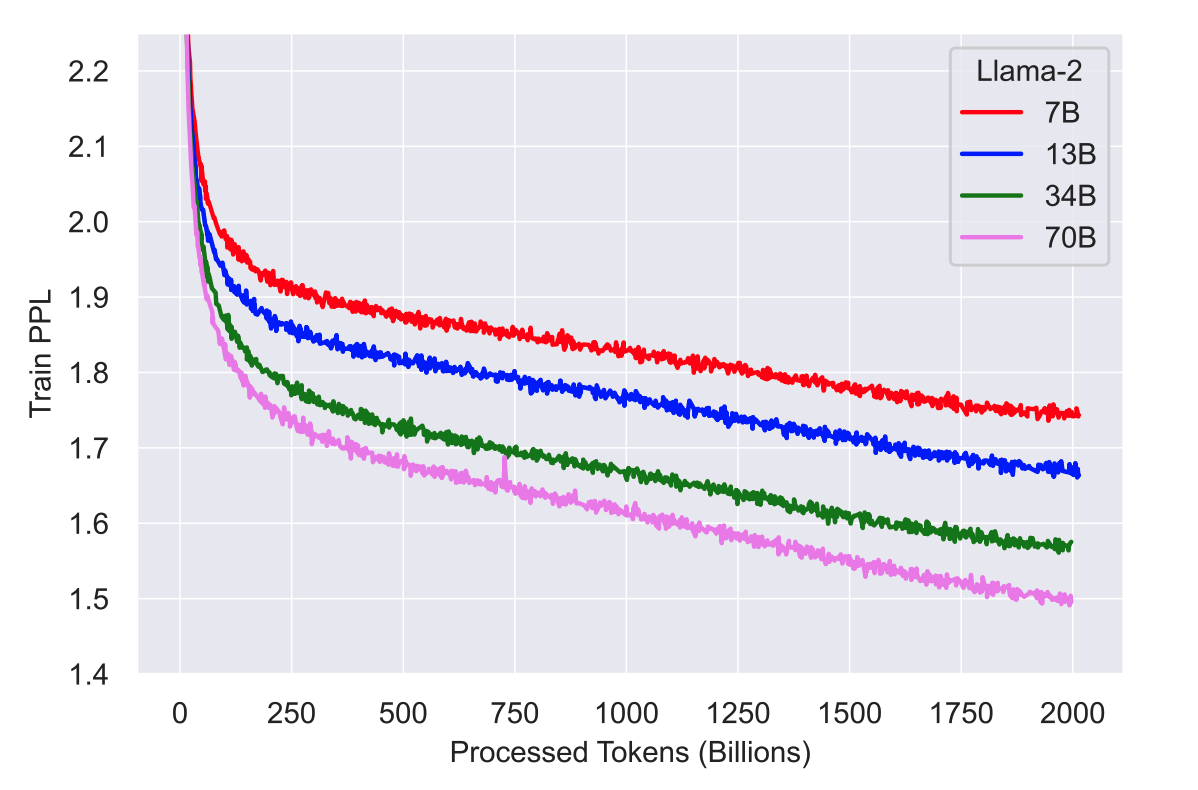
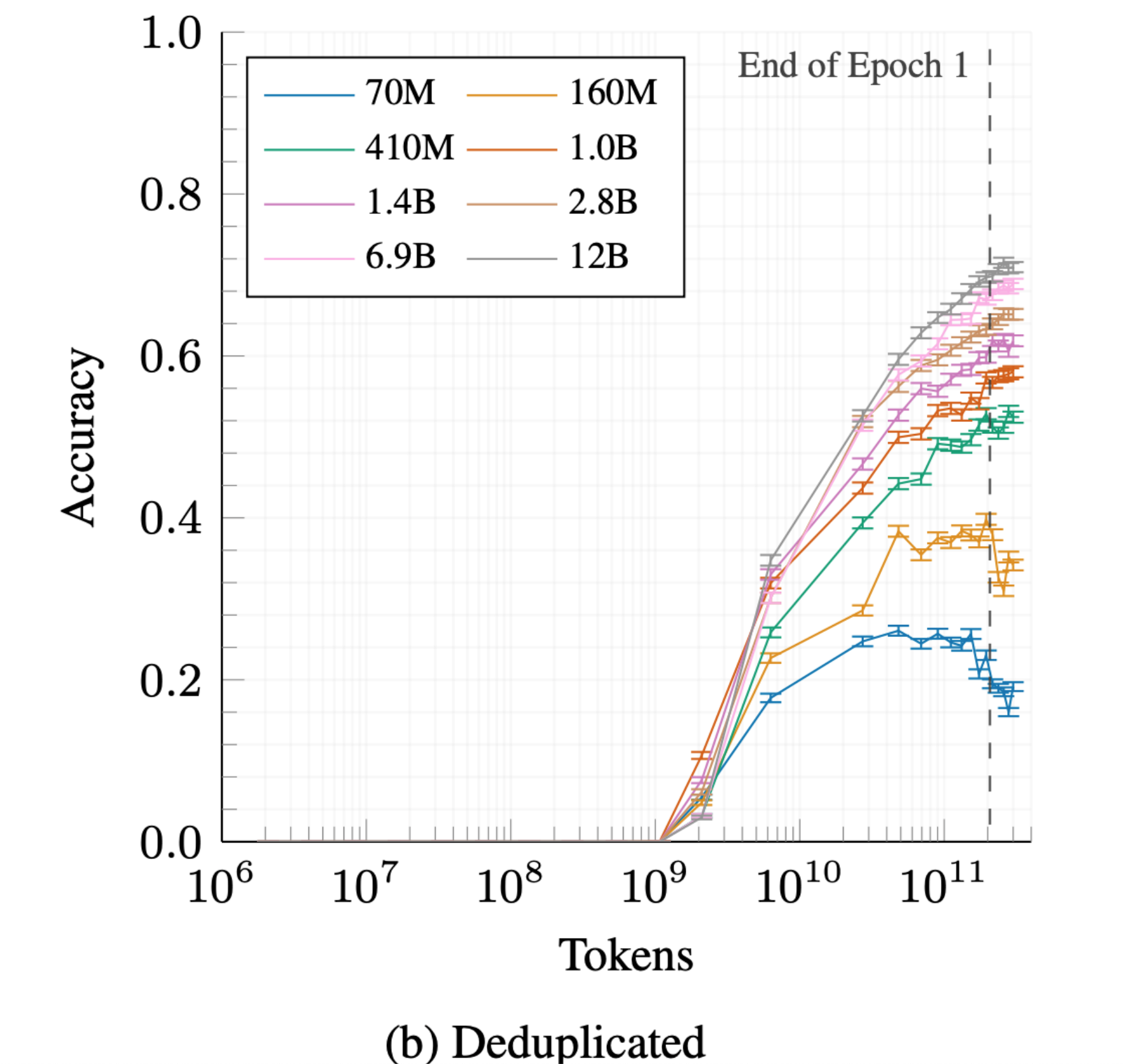
背景介绍 在当前信息量爆炸的时代,语言模型的训练日益变得复杂和困难。为了培训一个高效的语言模型,我们需要大量的计算资源和时间,这对很多人来说是不切实际的。同时,我们也面临着如何在有限的内存和计算资源下运用大型语言模型的挑战,尤其是在边缘设备上。 今天要给大家推荐一个 GitHub 开源项目 jzha…
-
百度地图导航过程中闪退如何处理
