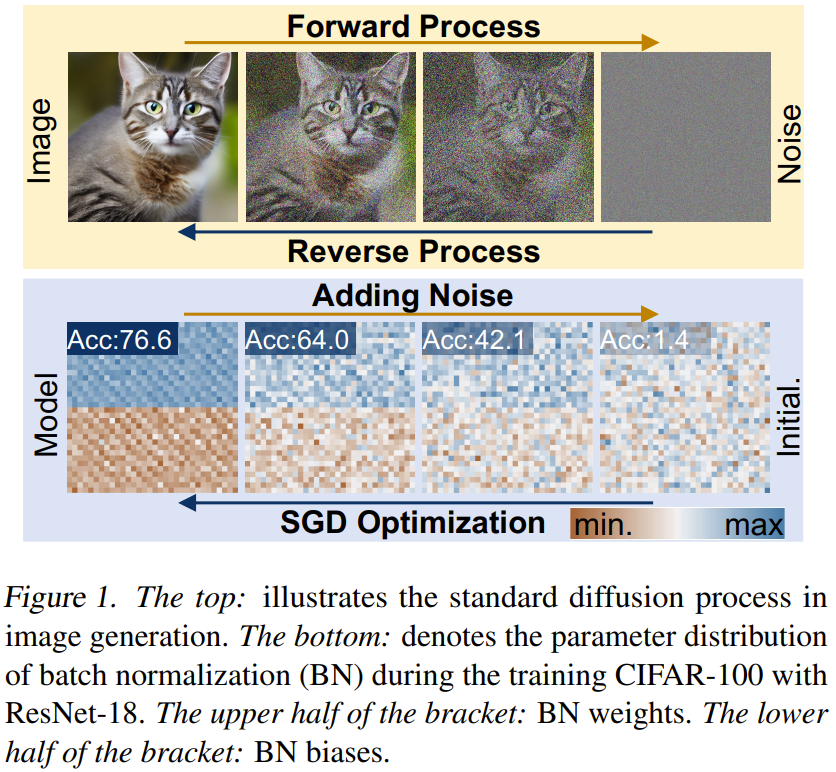
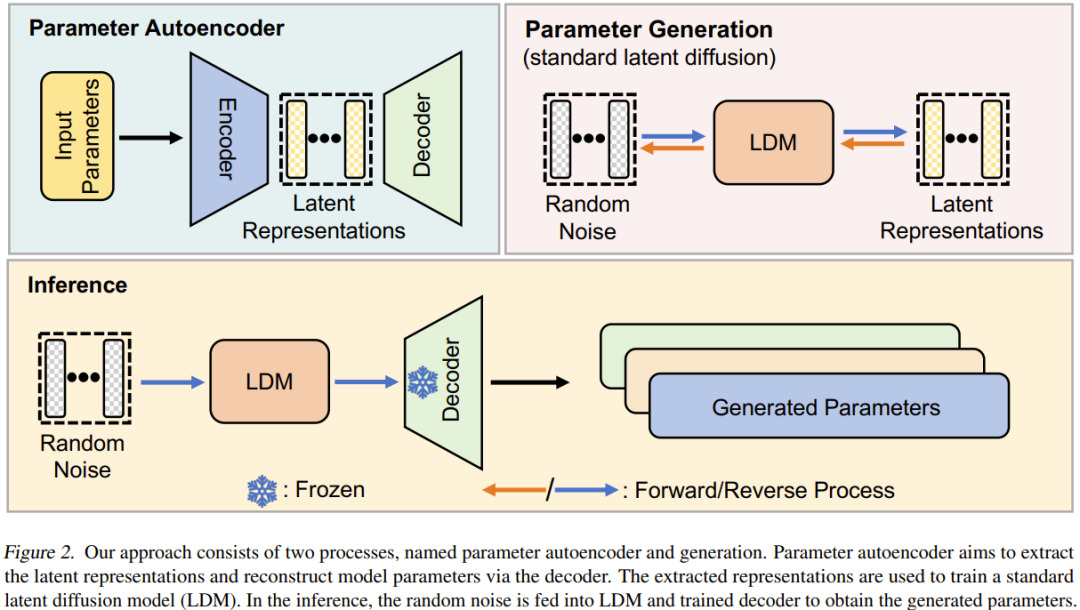
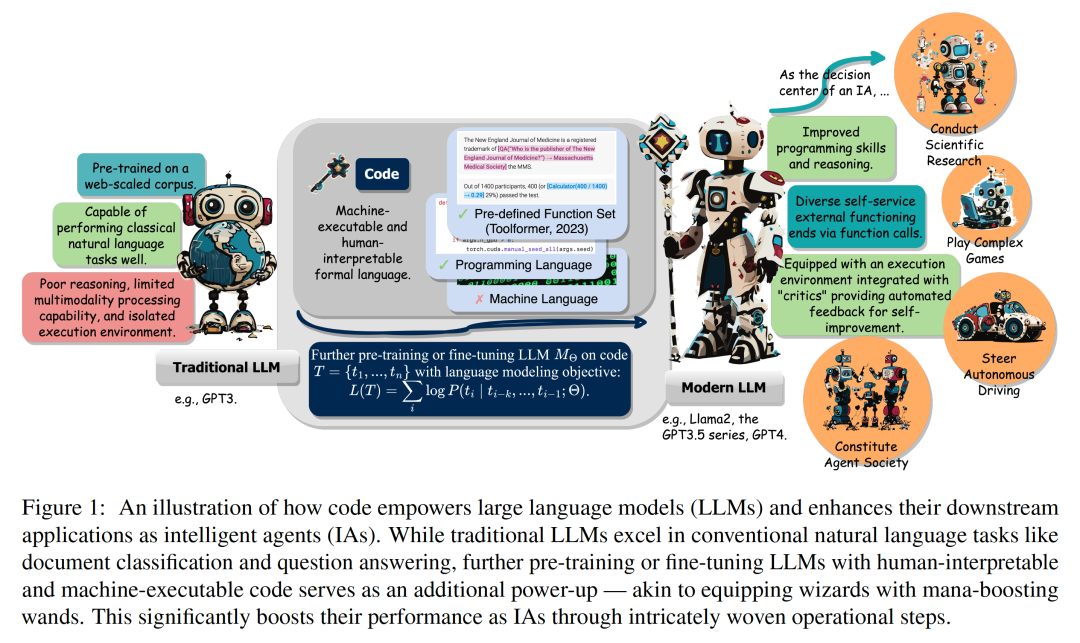
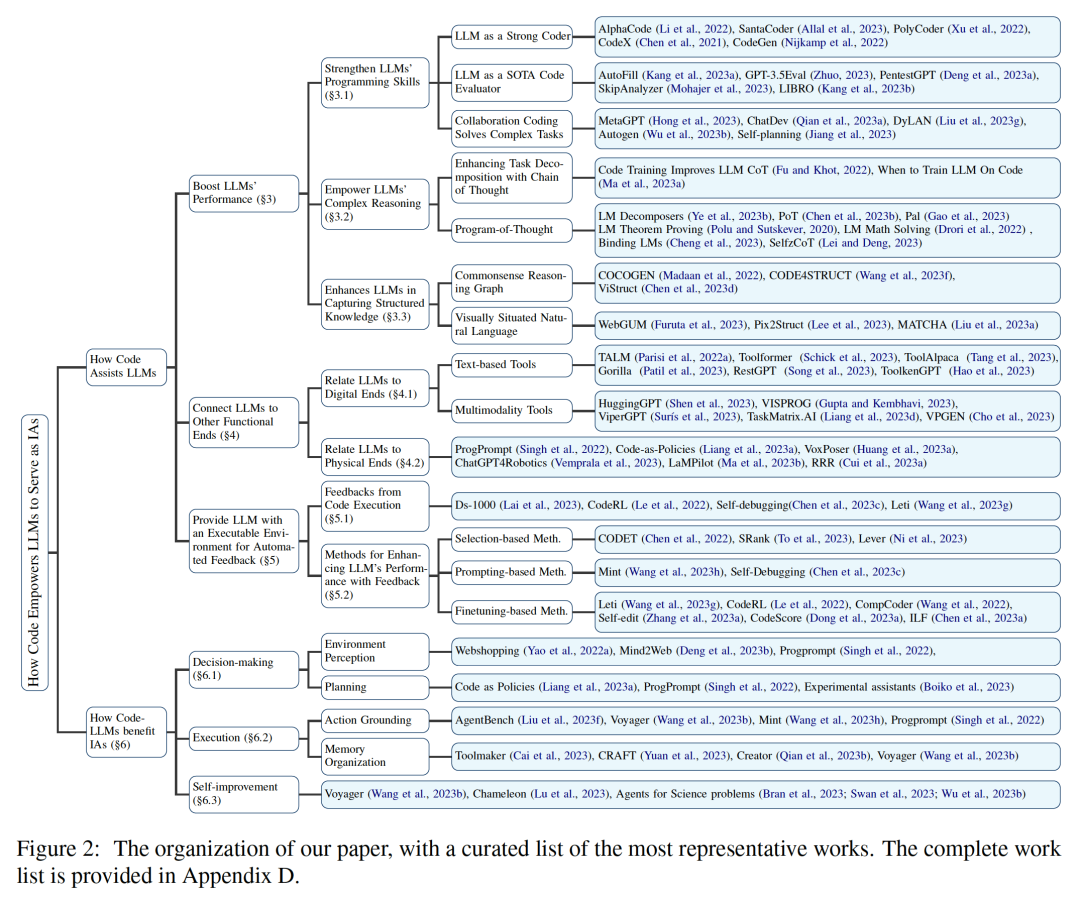
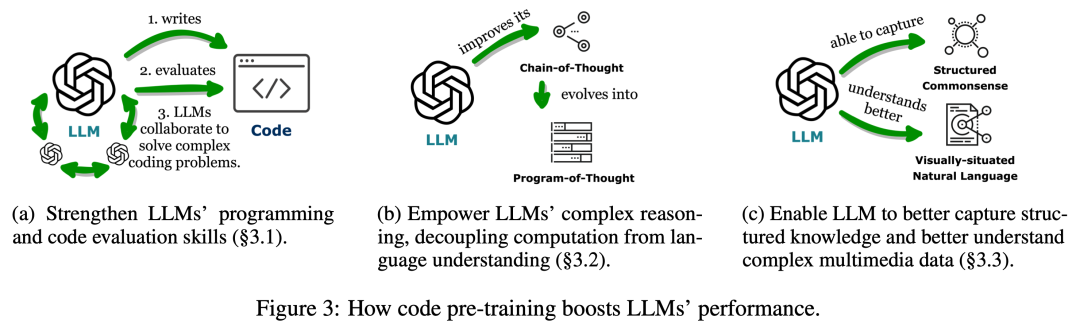
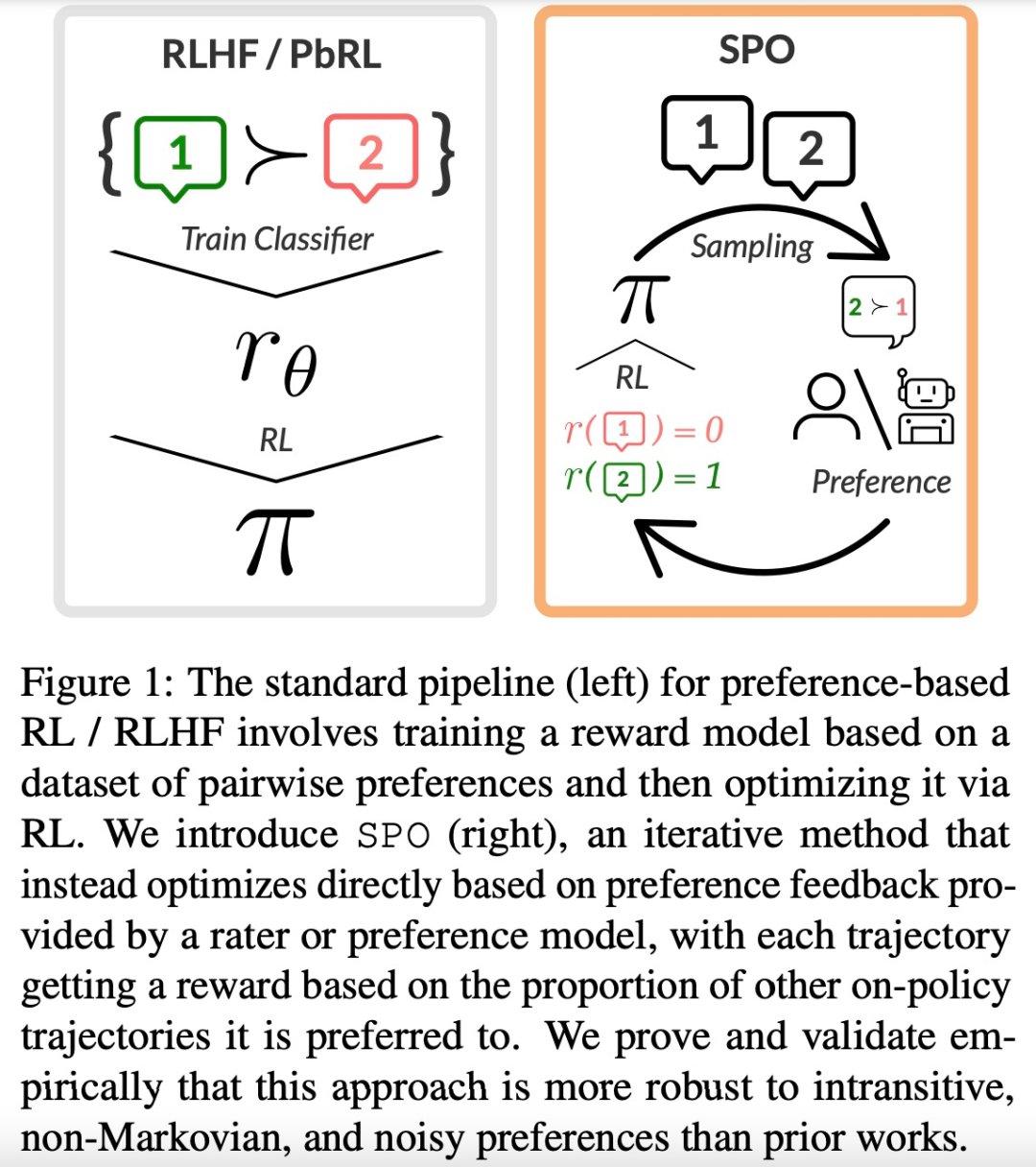
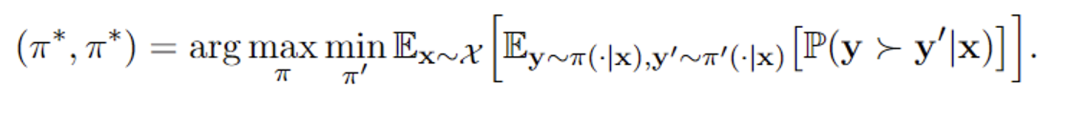上海交通大学与阿里巴巴通义实验室合作,在neurips 