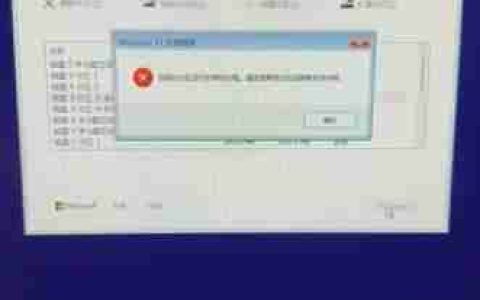
识别对比
1、百度识别
发现百度的图片搜索识别率不是特别,下面为测试图片跟测试后的结果:
测试图片:

下面为测试后的结果:

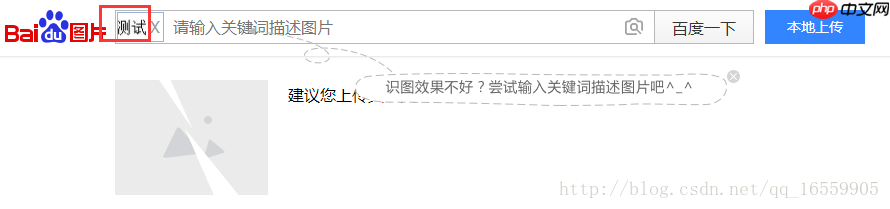
2、采用 tesseract.js 后结果
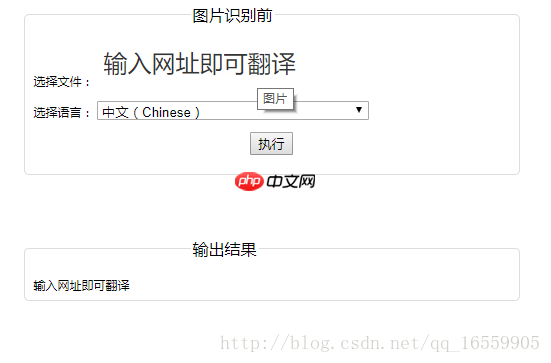
H5 图像识别 (采用Tesseract.js 进行识别)
简单的文案之类的,识别的还算可以,但是稍微复杂点的,准确率就不是那么好了,在学习中。。。
安装代码语言:javascript代码运行次数:0运行复制
或者
PS:如果使用 npm 安装异常,可以使用 cnpm 进行安装使用
使用
demo 1:then使用
代码语言:javascript代码运行次数:0运行复制
var Tesseract = require('tesseract.js')Tesseract.recognize(myImage).then(function(result){ console.log(result)})demo 2:lang切换
代码语言:javascript代码运行次数:0运行复制
Tesseract.recognize(myImage, { lang: 'spa', tessedit_char_blacklist: 'e'}).then(function(result){ console.log(result)})demo 3:(then、progress、catch、then、finally)
代码语言:javascript代码运行次数:0运行复制
Tesseract.recognize(src, { lang:"chi_sim", }) .progress(function(message) { console.log(message) }) .catch(function(err) { console.error(err) }) .then(function(result) { console.log(result.text) }) .finally(function(resultOrError) { console.log(resultOrError) })参数介绍:
1、image是任何 参数介绍:
image是任何 ImageLike 对象,取决于它是从浏览器还是通过NodeJS运行。
第一个参数,可以是 img 路劲地址,可以是图片base64位的二进制码、也可以是Image对象 等。
附上实现的代码:
代码语言:javascript代码运行次数:0运行复制
图片识别 body{margin:0 auto;width:500px;font-size:12px;font-family:"arial, helvetica, sans-serif"}fieldset{margin-bottom:10%;border:1px solid #ddd;border-radius:5px}img,select,button{cursor:pointer}img{background:#ddd}h2{font-weight:500;font-size:16px}fieldset legend{margin-left:33%} var src = document.querySelector("img").src, selectOption = "", result = document.querySelector("#result"); function recognizeFile() { var select = document.querySelector("#langsel") selectOption = select.options[select.selectedIndex].value; } function btn() { Tesseract.recognize(src, { lang: selectOption ? selectOption : "chi_sim", }).progress(function(message) { console.log(message) }) .catch(function(err) { result.innerHTML = err; console.error(err) }) .then(function(result) { console.log(result.text) result.value = result.text; }) .finally(function(resultOrError) { result.innerHTML = resultOrError.value; console.log(resultOrError) }) } 2、语言支持介绍:
lang
Language
‘afr’
Afrikaans
‘ara’
Arabic
‘aze’
Azerbaijani
‘bel’
Belarusian
‘ben’
Bengali
‘bul’
Bulgarian
‘cat’
Catalan
‘ces’
Czech
‘chi_sim’
Chinese
‘chi_tra’
Traditional Chinese
‘chr’
Cherokee
‘dan’
Danish
‘deu’
German
‘ell’
Greek
‘eng’
English
‘enm’
English (Old)
‘epo’
Esperanto
‘epo_alt’
Esperanto alternative
‘equ’
Math
‘est’
Estonian
‘eus’
Basque
‘fin’
Finnish
‘fra’
French
‘frk’
Frankish
‘frm’
French (Old)
‘glg’
Galician
‘grc’
