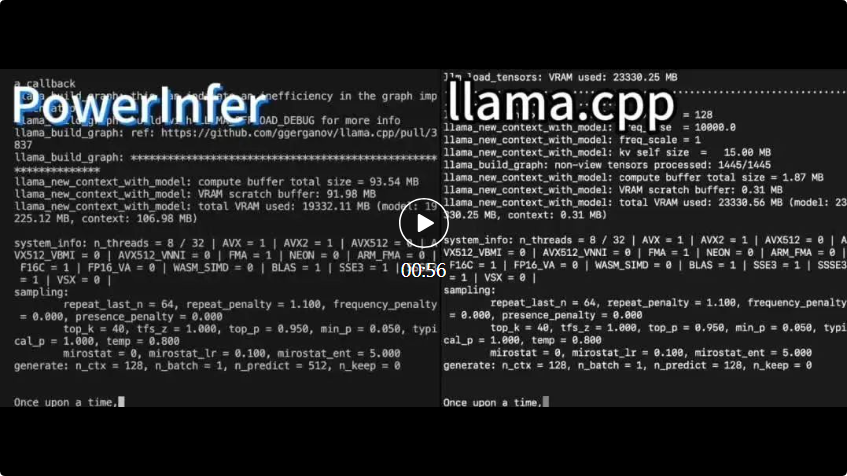
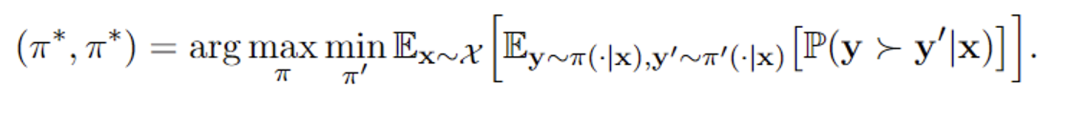单目动态场景(monocular dynamic scene)是指使用单眼摄像头观察和分析的动态环境,其中物体可以在场景中自由移动。单目动态场景重建在理解环境中的动态变化、预测物体运动轨迹以及生成动态数字资产等任务中具有关键意义。利用单目视觉技术,可以实现动态场景的三维重建和模型估计,帮助我们更好地理解和处理动态环境中的各种情况。这种技术不仅可应用于计算机视觉领域,还可以在自动驾驶、增强现实和虚拟现实等领域发挥重要作用。通过单目动态场景重建,我们可以更准确地捕捉环境中物体的运动
随着以神经辐射场(Neural Radiance Field, NeRF)为代表的神经渲染的兴起,越来越多的工作开始使用隐式表征(implicit representation)进行动态场景的三维重建。尽管基于 NeRF 的一些代表工作,如 D-NeRF,Nerfies,K-planes 等已经取得了令人满意的渲染质量,他们仍然距离真正的照片级真实渲染(photo-realistic rendering)存在一定的距离。
来自浙江大学和字节跳动的研究团队指出,上述问题的核心在于基于光线投射(ray casting)的 NeRF pipeline 通过逆向映射(backward-flow)将观测空间(observation space)映射到规范空间(canonical space)时出现了准确性和清晰性方面的挑战。逆向映射对于学习结构的收敛并不理想,导致目前的方法在 D-NeRF 数据集上仅能达到 30+ 级别的 PSNR 渲染指标。
为了解决这个挑战,该研究团队提出了一种基于光栅化的单目动态场景建模流程。他们首次将变形场与3D高斯结合,创造了一种新的方法,实现了高质量的重建和新视角渲染。这项研究论文《Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction》已被计算机视觉领域顶级国际学术会议CVPR 2024接受。这项工作中独特的地方在于,它是首个将变形场应用于3D高斯以拓展到单目动态场景的研究。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

项目主页:https://ingra14m.github.io/Deformable-Gaussians/
论文链接:https://arxiv.org/abs/2309.13101
代码:https://github.com/ingra14m/Deformable-3D-Gaussians
实验结果表明,变形场能够有效地将规范空间中的3D高斯前向映射精确地映射到观测空间。在D-NeRF数据集上,实现了10%以上的PSNR提升。此外,在真实场景中即使相机位姿不够准确,也能够增加渲染细节。

