原标题:flashocc: fast and memory-efficient occupancy prediction via channel-to-height plugin
论文链接:https://arxiv.org/pdf/2311.12058.pdf
作者单位:大连理工大学 Houmo AI 阿德莱德大学
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文思路:
鉴于能够缓解 3D 目标检测中普遍存在的长尾缺陷和复杂形状缺失的能力,占用预测已成为自动驾驶系统的关键组成部分。然而,三维体素级表示的处理不可避免地会在内存和计算方面引入大量开销,阻碍了迄今为止的占用预测方法的部署。与使模型变得更大、更复杂的趋势相反,本文认为理想的框架应该对不同的芯片进行部署友好,同时保持高精度。为此,本文提出了一种即插即用范例,即 FlashOCC,以巩固快速且节省内存的占用预测,同时保持高精度。特别是,本文的 FlashOCC 基于当代体素级占用预测方法做出了两项改进。首先,特征保留在 BEV 中,从而能够使用高效的 2D 卷积层进行特征提取。其次,引入通道到高度变换(channel-to-height transformation) ,将 BEV 的输出 logits 提升到 3D 空间。本文将 FlashOCC 应用于具有挑战性的 Occ3D-nuScenes 基准的各种占用预测基线,并进行广泛的实验来验证其有效性。结果证实了本文的即插即用范例在精度、运行时效率和内存成本方面优于以前最先进的方法,展示了其部署潜力。该代码将可供使用。
