
spark
-
初识Structured Streaming



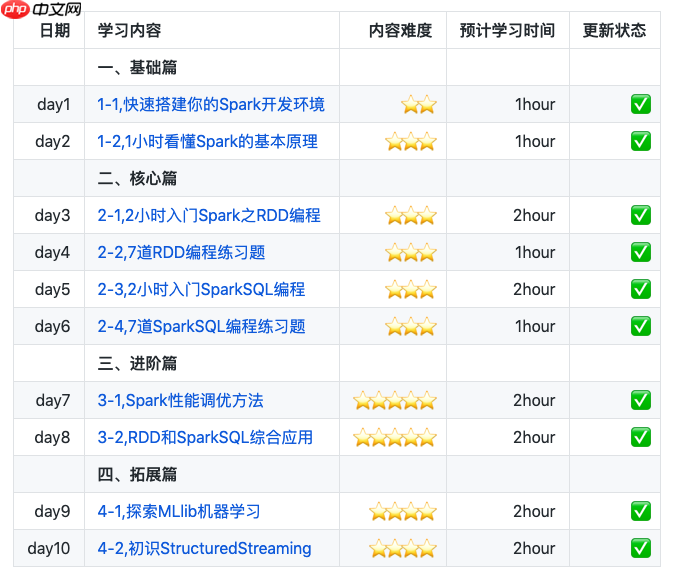
设想我们要设计一个交易数据展示系统,实时呈现比特币最近1s钟的成交均价。 我们可以通过交易数据接口以非常低的延迟获得全球各个比特币交易市场的每一笔比特币的成交价,成交额,交易时间。 由于比特币交易事件一直在发生,所以交易事件触发的交易数据会像流水一样源源不断地通过交易接口传给我们。 如何对这种流式数…
-
MySql和Spark比较分析:如何根据大数据处理需求选择合适的工具
随着互联网和物联网的快速发展,大数据的处理需求也越来越高,越来越多的企业开始关注和利用大数据来进行业务决策和优化。而在处理大数据时,选择合适的工具显得尤为重要。本文将就mysql和spark这两大数据处理工具进行比较分析,从而帮助企业选择合适的工具来处理大数据。 数据处理方式 MySql是一种关系型…
-
使用宝塔面板搭建Hadoop、Spark等大数据平台
近年来,大数据技术在各个领域都得到越来越广泛的应用。相比于传统的数据库和数据分析工具,hadoop、spark等大数据平台具有更强的扩展性、易用性、容错性、实时性和效率。虽然搭建大数据平台需要具备一定的技术水平,但是通过使用宝塔面板,可以大大降低搭建大数据平台的难度和复杂度。 一、宝塔面板简介 宝塔…