Ancient Greek
‘heb’
Hebrew
‘hin’
Hindi
‘hrv’
Croatian
‘hun’
Hungarian
‘ind’
Indonesian
‘isl’
Icelandic
‘ita’
Italian
‘ita_old’
Italian (Old)
‘jpn’
Japanese
‘kan’
Kannada
‘kor’
Korean
‘lav’
Latvian
‘lit’
Lithuanian
‘mal’
Malayalam
‘mkd’
Macedonian
‘mlt’
Maltese
‘msa’
Malay
‘nld’
Dutch
‘nor’
Norwegian
‘pol’
Polish
‘por’
Portuguese
‘ron’
Romanian
‘rus’
Russian
‘slk’
Slovakian
‘slv’
Slovenian
‘spa’
Spanish
‘spa_old’
Old Spanish
‘sqi’
Albanian
‘srp’
Serbian (Latin)
‘swa’
Swahili
‘swe’
Swedish
‘tam’
Tamil
‘tel’
Telugu
‘tgl’
Tagalog
‘tha’
Thai
‘tur’
Turkish
‘ukr’
Ukrainian
‘vie’
Vietnamese
Tesseract参数支持介绍:
Parameter
Default Value
Description
ambigs_debug_level
0
Debug level for unichar ambiguities
applybox_debug
1
Debug level
applybox_exposure_pattern
.exp
Exposure value follows this pattern in the image filename. The name of the image files are expected to be in the form [lang].[fontname].exp[num].tif
applybox_learn_chars_and_char_frags_mode
0
Learn both character fragments (as is done in the special low exposure mode) as well as unfragmented characters.
applybox_learn_ngrams_mode
0
Each bounding box is assumed to contain ngrams. Only learn the ngrams whose outlines overlap horizontally.
applybox_page
0
Page number to apply boxes from
assume_fixed_pitch_char_segment
0
include fixed-pitch heuristics in char segmentation
bestrate_pruning_factor
2
Multiplying factor of current best rate to prune other hypotheses
bidi_debug
0
Debug level for BiDi
bland_unrej
0
unrej potential with no chekcs
certainty_scale
20
Certainty scaling factor
certainty_scale
20
Certainty scaling factor
chop_center_knob
0.15
Split center adjustment
chop_centered_maxwidth
90
Width of (smaller) chopped blobs above which we don’t care that a chop is not near the center.
chop_debug
0
Chop debug
chop_enable
1
Chop enable
chop_good_split
50
Good split limit
chop_inside_angle
-50
Min Inside Angle Bend
chop_min_outline_area
2000
Min Outline Area
chop_min_outline_points
6
Min Number of Points on Outline
chop_new_seam_pile
1
Use new seam_pile
chop_ok_split
100
OK split limit
chop_overlap_knob
0.9
Split overlap adjustment
chop_same_distance
2
Same distance
chop_seam_pile_size
150
Max number of seams in seam_pile
chop_sharpness_knob
0.06
Split sharpness adjustment
chop_split_dist_knob
0.5
Split length adjustment
chop_split_length
10000
Split Length
chop_vertical_creep
0
Vertical creep
chop_width_change_knob
5
Width change adjustment
chop_x_y_weight
3
X / Y length weight
chs_leading_punct
(‘`”
Leading punctuation
chs_trailing_punct1
).,;:?!
