
csv文件
-
Python:在内存中生成CSV对象并直接上传至API




本教程详细介绍了如何在python中不将csv文件写入磁盘,而是直接在内存中生成csv数据,并将其作为文件上传到api。通过结合`io.stringio`和`csv`模块,可以高效地构建csv内容,然后使用`requests`库将其作为post请求的一部分发送,从而优化性能并减少文件i/o操作。 在…
-
解决Pandas sort_values在不同文件格式下结果不一致的问题


本文探讨了在使用pandas从excel和csv文件读取数据后,即便数据表面一致,`sort_values`操作仍可能产生不同结果的原因。文章详细介绍了如何利用`dataframe.compare()`和检查数据类型(`dtypes`)来诊断并解决这类潜在的数据差异问题,确保数据处理的一致性与准确性…
-
Pandas读取CSV文件时Unicode编码错误的实用解决方案


本教程详细介绍了如何使用pandas库解决读取csv文件时常见的`unicodedecodeerror`。当文件编码与预期不符,导致部分字符无法正确解码时,传统的编码参数可能不足以解决问题。本文将重点介绍pandas 1.3及以上版本提供的`encoding_errors`参数,通过设置其为`…
-
解决大型CSV文件导入导出难题:GoodbyCSV助你高效处理数据
最近在处理一个数据导入导出项目时,我遇到了一个令人头疼的问题:需要处理的CSV文件动辄数GB,包含数十万甚至上百万条记录。尝试使用PHP内置的 fgetcsv 函数时,程序经常因为内存占用过高而崩溃。即使调整了PHP内存限制,处理速度也慢得让人难以忍受,特别是当文件混合了UTF-8和SJIS-win…
-
用PaddleClas完成不平衡数据集多标签分类




本项目针对不平衡自然场景图片数据集的多标签分类任务,解决了数据分布不平衡及类标签依赖的难题。使用PaddleClas套件,通过过采样处理数据不平衡,用powerlabel区分多标签组合,基于MobileNetV1模型,采用带pos_weight参数的binary cross entropy with…
-
第九届“泰迪杯”数据挖掘挑战赛:岩石样本的智能识别分享


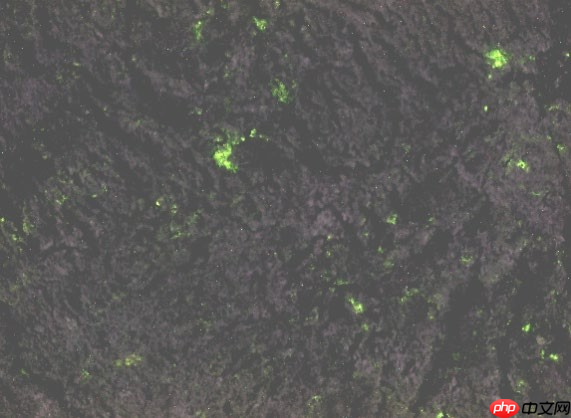
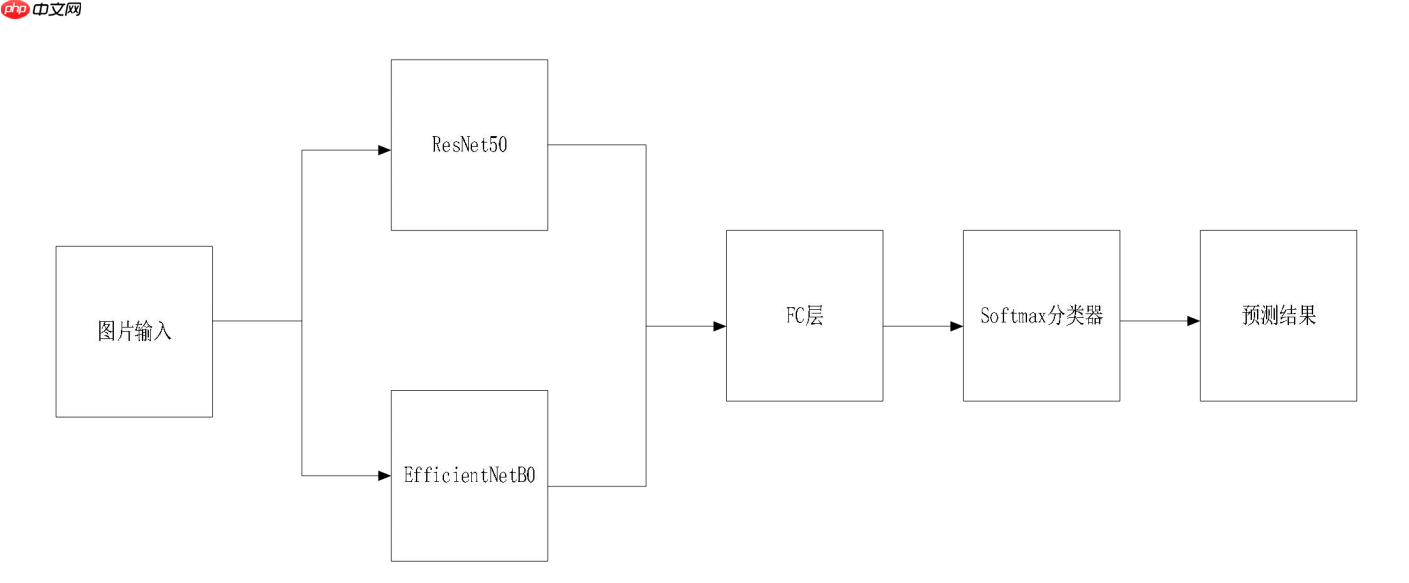
针对第九届“泰迪杯”数据挖掘挑战赛B题,本文提出岩石样本智能识别方案。对岩性识别,采用EfficientNet等深度学习模型,经数据增强处理样本,通过并行网络提升性能;对含油面积计算,基于荧光图像,利用OpenCV处理三通道像素,经阈值分割等步骤得出占比,为岩石分析提供支持。 ☞☞☞AI 智能聊天,…
-
优化Versa Director API调用:避免重复添加分析集群的实践


本文详细阐述了通过python脚本和versa director api添加组织时,如何避免分析集群重复条目问题。核心在于理解api对`analyticscluster`(单个字符串)和`analyticsclusters`(字符串数组)字段的不同预期,并确保在api请求中正确构造和使用`analy…
-
豆包AI编程操作说明 豆包AI自动编程技巧




用豆包ai写代码的关键在于提问方式和后续调整。1. 提问要具体,如“写一个python脚本,读取csv文件,统计每列的最大值和最小值,并输出到新文件”,以明确输入、操作和输出;2. 生成后需通读代码,检查逻辑与语法,并在小样本数据上测试,补充容错机制;3. 多轮交互优化,通过追问添加注释、支持中文路…
-
java 中10 流分为几种?




java的io流体系根据数据单位和流向分为字节流和字符流,每类又分输入流和输出流,共四种基本组合。1. 字节流处理二进制数据,以字节为单位传输,如inputstream和outputstream;2. 字符流处理文本数据,以字符为单位并自动处理编码转换,如reader和writer。选择时应根据数据…
-
Pandas股票数据拆分调整:处理历史股价与成交量


本教程详细介绍了如何使用pandas高效处理股票数据中的拆分(stock split)事件。通过布尔索引和向量化操作,我们将学习如何精确地对拆分日期前的历史股价(开盘价、最高价、最低价、收盘价、调整后收盘价)进行除法调整,并对成交量进行乘法调整,以确保数据的一致性和准确性,避免了繁琐的手动操作和中间…