-
Spark vs. Flink — 核心技术点

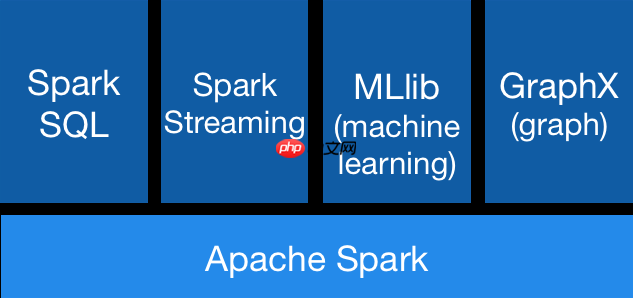
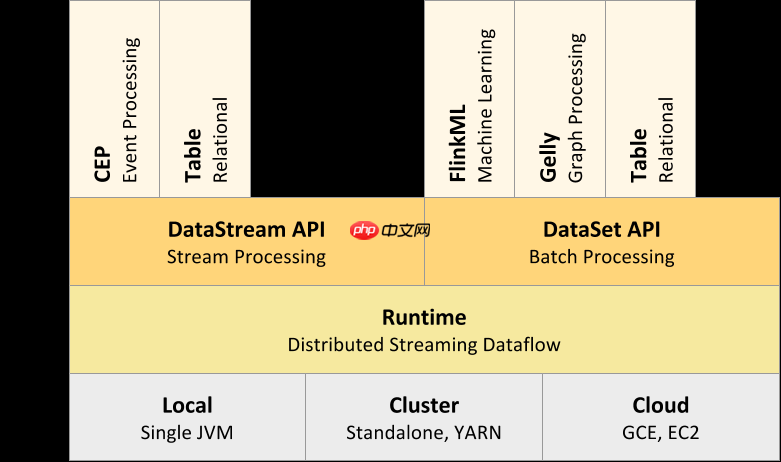
引言 Apache Spark 是一个综合性且高效的分布式计算引擎,兼具批处理和流计算能力,利用内存进行并行计算。官方数据表明,Spark的内存计算速度比MapReduce快100倍。作为当前最流行的计算框架,Spark已展现出其卓越的性能。 Apache Flink 是一个分布式大数据处理引擎,提…
-
Spark HA集群搭建
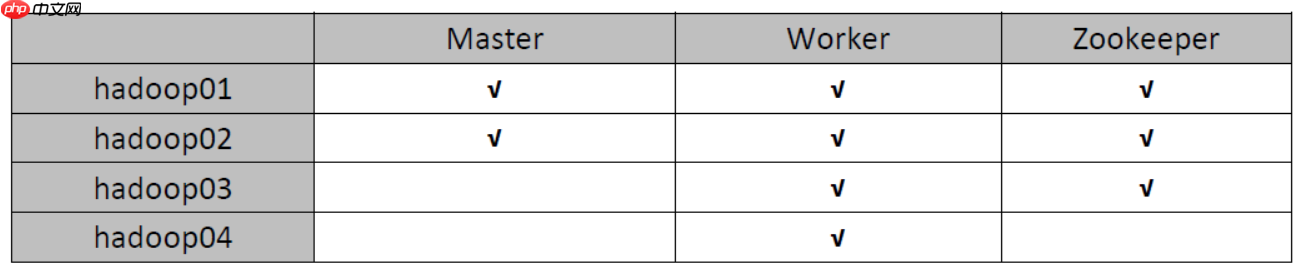
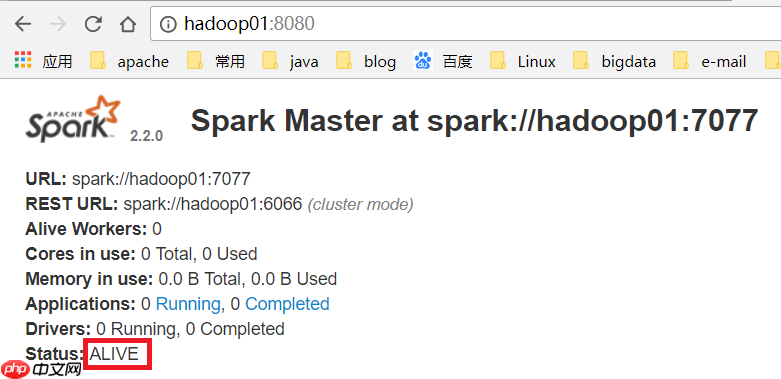
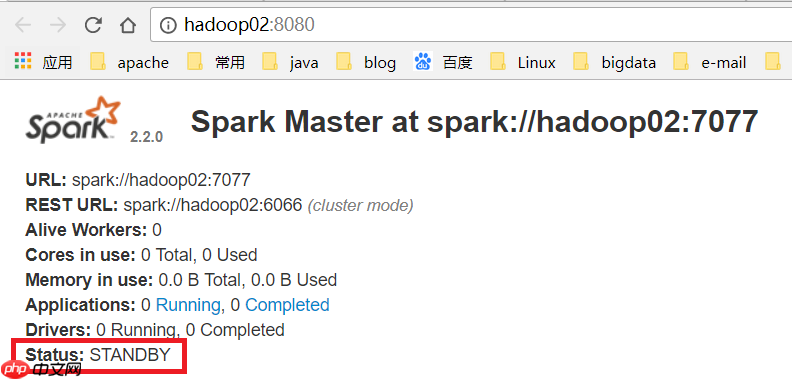
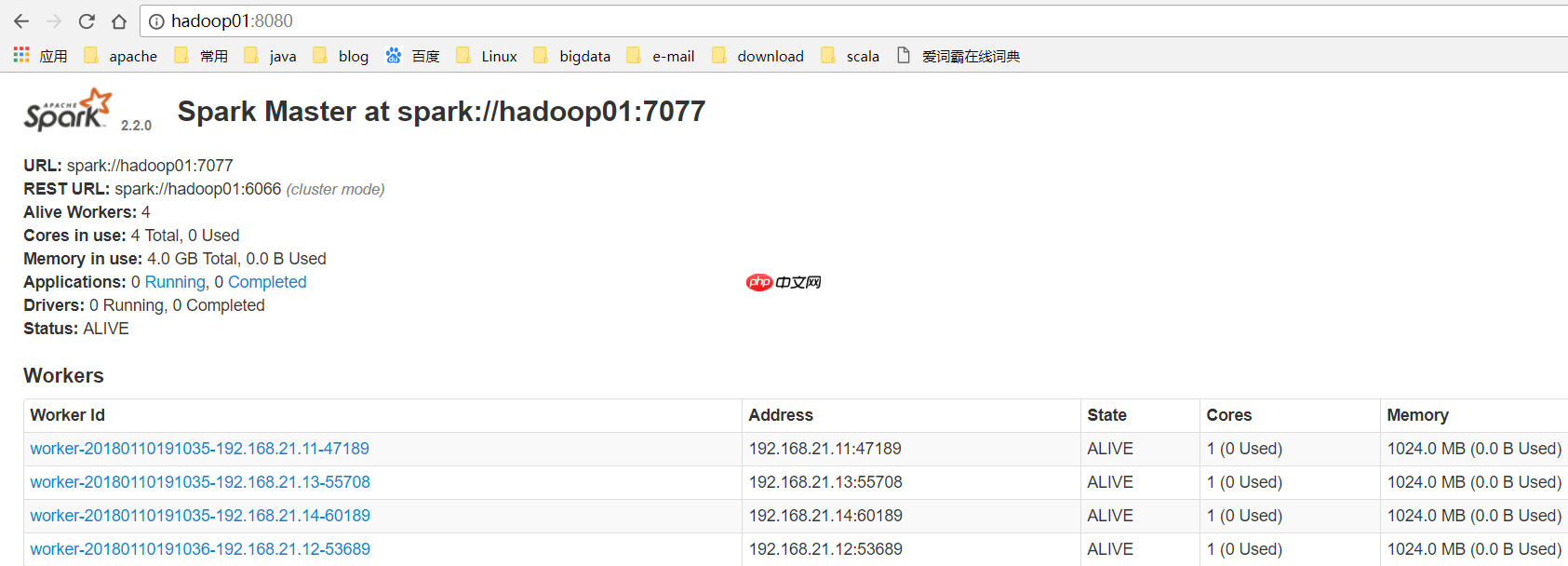
环境准备 我使用的是CentOS-6.6版本的4个虚拟机,主机名为hadoop01、hadoop02、hadoop03、hadoop04。集群将由hadoop用户搭建(在生产环境中,root用户通常不可随意使用)。关于虚拟机的安装,可以参考以下两篇文章:在Windows中安装一台Linux虚拟机,以…


