
pytorch
-
llama3怎么部署分布式系统_llama3分布式系统部署手册及容错机制保障




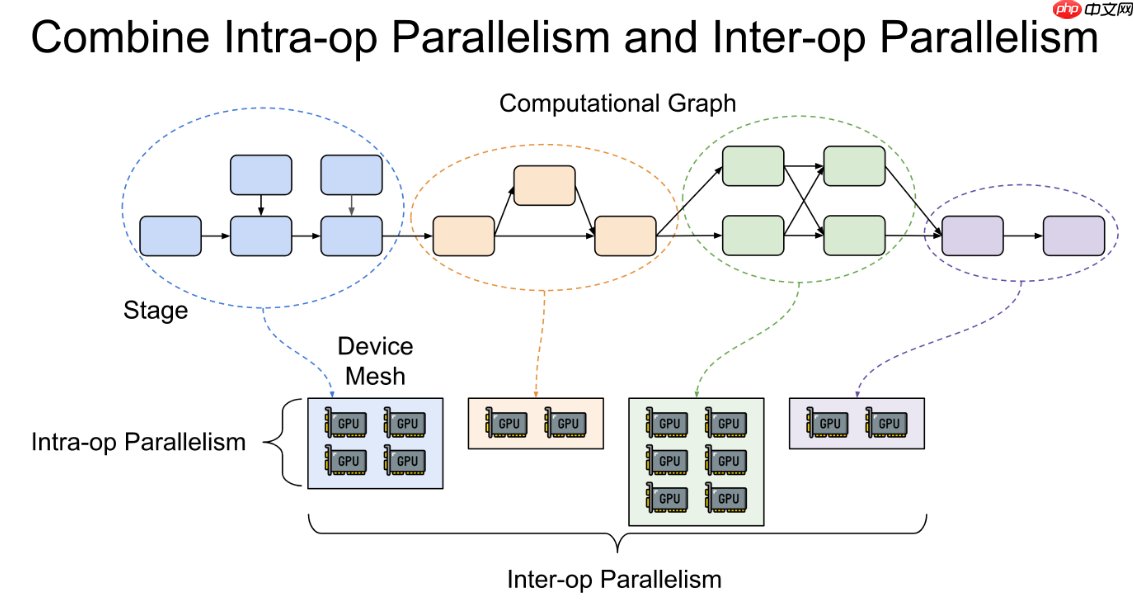
首先构建统一的分布式环境,配置深度学习框架、SSH免密登录、时钟同步和共享存储;接着根据硬件资源采用模型并行(Tensor Parallelism、Pipeline Parallelism)与数据并行(DDP)结合的策略,并应用ZeRO优化降低内存开销;随后通过启动脚本协调多节点任务,设置RANK与…
-
大模型时代的“积木”:算子到底解决了什么问题?


我是fanstuck,专注于将前沿技术以通俗易懂的方式呈现给每一位读者,持续追踪ai领域的最新动态与发展趋势。如果你对大模型的创新实践、人工智能的技术演进及其真实场景落地感兴趣,欢迎持续关注我的分享。 为什么“算子”值得你花时间了解? 当你只是调用现成模型、写写简单脚本或运行基础推理任务时,“算子”…
-
Cursor 2.0携自研模型Composer登场,编码速度提升4倍!
近日,ai编程工具cursor发布了2.0版本,带来两项重大更新:自研编码模型composer和用于并行协作多个智能体的新界面。这标志着cursor从“ai外壳”向“ai原生平台”的进化。此前,cursor只能使用claude、gpt等第三方模型,这虽为其起点,却也成了发展瓶颈。composer的发…
-
【大模型学习】现代大模型架构(一): 组注意力机制(GQA)和 RMSNorm