2024上发表了一篇关于数学推理场景下分布外检测的论文,提出了名为“tv score”的全新算法。该算法利用动态嵌入轨迹,有效解决了传统静态嵌入方法在数学推理场景中失效的问题。
传统的分布外(OOD)检测方法主要针对翻译、摘要等任务,通过计算样本嵌入与训练数据分布的马氏距离来识别异常。然而,数学推理的输出空间存在“模式坍缩”现象:不同输入可能产生相同结果,且分词化表示导致不同表达式共享大量token。这使得静态嵌入难以捕捉数学问题的复杂性。
为了克服这一挑战,TV Score 算法引入了动态嵌入轨迹的概念。它追踪语言模型各层对输入的嵌入变化,并将这些变化序列作为检测依据。研究发现,正确推理的样本(ID)嵌入轨迹变化平滑且“过早稳定”,而错误推理的样本(OOD)轨迹变化剧烈。
TV Score 算法具体步骤如下:首先,对每一层ID样本的嵌入进行高斯分布拟合;然后,计算新样本每一层嵌入与对应高斯分布的马氏距离;最后,将所有层马氏距离的平均值作为TV Score得分。为了提高鲁棒性,算法还加入了差分平滑技术,进一步抑制异常值的影响。
 觅果·Migo
觅果·Migo
AI学习、科研创新加速平台
 78 查看详情
78 查看详情 
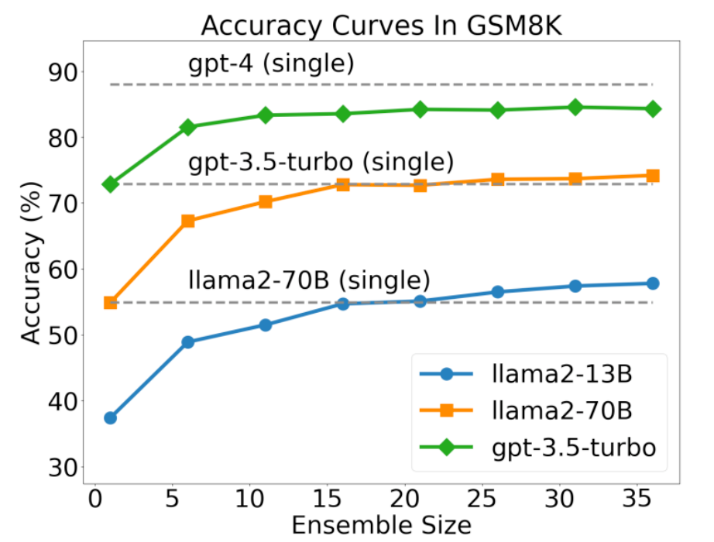
实验结果表明,TV Score 在多个数据集和不同规模的语言模型上均取得了显著优于基线方法的性能,尤其是在难以区分的Near-shift OOD场景中。此外,TV Score 在生成质量估计和不同任务场景下也展现了良好的泛化能力。
这项研究为数学推理场景下的OOD检测提供了新的思路和方法,也为其他具有“模式坍缩”特征的任务提供了借鉴。 它突显了在复杂应用场景下,开发更精细的安全性算法的重要性,以保障大模型的可靠性和安全性。
以上就是NeurIPS 2024 | 数学推理场景下,首个分布外检测研究成果来了的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/401376.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