
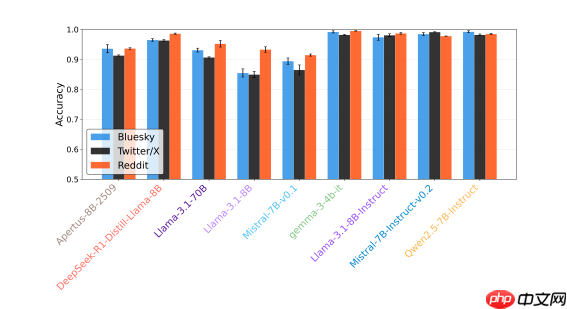
苏黎世大学、阿姆斯特丹大学、杜克大学以及纽约大学的联合研究团队近期公布了一项关于大语言模型在社交媒体内容生成方面表现的研究成果。研究发现,当前AI生成的社交平台帖子普遍存在可识别性问题,人类用户能够以高达70%至80%的准确率将其与真人发布的内容区分开来,显著高于随机判断的概率。
该研究涵盖了九个主流大语言模型,包括Apertus、DeepSeek、Gemma、Llama、Mistral和Qwen等,评估它们在Bluesky、Reddit和X三大社交平台上的文本生成能力。
分析结果显示,AI生成内容在“毒性评分”上呈现出明显特征,成为人类辨别其来源的关键线索之一。例如,当一条帖子引发极具讽刺意味或情绪强烈的评论时,这类互动更可能来自真实用户而非AI。这反映出AI在模拟真实社交语境中的局限性。
 AI社交封面生成器
AI社交封面生成器
一句话/一张图一键智能生成社交媒体图片的AI设计神器
 30 查看详情
30 查看详情 
尽管大模型已能较好地复制网络对话的基本结构,但在表达自然情感和即兴反应方面仍存在明显短板。研究指出,真挚、自发的情感流露是人类交流的核心特质,而这一点恰恰是当前AI难以企及的。特别是在表达积极情绪(如在马斯克旗下的X平台上)或涉及敏感话题(如Reddit上的政治讨论)时,AI的表现尤为生硬和不自然。
整体而言,各模型在模仿X平台的内容风格时相对成功,而在Bluesky上的表现一般,面对Reddit则最为吃力——后者因其社区文化多样、对话规则复杂,对AI构成了更高挑战。值得注意的是,部分未经人类反馈微调(non-instruct fine-tuned)的原始模型反而展现出更强的隐蔽性,暗示过度优化可能导致输出风格趋于同质化,进而暴露其非人类身份。
以上就是AI 生成社交媒体内容易被识别,情感表达仍待提升的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/598981.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