图 1 HyperNeRF 真实场景的实验结果。
相关工作
动态场景重建一直以来是三维重建的热点问题。随着以 NeRF 为代表的神经渲染实现了高质量的渲染,动态重建领域涌现出了一系列以隐式表征作为基础的工作。D-NeRF 和 Nerfies 在 NeRF 光线投射 pipeline 的基础上引入了变形场,实现了稳健的动态场景重建。TiNeuVox,K-Planes 和 Hexplanes 在此基础上引入了网格结构,大大加速了模型的训练过程,渲染速度有一定的提高。然而这些方法都基于逆向映射,无法真正实现高质量的规范空间和变形场的解耦。
3D 高斯泼溅是一种基于光栅化的点云渲染 pipeline。其 CUDA 定制的可微高斯光栅化 pipeline 和创新的致密化使得 3D 高斯不仅实现了 SOTA 的渲染质量,还实现了实时渲染。Dynamic 3D 高斯首先将静态的 3D 高斯拓展到了动态领域。然而,其只能处理多目场景非常严重地制约了其应用于更通用的情况,如手机拍摄等单目场景。
研究思想
Deformable-GS 的核心在于将静态的 3D 高斯拓展到单目动态场景。每一个 3D 高斯携带位置,旋转,缩放,不透明度和 SH 系数用于图像层级的渲染。根据 3D 高斯 alpha-blend 的公式,不难发现,随时间变化的位置,以及控制高斯形状的旋转和缩放是决定动态 3D 高斯的决定性参数。然而,不同于传统的基于点云的渲染方法,3D 高斯在初始化之后,位置,透明度等参数会随着优化不断更新。这给动态高斯的学习增加了难度。
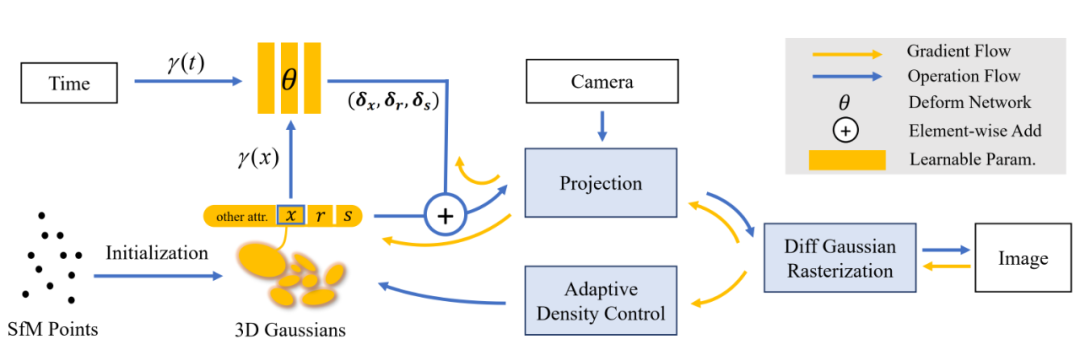
该研究创新性地提出了变形场与 3D 高斯联合优化的动态场景渲染框架。具体来说,该研究将 COLMAP 或随机点云初始化的 3D 高斯视作规范空间,随后通过变形场,以规范空间中 3D 高斯的坐标信息作为输入,预测每一个 3D 高斯随时间变化的位置和形状参数。利用变形场,该研究可以将规范空间的 3D 高斯变换到观测空间用于光栅化渲染。这一策略并不会影响 3D 高斯的可微光栅化 pipeline,经过其计算得到的梯度可以用于更新规范空间 3D 高斯的参数。
此外,引入变形场有利于动作幅度较大部分的高斯致密化。这是因为动作幅度较大的区域变形场的梯度也会相对较高,从而指导相应区域在致密化的过程中得到更精细的调控。即使规范空间 3D 高斯的数量和位置参数在初期也在不断更新,但实验结果表明,这种联合优化的策略可以最终得到稳健的收敛结果。大约经过 20000 轮迭代,规范空间的 3D 高斯的位置参数几乎不再变化。
研究团队发现真实场景的相机位姿往往不够准确,而动态场景更加剧了这一问题。这对于基于神经辐射场的结构来说并不会产生较大的影响,因为神经辐射场基于多层感知机(Multilayer Perceptron,MLP),是一个非常平滑的结构。但是 3D 高斯是基于点云的显式结构,略微不准确的相机位姿很难通过高斯泼溅得到较为稳健地矫正。
为了缓解这个问题,该研究创新地引入了退火平滑训练(Annealing Smooth Training,AST)。该训练机制旨在初期平滑 3D 高斯的学习,在后期增加渲染的细节。这一机制的引入不仅提高了渲染的质量,而且大幅度提高了时间插值任务的稳定性与平滑性。
图 2 展示了该研究的 pipeline,详情请参见论文原文。
 笔目鱼英文论文写作器
笔目鱼英文论文写作器
写高质量英文论文,就用笔目鱼
 87 查看详情
87 查看详情 
图 2 该研究的 pipeline。
结果展示
该研究首先在动态重建领域被广泛使用的 D-NeRF 数据集上进行了合成数据集的实验。从图 3 的可视化结果中不难看出,Deformable-GS 相比于之前的方法有着非常巨大的渲染质量提升。
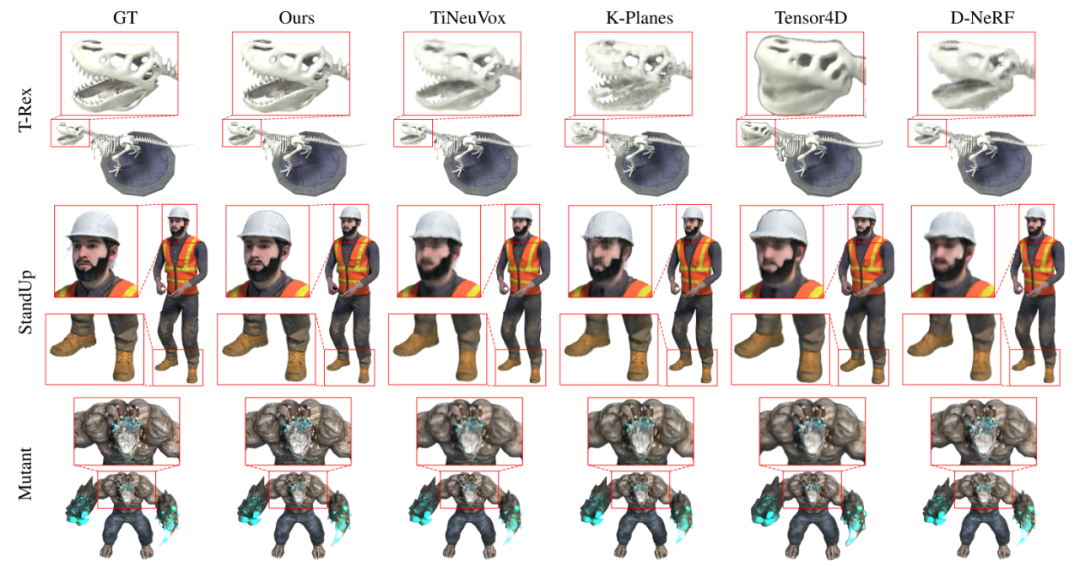