1st Trailing punctuation
chs_trailing_punct2
)’`”
2nd Trailing punctuation
classify_adapt_feature_threshold
230
Threshold for good features during adaptive 0-255
classify_adapt_proto_threshold
230
Threshold for good protos during adaptive 0-255
classify_adapted_pruning_factor
2.5
Prune poor adapted results this much worse than best result
classify_adapted_pruning_threshold
-1
Threshold at which classify_adapted_pruning_factor starts
classify_bln_numeric_mode
0
Assume the input is numbers [0-9].
classify_char_norm_range
0.2
Character Normalization Range …
classify_character_fragments_garbage_certainty_threshold
-3
Exclude fragments that do not look like whole characters from training and adaption
classify_class_pruner_multiplier
15
Class Pruner Multiplier 0-255:
classify_class_pruner_threshold
229
Class Pruner Threshold 0-255
classify_cp_angle_pad_loose
45
Class Pruner Angle Pad Loose
classify_cp_angle_pad_medium
20
Class Pruner Angle Pad Medium
classify_cp_angle_pad_tight
10
CLass Pruner Angle Pad Tight
classify_cp_cutoff_strength
7
Class Pruner CutoffStrength:
classify_cp_end_pad_loose
0.5
Class Pruner End Pad Loose
classify_cp_end_pad_medium
0.5
Class Pruner End Pad Medium
classify_cp_end_pad_tight
0.5
Class Pruner End Pad Tight
classify_cp_side_pad_loose
2.5
Class Pruner Side Pad Loose
classify_cp_side_pad_medium
1.2
Class Pruner Side Pad Medium
classify_cp_side_pad_tight
0.6
Class Pruner Side Pad Tight
classify_debug_character_fragments
0
Bring up graphical debugging windows for fragments training
classify_debug_level
0
Classify debug level
classify_enable_adaptive_debugger
0
Enable match debugger
classify_enable_adaptive_matcher
1
Enable adaptive classifier
classify_enable_learning
1
Enable adaptive classifier
classify_font_name
UnknownFont
Default font name to be used in training
classify_integer_matcher_multiplier
10
Integer Matcher Multiplier 0-255:
classify_learn_debug_str
Class str to debug learning
classify_learning_debug_level
0
Learning Debug Level:
classify_max_certainty_margin
5.5
Veto difference between classifier certainties
classify_max_norm_scale_x
0.325
Max char x-norm scale …
classify_max_norm_scale_y
0.325
Max char y-norm scale …
classify_max_rating_ratio
1.5
Veto ratio between classifier ratings
classify_max_slope
2.41421
Slope above which lines are called vertical
classify_min_norm_scale_x
0
Min char x-norm scale …
classify_min_norm_scale_y
0
Min char y-norm scale …
classify_min_slope
0.414214
Slope below which lines are called horizontal
classify_misfit_junk_penalty
0
Penalty to apply when a non-alnum is vertically out of its expected textline position
classify_nonlinear_norm
0
Non-linear stroke-density normalization
classify_norm_adj_curl
2
Norm adjust curl …
classify_norm_adj_midpoint
32
Norm adjust midpoint …
classify_norm_method
1
Normalization Method …
classify_num_cp_levels
3
Number of Class Pruner Levels
classify_pico_feature_length
0.05
Pico Feature Length
classify_pp_angle_pad
45
Proto Pruner Angle Pad
classify_pp_end_pad
0.5
Proto Prune End Pad
classify_pp_side_pad
2.5
Proto Pruner Side Pad
classify_save_adapted_templates
0
Save adapted templates to a file
classify_training_file
MicroFeatures
Training file
classify_use_pre_adapted_templates
0
Use pre-adapted classifier templates
conflict_set_I_l_1
Il1[]
Il1 conflict set
crunch_accept_ok
1
Use acceptability in okstring
crunch_debug
0
As it says
crunch_del_cert
-10
POTENTIAL crunch cert lt this
crunch_del_high_word
1.5
Del if word gt xht x this above bl
crunch_del_low_word
0.5
Del if word gt xht x this below bl
crunch_del_max_ht
3
Del if word ht gt xht x this
crunch_del_min_ht
0.7
Del if word ht lt xht x this
crunch_del_min_width
3
Del if word width lt xht x this
crunch_del_rating
60
POTENTIAL crunch rating lt this
crunch_early_convert_bad_unlv_chs
0
Take out ~^ early?