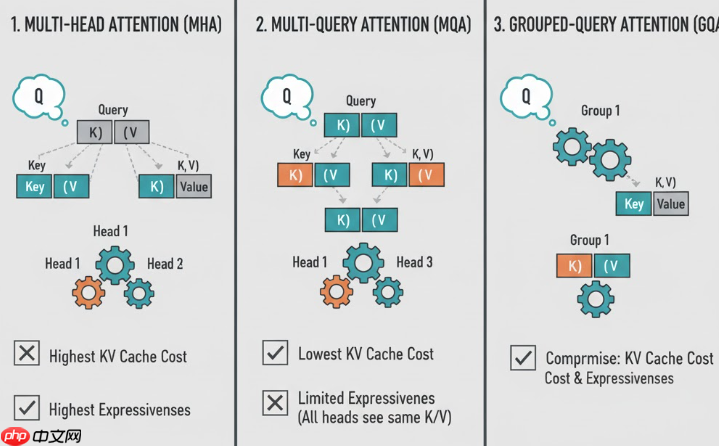
前言 ✍ 在大模型论文学习中,相信很多读者和笔者一样,一开始都会有一种感觉:“现在大模型架构都差不多,主要是数据和算力在堆积。”当笔者慢慢总结llama、qwen、deepseek这些模型架构的时候发现,在 attention、位置编码、ffn 与归一化 上,其实已经悄悄从经典 transforme…
-
深入解析 PyPTO Operator:以 DeepSeek‑V3.2‑Exp 模型为例的实战指南
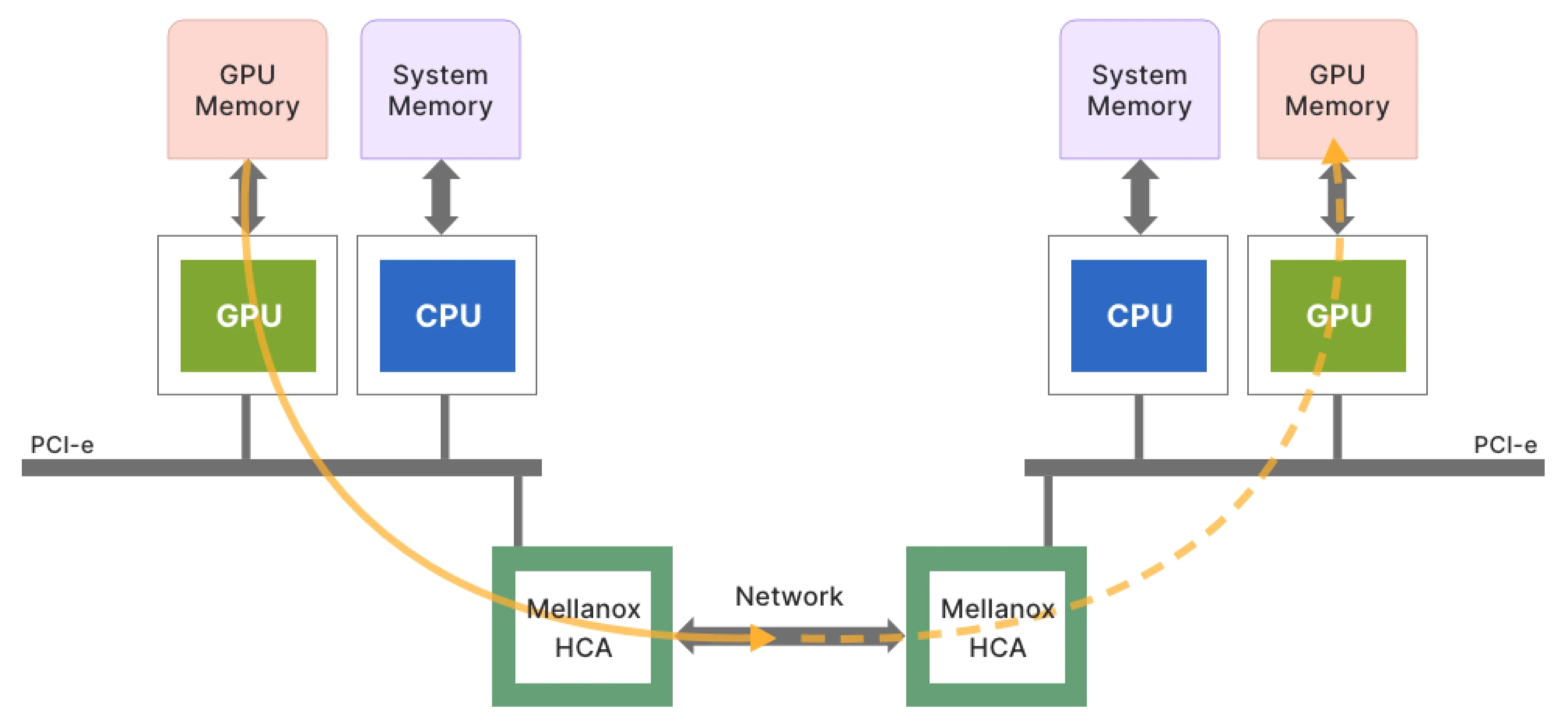
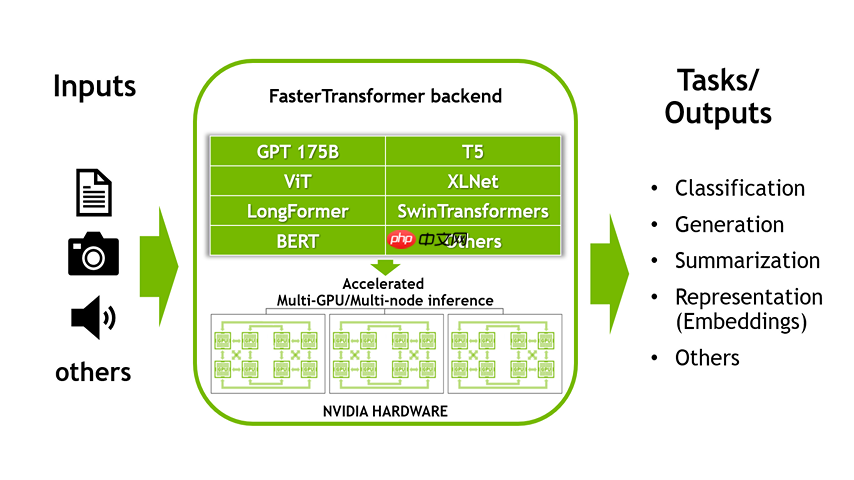
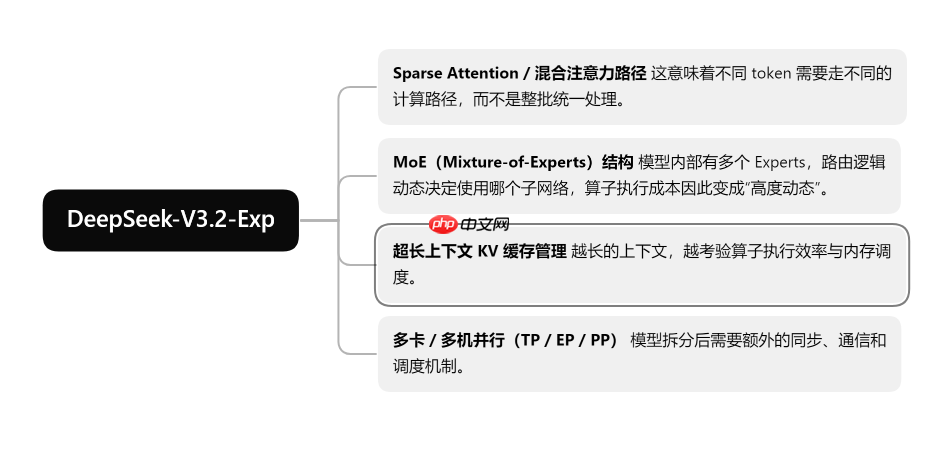
前言 在如今的大模型部署世界里,大家讨论得最多的往往是模型本身:参数规模、上下文长度、推理速度、吞吐表现……但只要真正踩过一次从“模型参数”到“实际落地推理服务”的坑,很快就能意识到,决定性能上限的其实并不是模型本身,而是躲在系统底层的那一层算子实现。尤其是在像 deepseek-v3.2-exp …
-
机器学习 | PyTorch简明教程上篇