网络设计:
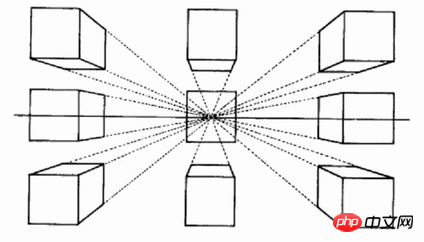
受到 sub-pixel convolution 技术[26] 的启发,我们将图像上采样替换为通道重新排列,以实现通道到空间的特征转换。在本文的研究中,我们的目标是有效地实现通道到高度的特征转换。考虑到 BEV 感知任务的发展,其中 BEV 表示中的每个像素包含有关相应柱状物体在高度维度上的信息,我们直观地利用通道到高度变换(channel-to-height transformation)将扁平化的 BEV 特征重新塑造为三维体素级别的占用 logits。因此,我们的研究专注于以通用和即插即用的方式增强现有模型,而不是开发新颖的模型架构,如图1 (a) 所示。具体来说,我们直接使用 2D 卷积替代当代方法中的 3D 卷积,并用通过 2D 卷积获得的 BEV 级特征的通道到高度变换替换从 3D 卷积输出中得到的占用 logits。这些模型不仅实现了准确性和时间消耗之间的最佳权衡,还展现出了出色的部署兼容性
FlashOcc 成功地以极高的精度成功完成了实时环视 3D 占用预测,代表了该领域的开创性贡献。此外,它还展现了跨不同车载平台部署的增强的多功能性,因为它不需要昂贵的体素级特征处理,其中避免了 view transformer 或 3D(可变形)卷积算子。如图2所示,FlashOcc的输入数据由环视图像组成,而输出是密集的占用预测结果。