crunch_early_merge_tess_fails
1
Before word crunch?
crunch_include_numerals
0
Fiddle alpha figures
crunch_leave_accept_strings
0
Dont pot crunch sensible strings
crunch_leave_lc_strings
4
Dont crunch words with long lower case strings
crunch_leave_ok_strings
1
Dont touch sensible strings
crunch_leave_uc_strings
4
Dont crunch words with long lower case strings
crunch_long_repetitions
3
Crunch words with long repetitions
crunch_poor_garbage_cert
-9
crunch garbage cert lt this
crunch_poor_garbage_rate
60
crunch garbage rating lt this
crunch_pot_garbage
1
POTENTIAL crunch garbage
crunch_pot_indicators
1
How many potential indicators needed
crunch_pot_poor_cert
-8
POTENTIAL crunch cert lt this
crunch_pot_poor_rate
40
POTENTIAL crunch rating lt this
crunch_rating_max
10
For adj length in rating per ch
crunch_small_outlines_size
0.6
Small if lt xht x this
crunch_terrible_garbage
1
As it says
crunch_terrible_rating
80
crunch rating lt this
cube_debug_level
0
Print cube debug info.
dawg_debug_level
0
Set to 1 for general debug info, to 2 for more details, to 3 to see all the debug messages
debug_acceptable_wds
0
Dump word pass/fail chk
debug_file
File to send tprintf output to
debug_fix_space_level
0
Contextual fixspace debug
debug_noise_removal
0
Debug reassignment of small outlines
debug_x_ht_level
0
Reestimate debug
devanagari_split_debugimage
0
Whether to create a debug image for split shiro-rekha process.
devanagari_split_debuglevel
0
Debug level for split shiro-rekha process.
disable_character_fragments
1
Do not include character fragments in the results of the classifier
doc_dict_certainty_threshold
-2.25
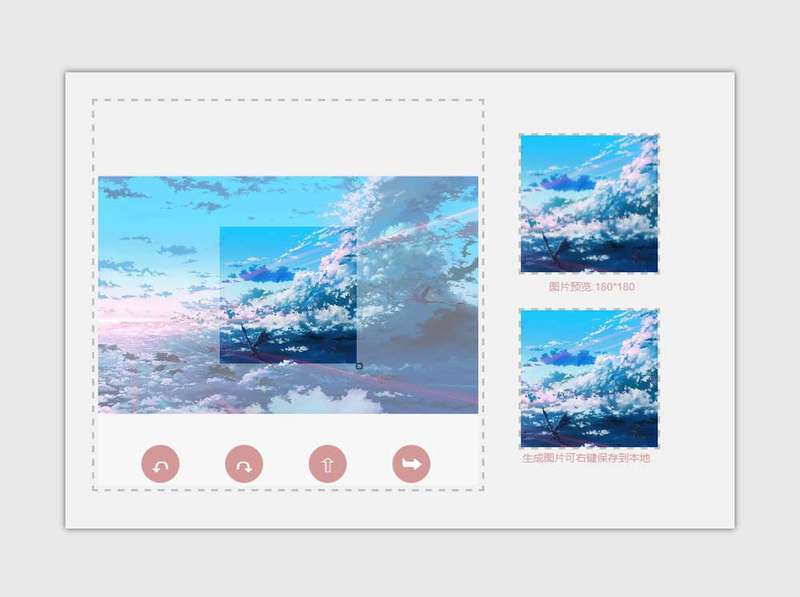 H5上传图片头像剪裁特效
H5上传图片头像剪裁特效
一款上传图片头像剪裁特效,能够不依靠后台自行剪裁图片并且生成新的图片,适用于各大网站的用户头像模块。
 51 查看详情
51 查看详情 
Worst certainty for words that can be inserted into thedocument dictionary
doc_dict_pending_threshold
0
Worst certainty for using pending dictionary
docqual_excuse_outline_errs
0
Allow outline errs in unrejection?
