
爬虫
-
【爬虫军火库】Windows创建计划任务定时执行Python脚本
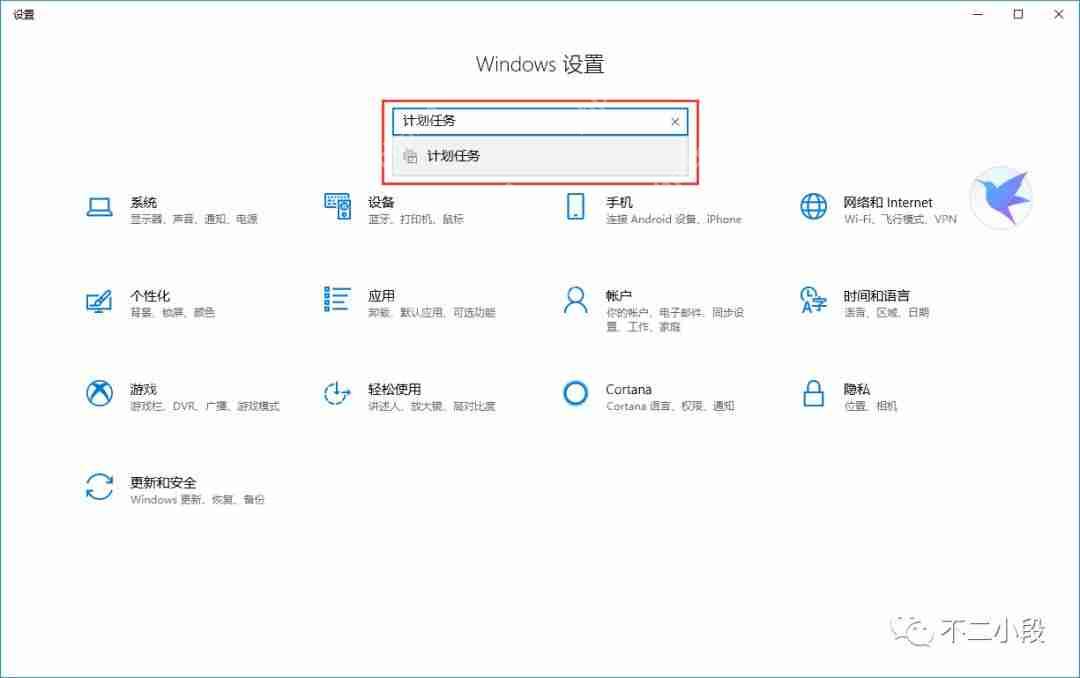
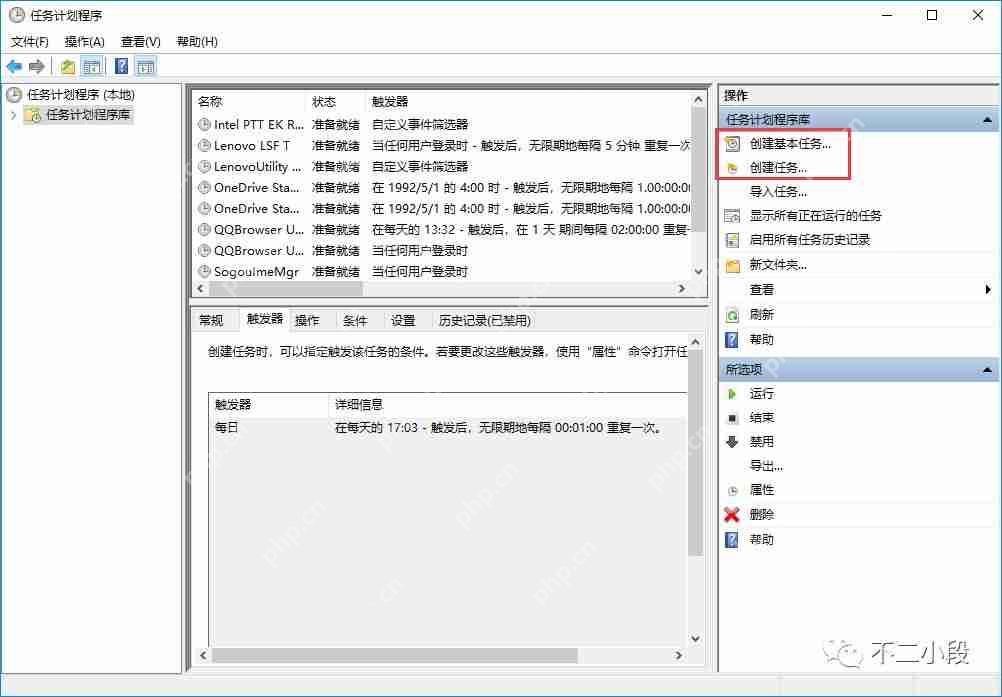
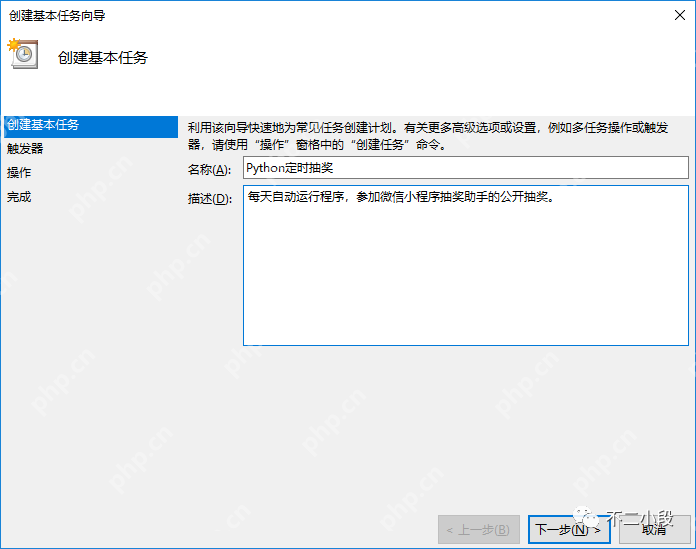
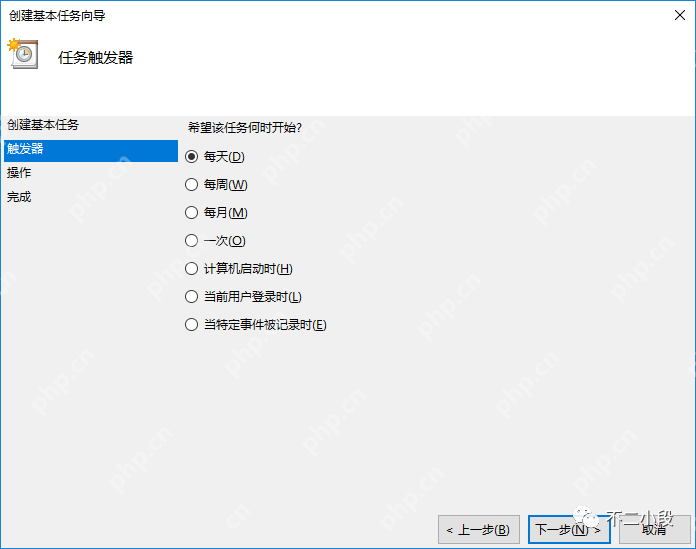
上次我们分享了如何使用python编写自动参与抽奖助手抽奖的代码,并介绍了在linux服务器上的部署方法(python定时自动参与抽奖助手抽奖)。然而,并非所有人都拥有远程服务器或熟悉linux操作系统,因此今天我们将探讨如何在windows系统上设置定时任务。 与Linux系统上使用crontab…
-
Scrapy CSS选择器技巧:提取未直接包裹在标签中的文本数据