前面几篇文章介绍了特征归一化和张量,接下来开始写两篇pytorch简明教程,主要介绍pytorch简单实践。 1、四则运算 import torcha = torch.tensor([2, 3, 4])b = torch.tensor([3, 4, 5])print(“a + b: “, (a + …
-
飞桨AIStudio如何创建项目_飞桨AIStudio项目创建步骤


首先登录AIStudio账户,访问官网并登录百度账号;进入“我的项目”后点击“创建项目”;填写项目名称、简介及可见性;选择框架版本与运行环境,配置CPU或GPU资源及存储空间;可选空项目或模板初始化;最后确认信息并创建,系统跳转至工作台验证文件结构与环境状态即可开始开发。 ☞☞☞AI 智能聊天, 问…
-
PyTorch vmap中动态张量创建的技巧与最佳实践


在使用%ign%ignore_a_1%re_a_1%的`torch.vmap`进行函数向量化时,如果在函数内部创建新的张量(如通过`torch.zeros`),并且该张量的形状不完全由批处理输入直接决定,可能会遇到`batchedtensor`兼容性问题。本文将深入探讨这一挑战,并提供一种优雅的解决…
-
掌握PyTorch模型保存与加载:从训练到部署的完整指南


pytorch模型加载时,需要先定义模型结构,再加载保存的state_dict参数。这是因为pytorch通常只保存模型参数而非整个模型对象,以避免python对象序列化问题。本文将详细介绍如何分离模型的训练、保存与加载推理过程,并通过示例代码演示这一标准实践,帮助用户高效复用预训练模型。 在PyT…
-
使用自定义特征提取器计算FID的常见陷阱与解决方案


本文深入探讨了在使用 `torchmetrics` 库计算 fid 时,将自定义 `nn.module` 作为特征提取器可能遇到的数据类型不匹配问题。通过分析 `runtimeerror: expected scalar type byte but found float` 错误,文章阐明了 pyt…