edges_boxarea
0.875
Min area fraction of grandchild for box
edges_childarea
0.5
Min area fraction of child outline
edges_children_count_limit
45
Max holes allowed in blob
edges_children_fix
0
Remove boxy parents of char-like children
edges_children_per_grandchild
10
Importance ratio for chucking outlines
edges_debug
0
turn on debugging for this module
edges_max_children_layers
5
Max layers of nested children inside a character outline
edges_max_children_per_outline
10
Max number of children inside a character outline
edges_min_nonhole
12
Min pixels for potential char in box
edges_patharea_ratio
40
Max lensq/area for acceptable child outline
edges_use_new_outline_complexity
0
Use the new outline complexity module
editor_dbwin_height
24
Editor debug window height
editor_dbwin_name
EditorDBWin
Editor debug window name
editor_dbwin_width
80
Editor debug window width
editor_dbwin_xpos
50
Editor debug window X Pos
editor_dbwin_ypos
500
Editor debug window Y Pos
editor_debug_config_file
Config file to apply to single words
editor_image_blob_bb_color
4
Blob bounding box colour
editor_image_menuheight
50
Add to image height for menu bar
editor_image_text_color
2
Correct text colour
editor_image_win_name
EditorImage
Editor image window name
editor_image_word_bb_color
7
Word bounding box colour
editor_image_xpos
590
Editor image X Pos
editor_image_ypos
10
Editor image Y Pos
editor_word_height
240
Word window height
editor_word_name
BlnWords
BL normalized word window
editor_word_width
655
Word window width
editor_word_xpos
60
Word window X Pos
editor_word_ypos
510
Word window Y Pos
enable_new_segsearch
0
Enable new segmentation search path.
enable_noise_removal
1
Remove and conditionally reassign small outlines when they confuse layout analysis, determining diacritics vs noise
equationdetect_save_bi_image
0
Save input bi image
equationdetect_save_merged_image
0
Save the merged image
equationdetect_save_seed_image
0
Save the seed image
equationdetect_save_spt_image
0
Save special character image
file_type
.tif
Filename extension
fixsp_done_mode
1
What constitues done for spacing
fixsp_non_noise_limit
1
How many non-noise blbs either side?
fixsp_small_outlines_size
0.28
Small if lt xht x this
force_word_assoc
0
force associator to run regardless of what enable_assoc is.This is used for CJK where component grouping is necessary.
fragments_debug
0
Debug character fragments
fragments_guide_chopper
0
Use information from fragments to guide chopping process
fx_debugfile
FXDebug
Name of debugfile
gapmap_big_gaps
1.75
xht multiplier
gapmap_debug
0
Say which blocks have tables
gapmap_no_isolated_quanta
0
Ensure gaps not less than 2quanta wide
gapmap_use_ends
0
Use large space at start and end of rows
heuristic_max_char_wh_ratio
2
max char width-to-height ratio allowed in segmentation
heuristic_segcost_rating_base
1.25
base factor for adding segmentation cost into word rating.It’s a multiplying factor, the larger the value above 1, the bigger the effect of segmentation cost.
heuristic_weight_rating
1
weight associated with char rating in combined cost ofstate
heuristic_weight_seamcut
0
weight associated with seam cut in combined cost of state
heuristic_weight_width
1000
weight associated with width evidence in combined cost of state
hocr_font_info
0
Add font info to hocr output
hyphen_debug_level
0
Debug level for hyphenated words.
il1_adaption_test
0
Dont adapt to i/I at beginning of word
include_page_breaks
0
Include page separator string in output text after each image/page.
interactive_display_mode
0
Run interactively?