图 3 该研究在 D-NeRF 数据集上的定性实验对比结果。
该研究提出的方法不仅在视觉效果上取得了大幅度的提升,在渲染的定量指标上也有着相应的改进。值得注意的是,研究团队发现 D-NeRF 数据集的 Lego 场景存在错误,即训练集和测试集的场景具有微小的差别。这体现在 Lego 模型铲子的翻转角度不一致。这也是为什么之前方法在 Lego 场景的指标无法提高的根本原因。为了实现有意义的比较,该研究使用了 Lego 的验证集作为指标测量的基准。
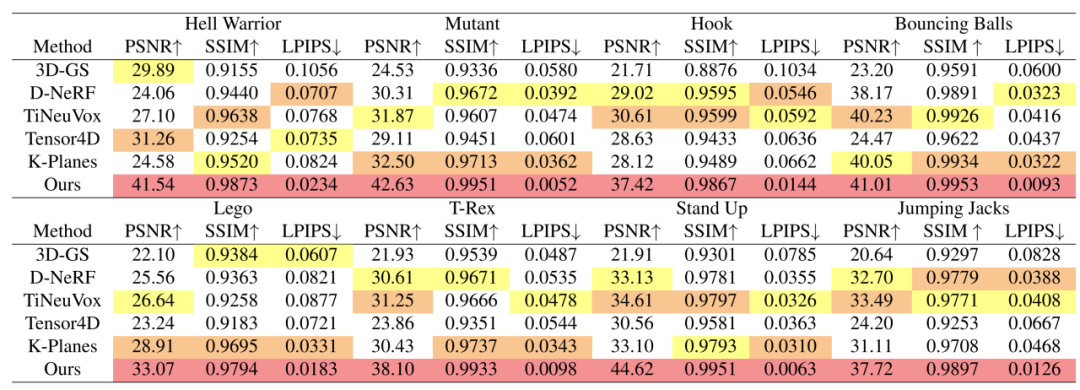
图 4 在合成数据集上的定量比较。
如图 4 所示,该研究在全分辨率(800×800)下对比了 SOTA 方法,其中包括了 CVPR 2020 的 D-NeRF,Sig Asia 2022 的 TiNeuVox 和 CVPR2023 的 Tensor4D,K-planes。该研究提出的方法在各个渲染指标(PSNR、SSIM、LPIPS),各个场景下都取得了大幅度的提高。
该研究提出的方法不仅能够适用于合成场景,在相机位姿不够准确的真实场景也取得了 SOTA 结果。如图 5 所示,该研究在 NeRF-DS 数据集上与 SOTA 方法进行了对比。实验结果表明,即使没有对高光反射表面进行特殊处理,该研究提出的方法依旧能够超过专为高光反射场景设计的 NeRF-DS,取得了最佳的渲染效果。

图 5 真实场景方法对比。

图6 深度可视化。
作者简介
论文通讯作者为浙江大学计算机科学与技术学院金小刚教授。
Email: jin@cad.zju.edu.cn
个人主页:http://www.cad.zju.edu.cn/home/jin/
以上就是CVPR 2024满分论文:浙大提出基于可变形三维高斯的高质量单目动态重建新方法的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/621008.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