答案:百度地图闪退需从软件、系统、硬件排查。先更新应用版本或地图包,清除缓存或数据,检查权限与内存占用,排除信号干扰与供电问题,必要时恢复出厂设置或联系官方售后解决。 百度地图在导航时闪退,确实很影响使用体验。这问题通常不是单一原因造成的,需要从软件、系统和硬件几个方面来排查解决。 检查并更新软件版…
-
使用GaLore在本地GPU进行高效的LLM调优
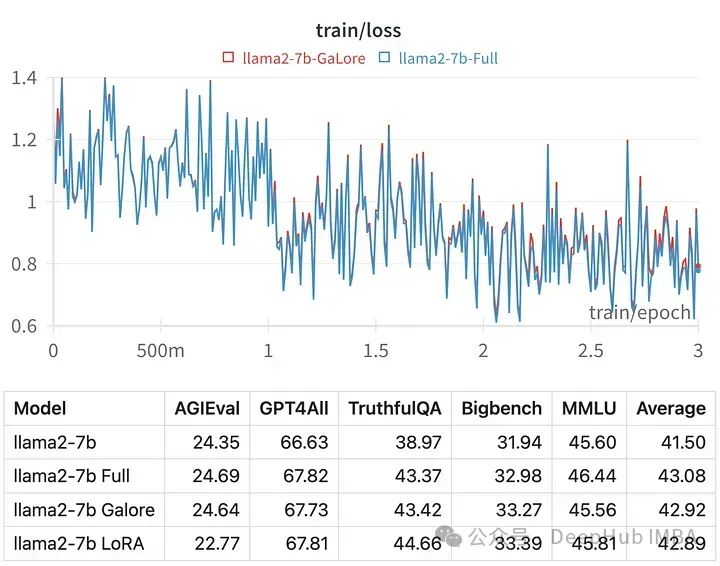



训练大型语言模型(llm)是一项计算密集型的任务,即使是那些“只有”70亿个参数的模型也是如此。这种级别的训练需要的资源超出了大多数个人爱好者的能力范围。