
scrapy
-
python scrapy处理翻页的方法
答案:处理Scrapy翻页需根据分页机制选择方法。1. 用response.follow提取“下一页”链接递归爬取;2. 构造规则URL批量请求;3. 利用meta传递分类等上下文信息;4. 针对Ajax动态加载,分析API接口直接请求JSON数据。 在使用Python的Scrapy框架爬取数据时,…
-
python scrapy.Request发送请求的方式
Scrapy中通过scrapy.Request发送网络请求,核心参数包括url、callback、method、headers、body、meta、cookies和dont_filter;可使用FormRequest提交表单,response.follow()快捷跟进链接,实现灵活的爬虫控制流程。 …
-
python scrapy模拟登录的方法
答案:Scrapy模拟登录需分析登录流程,提取表单字段及隐藏参数如csrf_token,使用FormRequest.from_response提交登录信息,自动处理cookies和重定向;若存在动态token或验证码,则结合Playwright等工具模拟浏览器操作;登录后Scrapy通过Cookie…
-
scrapy怎么安装
scrapy安装教程:1、用“python –version pip –version”命令确保已安装Python和pip;2、在命令行中输入“pip install scrapy”命令来安装Scrapy;3、在命令行中输入“arduino scrapy version”命令…
-
在windows下如何新建爬虫虚拟环境和进行Scrapy安装
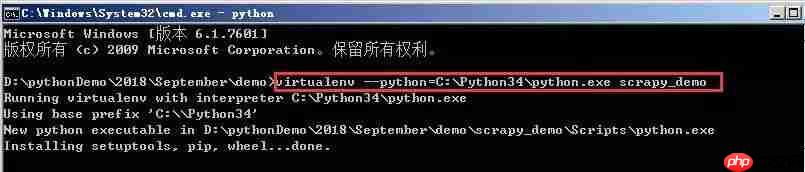
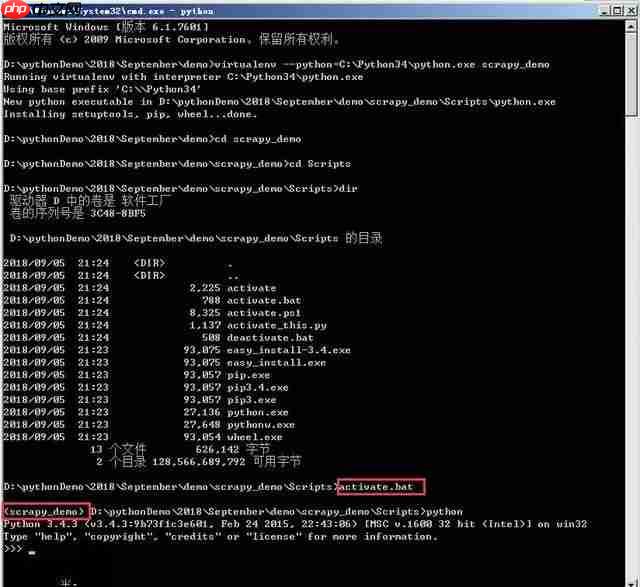
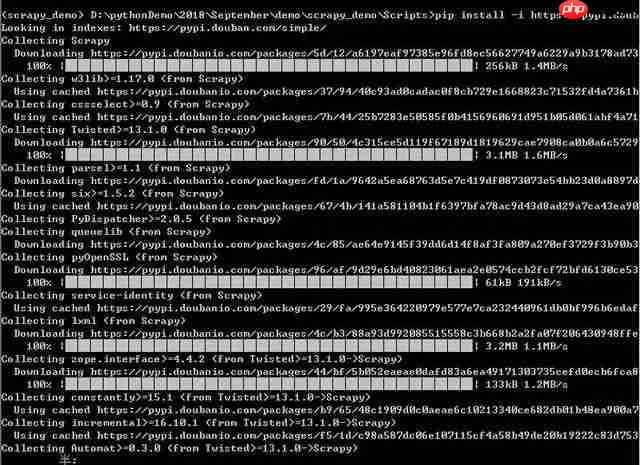
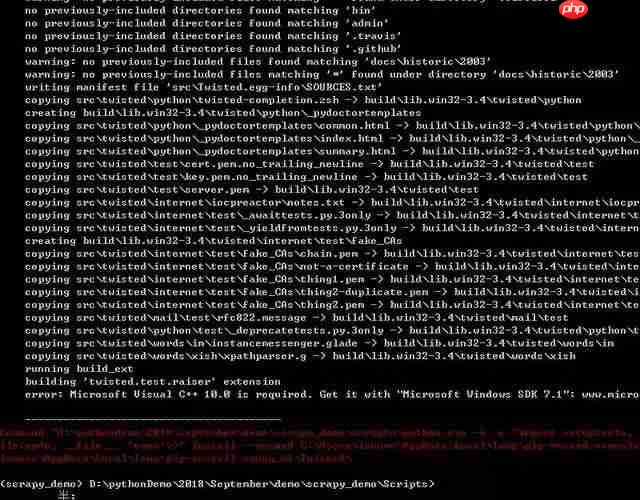
scrapy是一款由python开发的高效、高层次的屏幕抓取和网络抓取框架,用于从网站中提取结构化数据。scrapy之所以吸引人,是因为它是一个框架,用户可以根据自己的需求进行灵活的调整。scrapy的应用范围很广,包括数据挖掘、监控和自动化测试。 1、关于虚拟环境的创建,可以参考之前发布的两篇博文…