尽管本文的FlashOcc专注于以通用和即插即用的方式增强现有模型,但它仍然可以分为五个基本模块:(1)2D图像编码器,负责从多相机图像中提取图像特征。(2) 视图转换模块,有助于将 2D 感知视图图像特征映射到 3D BEV 表示。(3) BEV 编码器,负责处理 BEV 特征信息。(4) 占用预测模块,预测每个体素的分割标签。(5) 一个可选的时间融合模块,旨在集成历史信息以提高性能。
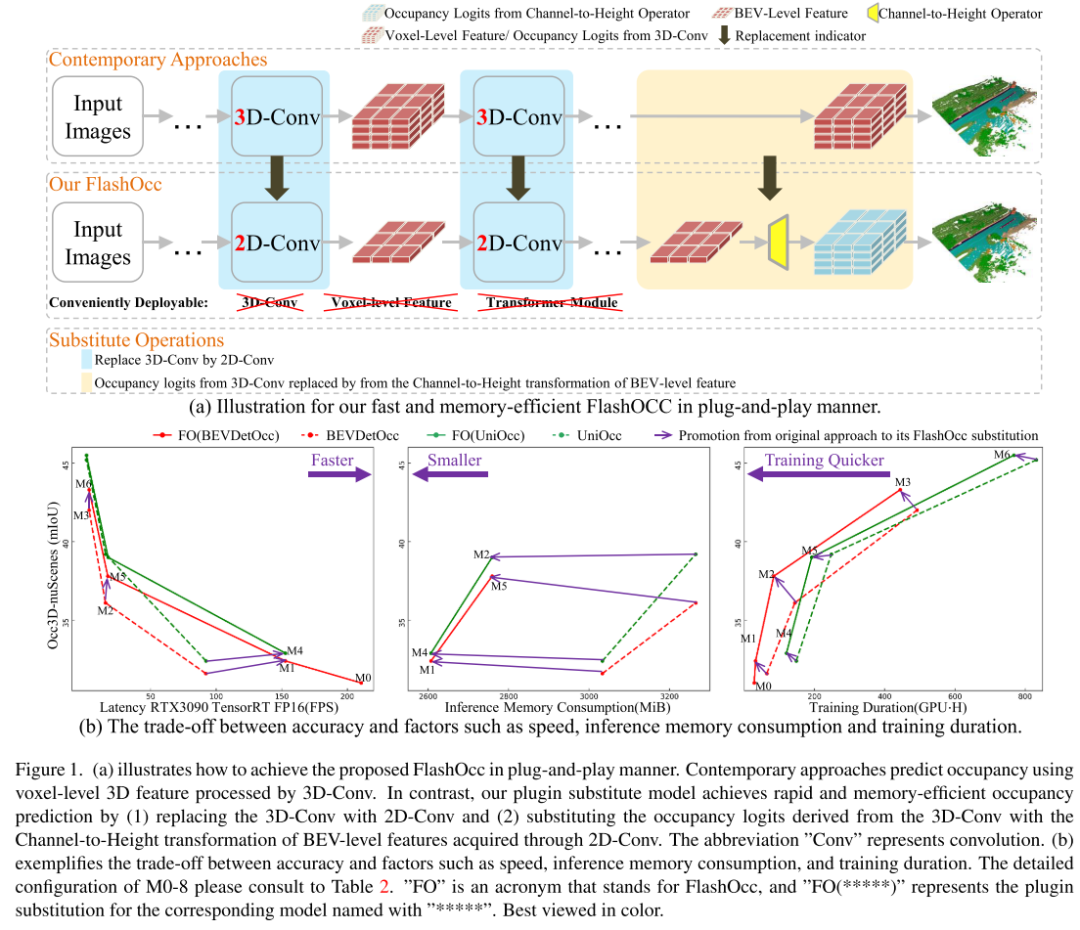
图 1.(a) 说明了如何以即插即用的方式实现所提出的 FlashOcc。现代方法使用 3D-Conv 处理的体素级 3D 特征来预测占用率。相比之下,本文的插件替代模型通过 (1) 用 2D-Conv 替换 3D-Conv 以及 (2) 用通道到高度变换(channel-to-height transformation) 替换从 3D-Conv 导出的占用 logits,实现快速且节省内存的占用预测通过 2D-Conv 获取的 BEV 级特征。缩写“Conv”代表卷积。(b) 举例说明了准确性与速度、推理内存消耗和训练持续时间等因素之间的权衡。
 boardmix博思白板
boardmix博思白板
boardmix博思白板,一个点燃团队协作和激发创意的空间,集aigc,一键PPT,思维导图,笔记文档多种创意表达能力于一体,将团队工作效率提升到新的层次。
 39 查看详情
39 查看详情 