为了弥补这一差距,出现了低秩适应(lora)等参数高效方法,使得在消费级gpu上可以对大量模型进行微调。 GaLore是一种创新方法,它采用优化参…
-
CVPR 2024 | 分割一切模型SAM泛化能力差?域适应策略给解决了

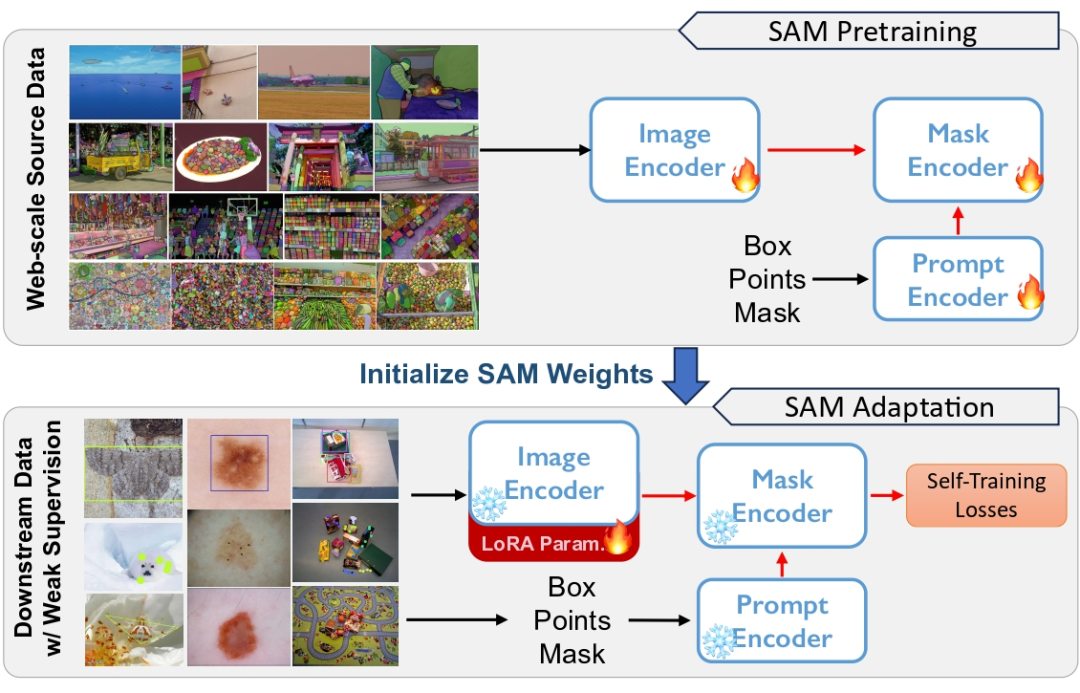

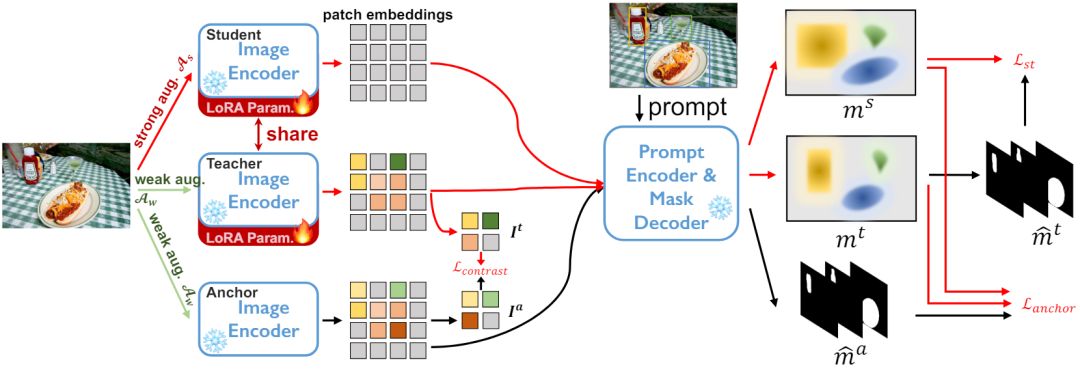
第一个针对「Segment Anything」大模型的域适应策略来了!相关论文已被CVPR 2024 接收。 