language_model_debug_level
0
Language model debug level
language_model_fixed_length_choices_depth
3
Depth of blob choice lists to explore when fixed length dawgs are on
language_model_min_compound_length
3
Minimum length of compound words
language_model_ngram_nonmatch_score
-40
Average classifier score of a non-matching unichar.
language_model_ngram_on
0
Turn on/off the use of character ngram model
language_model_ngram_order
8
Maximum order of the character ngram model
language_model_ngram_rating_factor
16
Factor to bring log-probs into the same range as ratings when multiplied by outline length
language_model_ngram_scale_factor
0.03
Strength of the character ngram model relative to the character classifier
language_model_ngram_small_prob
1e-06
To avoid overly small denominators use this as the floor of the probability returned by the ngram model.
language_model_ngram_space_delimited_language
1
Words are delimited by space
language_model_ngram_use_only_first_uft8_step
0
Use only the first UTF8 step of the given string when computing log probabilities.
language_model_penalty_case
0.1
Penalty for inconsistent case
language_model_penalty_chartype
0.3
Penalty for inconsistent character type
language_model_penalty_font
0
Penalty for inconsistent font
language_model_penalty_increment
0.01
Penalty increment
language_model_penalty_non_dict_word
0.15
Penalty for non-dictionary words
language_model_penalty_non_freq_dict_word
0.1
Penalty for words not in the frequent word dictionary
language_model_penalty_punc
0.2
Penalty for inconsistent punctuation
language_model_penalty_script
0.5
Penalty for inconsistent script
language_model_penalty_spacing
0.05
Penalty for inconsistent spacing
language_model_use_sigmoidal_certainty
0
Use sigmoidal score for certainty
language_model_viterbi_list_max_num_prunable
10
Maximum number of prunable (those for which PrunablePath() is true) entries in each viterbi list recorded in BLOB_CHOICEs
language_model_viterbi_list_max_size
500
Maximum size of viterbi lists recorded in BLOB_CHOICEs
load_bigram_dawg
1
Load dawg with special word bigrams.
load_fixed_length_dawgs
1
Load fixed length dawgs (e.g. for non-space delimited languages)
load_freq_dawg
1
Load frequent word dawg.
load_number_dawg
1
Load dawg with number patterns.
load_punc_dawg
1
Load dawg with punctuation patterns.
load_system_dawg
1
Load system word dawg.
load_unambig_dawg
1
Load unambiguous word dawg.
m_data_sub_dir
tessdata/
Directory for data files
matcher_avg_noise_size
12
Avg. noise blob length
matcher_bad_match_pad
0.15
Bad Match Pad (0-1)
matcher_clustering_max_angle_delta
0.015
Maximum angle delta for prototype clustering
matcher_debug_flags
0
Matcher Debug Flags
matcher_debug_level
0
Matcher Debug Level
matcher_debug_separate_windows
0
Use two different windows for debugging the matching: One for the protos and one for the features.
matcher_good_threshold
0.125
Good Match (0-1)
matcher_great_threshold
0
Great Match (0-1)
matcher_min_examples_for_prototyping
3
Reliable Config Threshold
matcher_perfect_threshold
0.02
Perfect Match (0-1)
matcher_permanent_classes_min
1
Min # of permanent classes
matcher_rating_margin
0.1
New template margin (0-1)
matcher_sufficient_examples_for_prototyping
5
Enable adaption even if the ambiguities have not been seen
max_permuter_attempts
10000
Maximum number of different character choices to consider during permutation. This limit is especially useful when user patterns are specified, since overly generic patterns can result in dawg search exploring an overly large number of options.
max_viterbi_list_size
10
Maximum size of viterbi list.
merge_fragments_in_matrix
1
Merge the fragments in the ratings matrix and delete them after merging
min_orientation_margin
7
Min acceptable orientation margin
min_sane_x_ht_pixels
8
Reject any x-ht lt or eq than this
ngram_permuter_activated
0
Activate character-level n-gram-based permuter
noise_cert_basechar
-8
Hingepoint for base char certainty
noise_cert_disjoint
-1
Hingepoint for disjoint certainty
noise_cert_factor
0.375
Scaling on certainty diff from Hingepoint
noise_cert_punc
-3
Threshold for new punc char certainty
noise_maxperblob
8
Max diacritics to apply to a blob
noise_maxperword
16
Max diacritics to apply to a word
numeric_punctuation
.,
Punct. chs expected WITHIN numbers
ocr_devanagari_split_strategy
0
Whether to use the top-line splitting process for Devanagari documents while performing ocr.