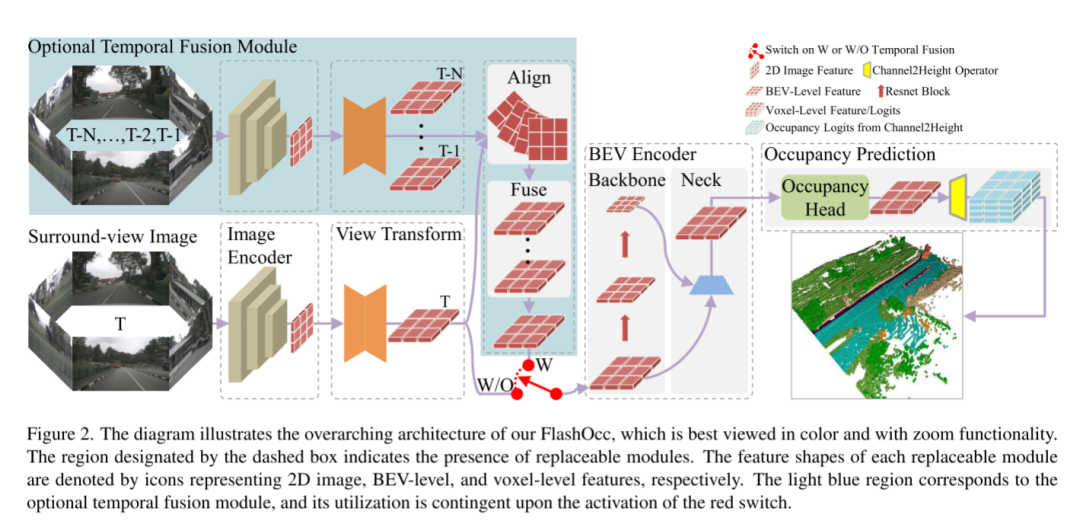
图 2. 该图说明了 FlashOcc 的总体架构,最好以彩色方式查看并具有缩放功能。虚线框指定的区域表示存在可更换模块。每个可更换模块的特征形状分别由代表 2D 图像、BEV 级和体素级特征的图标表示。浅蓝色区域对应于可选的时间融合模块,其使用取决于红色开关的激活。
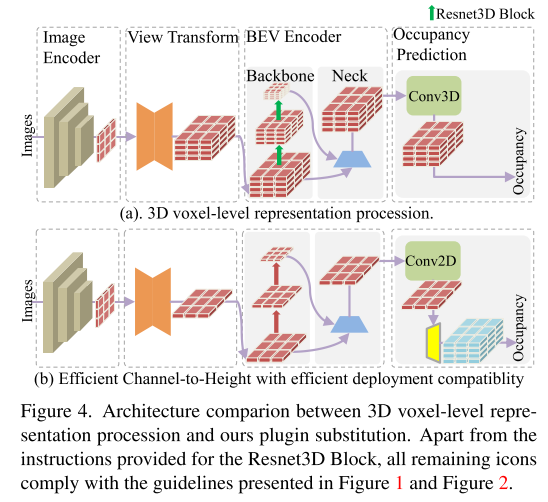
图4展示了3D体素级表示处理和本文提出的插件替换之间的架构比较
实验结果:
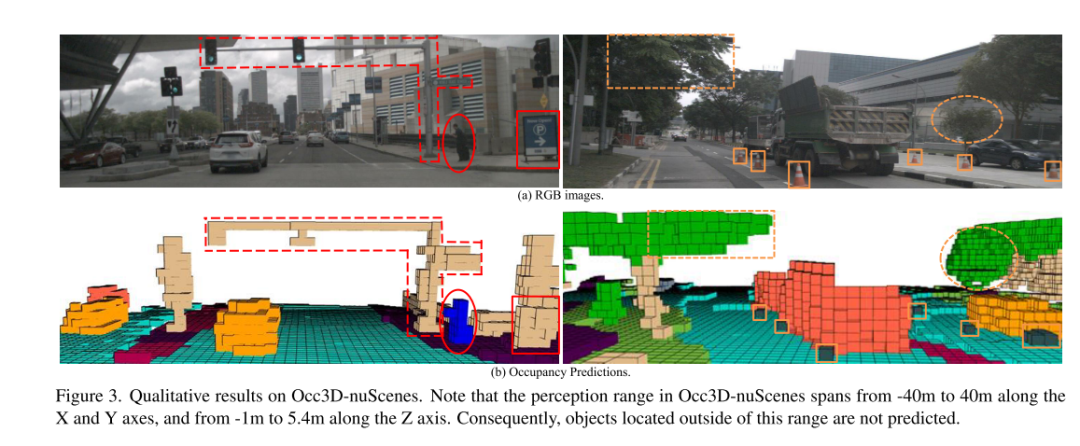
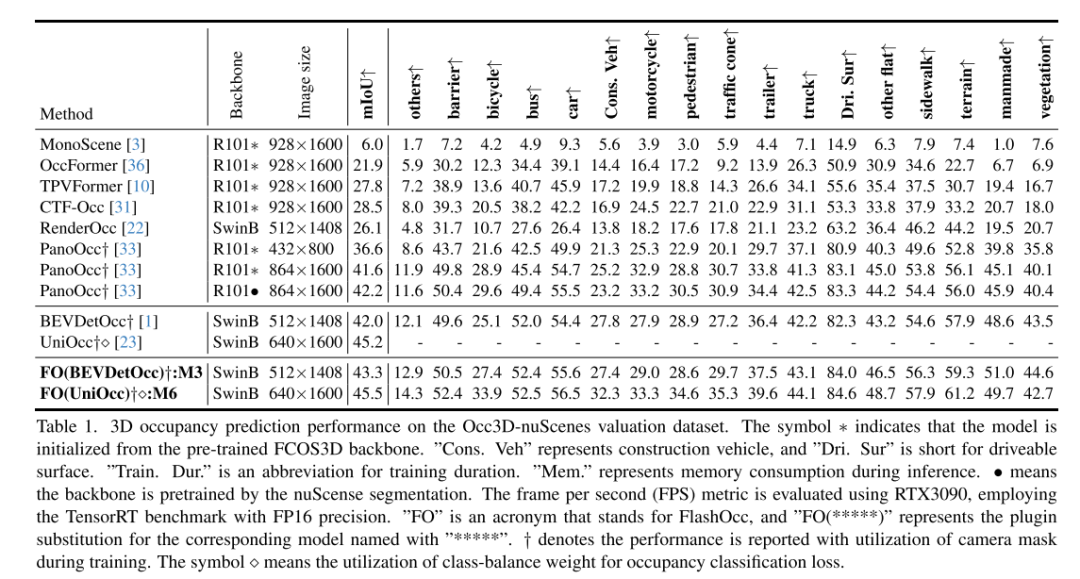
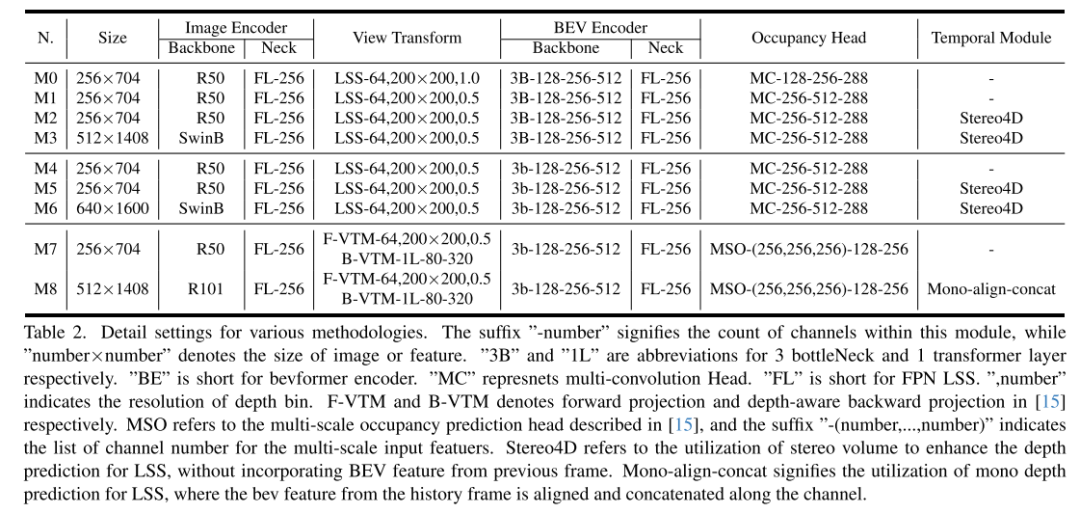
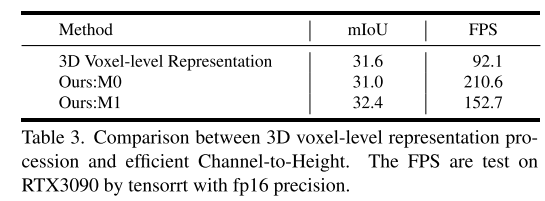
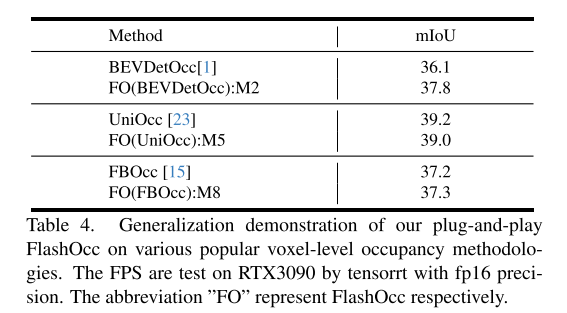
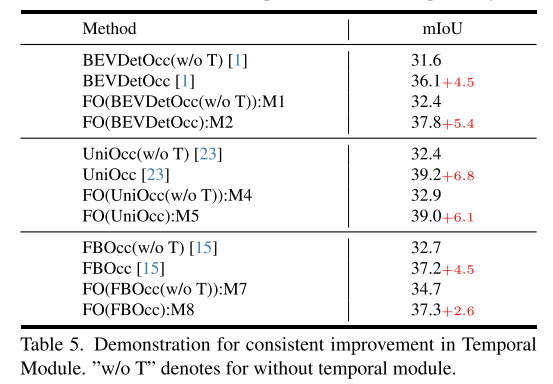
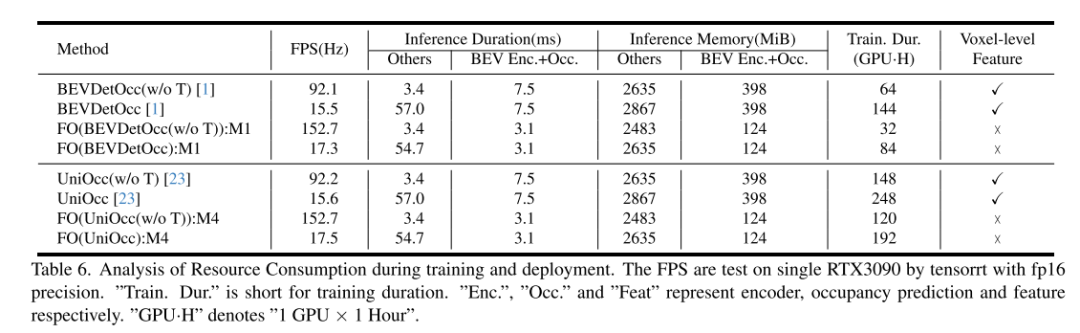
总结:
本文介绍了一种名为FlashOCC的即插即用方法,旨在实现快速且内存高效的占用预测。此方法使用2D卷积直接替换基于体素的占用方法中的3D卷积,并结合通道到高度变换(channel-to-height transformation)将扁平化的BEV特征重新塑造为占用logits。FlashOCC已在多种体素级占用预测方法中证明了其有效性和通用性。大量实验证明该方法在精度、时间消耗、内存效率和部署友好性方面优于以前最先进的方法。据本文所知,FlashOCC是第一个将sub-pixel范式(Channel-to-Height)应用于占用任务的方法,专门利用BEV级特征,完全避免使用计算3D(可变形)卷积或transformer模块。可视化结果令人信服地证明FlashOCC成功保留了高度信息。在未来的工作中,该方法将被集成到自动驾驶的感知管道中,旨在实现高效的on-chip部署
引用:
Yu, Z., Shu, C., Deng, J., Lu, K., Liu, Z., Yu, J., Yang, D., Li, H., & Chen, Y. (2023). FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin. ArXiv. /abs/2311.12058

原文链接:https://mp.weixin.qq.com/s/JDPlWj8FnZffJZc9PIsvXQ
以上就是FlashOcc:占用预测新思路,精度、效率和内存占用新SOTA!的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/457153.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