引言 大语言模型(LLMs)的成功激发了计算机视觉领域探索分割基础模型的兴趣。这些基础分割模型通常通过 Prompt Engineer 来进行 zero/few 图像分割。其中,Segmen…
-
OpenSSL在Debian中的性能优化
OpenSSL是一个开源的安全库,提供了广泛的安全协议、加密算法和SSL/TLS协议,保障网络通信安全。在Debian系统中,通过以下几种方法可以实现OpenSSL性能的优化: 确保OpenSSL版本最新 通过以下命令更新Debian系统上的OpenSSL: sudo apt-get updates…
-
直接扩展到无限长,谷歌Infini-Transformer终结上下文长度之争

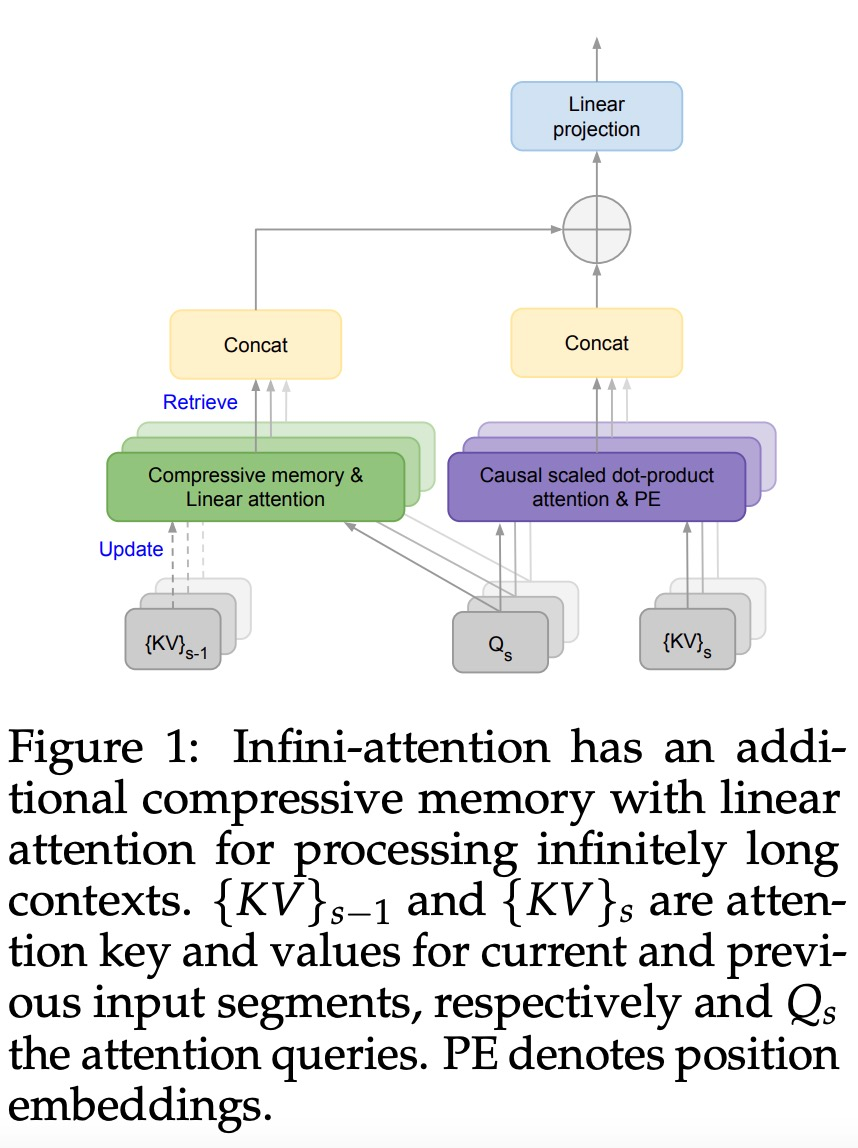
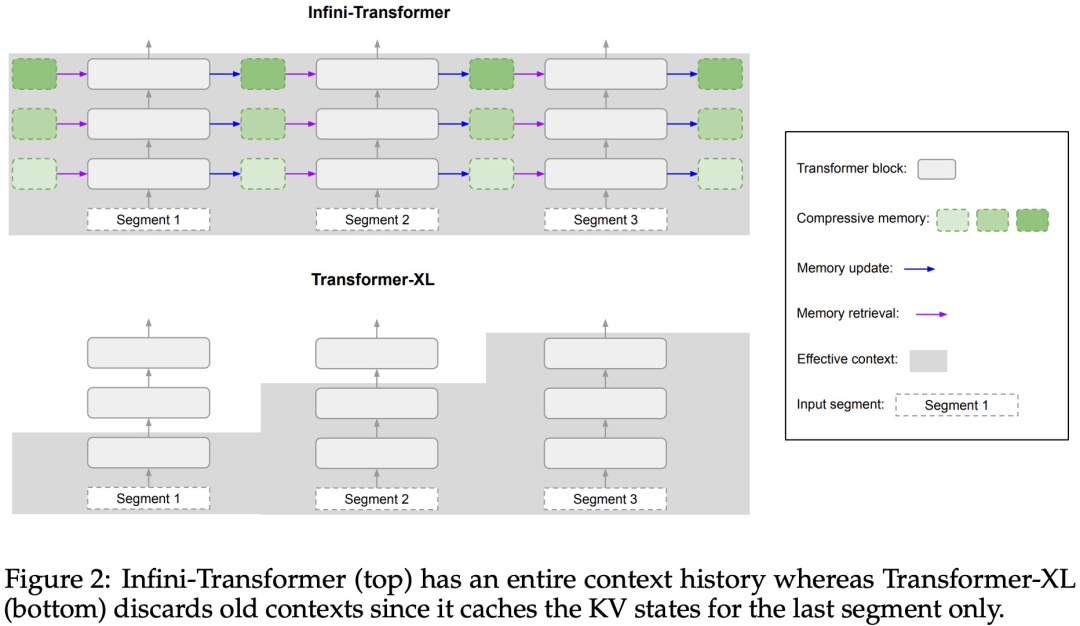

不知 Gemini 1.5 Pro 是否用到了这项技术。 谷歌又放大招了,发布下一代 transformer 模型 infini-transformer。 Infini-Transformer 引入了一种有效的方法,可以将基于 Transformer 的大型语言模型 (LLM) 扩展到无限长输入,而…