本文深入探讨了如何使用scrapy的css选择器精确提取html中未直接包裹在独立标签内的文本数据,特别是当目标数据以文本节点形式存在时。通过结合`::text`伪元素、`getall()`方法以及正则表达式,我们能够有效定位并清洗出所需数值,克服了传统选择器可能遇到的挑战,确保数据抓取的准确性与鲁…
-
使用 Selenium 和 Python 下载 JavaScript 渲染的图片


本文旨在提供一种使用 Selenium 和 Python 下载由 JavaScript 动态渲染的网页图片的方法。 针对图片URL为标准URL或Base64编码的情况,分别提供解决方案。通过结合 Selenium 的页面加载能力和 requests 库或 base64 库的数据处理能力,可以有效地从…
-
Scrapy请求头部处理机制与反爬挑战:深度解析与调试局限


scrapy在发送http请求时,会对请求头部进行标准化处理,包括字母大小写转换和字母顺序排序。这种默认行为可能导致爬虫被网站的反爬机制识别,尤其是在需要精确控制请求字节流的场景下。当前scrapy缺乏内置的字节级调试功能来检查原始发送数据,给调试带来了挑战,用户需了解其内部机制以应对复杂的反爬策略…
-
使用 Beautiful Soup 从非结构化 HTML 中高效提取特定文本


本文详细介绍了如何利用 python 的 beautiful soup 库,结合 css 选择器和 `stripped_strings` 方法,从非结构化 html 中精确提取特定标签(如包含 “ 标签的 “)内 “ 标签之后的文本内容。教程通过示例代码演示了如何解决常见的数据提取挑…
-
Swoole协程到底是什么意思


Swoole协程是PHP中通过用户态调度实现的轻量级并发机制,本质为可中断函数,在单线程内以协作式调度支持多任务“并行”。其核心特点包括用户态切换、低内存开销、同步写法但非阻塞执行,并自动将I/O操作协程化。例如同时请求两个API时,传统方式耗时约600ms,而协程可重叠等待时间,总耗时降至约300…
-
python gevent的原理分析


gevent通过greenlet实现轻量级协程,利用monkey patch将标准库函数替换为非阻塞版本,结合事件循环自动调度I/O操作,在单线程中以协作式多任务模拟并发,使开发者能用同步写法编写异步程序,适用于I/O密集型场景。 gevent 是一个基于协程的 Python 网络库,它使用 gre…
-
基于 Selenium 的 Python 脚本:无法选择并点击 span 元素


本文档旨在解决在使用 Selenium 和 Python 编写的自动化脚本中,无法找到并点击特定的 `span` 元素的问题。通过分析错误信息和相关代码,我们将探讨可能的原因,并提供相应的解决方案,帮助开发者成功定位并操作目标元素。 在使用 Selenium 进行网页自动化测试或爬虫开发时,经常会遇…
-
神马搜索如何优化搜索建议_提升神马搜索建议的实用方法
优化关键词布局、强化长尾词覆盖、提升网站结构与移动端适配,并开放爬虫权限提交站点地图,可有效提升神马搜索建议的精准性与实用性。 如果您在使用神马搜索时发现搜索建议不够精准或缺乏相关性,可能是由于关键词布局不合理或用户行为数据未被有效利用。以下是提升神马搜索建议实用性的具体方法: 本文运行环境:华为M…
-
百家号内容如何存档_百家号内容存档的方法与注意事项
1、可通过手动复制、网页另存为、第三方工具导出或云笔记同步四种方式对百家号内容进行系统存档,确保信息长期保存与高效管理。 如果您希望对已发布的百家号内容进行系统保存或备份,以便后续查阅或迁移使用,直接通过平台功能或辅助手段进行存档是必要操作。以下是实现内容存档的具体方法与注意事项: 一、手动复制保存…