ok_repeated_ch_non_alphanum_wds
-?*=
Allow NN to unrej
oldbl_corrfix
1
Improve correlation of heights
oldbl_dot_error_size
1.26
Max aspect ratio of a dot
oldbl_holed_losscount
10
Max lost before fallback line used
oldbl_xhfix
0
Fix bug in modes threshold for xheights
oldbl_xhfract
0.4
Fraction of est allowed in calc
outlines_2
ij!?%”:;
Non standard number of outlines
outlines_odd
%
output_ambig_words_file
Output file for ambiguities found in the dictionary
page_separator
pageseg_devanagari_split_strategy
0
Whether to use the top-line splitting process for Devanagari documents while performing page-segmentation.
paragraph_debug_level
0
Print paragraph debug info.
paragraph_text_based
1
Run paragraph detection on the post-text-recognition (more accurate)
permute_chartype_word
0
Turn on character type (property) consistency permuter
permute_debug
0
Debug char permutation process
permute_fixed_length_dawg
0
Turn on fixed-length phrasebook search permuter
permute_only_top
0
Run only the top choice permuter
permute_script_word
0
Turn on word script consistency permuter
pitsync_fake_depth
1
Max advance fake generation
pitsync_joined_edge
0.75
Dist inside big blob for chopping
pitsync_linear_version
6
Use new fast algorithm
pitsync_offset_freecut_fraction
0.25
Fraction of cut for free cuts
poly_allow_detailed_fx
0
Allow feature extractors to see the original outline
poly_debug
0
Debug old poly
poly_wide_objects_better
1
More accurate approx on wide things
preserve_interword_spaces
0
Preserve multiple interword spaces
prioritize_division
0
Prioritize blob division over chopping
quality_blob_pc
0
good_quality_doc gte good blobs limit
quality_char_pc
0.95
good_quality_doc gte good char limit
quality_min_initial_alphas_reqd
2
alphas in a good word
quality_outline_pc
1
good_quality_doc lte outline error limit
quality_rej_pc
0.08
good_quality_doc lte rejection limit
quality_rowrej_pc
1.1
good_quality_doc gte good char limit
rating_scale
1.5
Rating scaling factor
rej_1Il_trust_permuter_type
1
Dont double check
rej_1Il_use_dict_word
0
Use dictword test
rej_alphas_in_number_perm
0
Extend permuter check
rej_trust_doc_dawg
0
Use DOC dawg in 11l conf. detector
rej_use_good_perm
1
Individual rejection control
rej_use_sensible_wd
0
Extend permuter check
rej_use_tess_accepted
1
Individual rejection control
rej_use_tess_blanks
1
Individual rejection control
rej_whole_of_mostly_reject_word_fract
0.85
if >this fract
repair_unchopped_blobs
1
Fix blobs that aren’t chopped
save_alt_choices
1
Save alternative paths found during chopping and segmentation search
save_doc_words
0
Save Document Words
save_raw_choices
1
Deprecated- backward compatablity only
segment_adjust_debug
0
Segmentation adjustment debug
segment_debug
0
Debug the whole segmentation process
segment_nonalphabetic_script
0
Don’t use any alphabetic-specific tricks.Set to true in the traineddata config file for scripts that are cursive or inherently fixed-pitch
segment_penalty_dict_case_bad
1.3125
Default score multiplier for word matches, which may have case issues (lower is better).
segment_penalty_dict_case_ok
1.1
Score multiplier for word matches that have good case (lower is better).
segment_penalty_dict_frequent_word
1
Score multiplier for word matches which have good case andare frequent in the given language (lower is better).
segment_penalty_dict_nonword
1.25
Score multiplier for glyph fragment segmentations which do not match a dictionary word (lower is better).
GitHub地址

以上就是H5 图像识别的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/819628.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