
一、抛砖引玉
经过一段时间的接触,大型语言模型(llm),展现出了令人惊叹的文本生成、对话和推理能力。它们饱读诗书、才华横溢,能够就几乎任何话题进行流畅的对话。然而,这个天才有一个致命的弱点:它的知识完全来源于其训练数据,存在截止日期,并且它有时会为了保持对话的流畅性而“捏造”事实。这种现象在ai领域被称为“幻觉”或“胡说八道”。想象一下,你结合实际问了一个问题,最新的员工报销政策是什么,llm可能会根据它训练时学到的通用财务知识,生成一个看似合理但完全错误的答案,因为它根本“不知道”你们公司今年刚修改的具体规定,这种幻觉在医疗、法律、金融等高风险领域是绝对不可接受的。
正是为了解决这一核心问题,RAG技术应运而生。它本质上是一种为LLM“赋能”的框架,让其能够从外部、权威、最新的知识源中获取信息,并基于这些真实信息生成答案,从而大幅提高回答的准确性和可靠性。
二、什么是RAG
RAG,全称为Retrieval-Augmented Generation,即“检索增强生成”,是检索、增强、生成的完美融合。我们可以将其拆解为三个关键步骤来理解:
检索: 当用户提出一个问题时,系统不会直接让LLM回答。而是首先将这个问题的核心语义,在一个预先设定好的外部知识库(如公司文档、产品手册、最新网页文章等)中进行搜索,找到与问题最相关的文档片段。 增强: 将这些检索到的、包含真实信息的文档片段,与用户的原始问题“打包”在一起,组合成一个新的、内容更丰富的“提示”。这个过程相当于为LLM提供了答题的参考资料。 生成: 最后,将这个增强了背景信息的提示发送给LLM,LLM基于这些可靠的参考资料,生成最终答案。
一个简单的类比:闭卷考试 vs 开卷考试
传统LLM(无RAG): 像一场闭卷考试。模型只能依靠自己记忆(训练数据)中的知识来答题。一旦题目超出它的记忆范围或记忆模糊,它就可能会猜错或编造。 RAG+LLM: 像一场开卷考试。允许模型在答题时先去查阅指定的、权威的参考资料(外部知识库),然后基于这些资料组织答案。这样得出的答案自然更准确、有据可循。
相比于另一种更新模型知识的方法——“微调”,RAG无需昂贵的重新训练成本,可以实时更新知识库,且答案的可追溯性更强,能知道答案来源于哪份文档,因此在实践中更具灵活性和成本效益。
三、RAG的核心组件
检索器: 通常由嵌入模型和向量数据库构成。嵌入模型负责将文本(无论是用户问题还是知识库文档)转换为数学意义上的向量,即一长串数字,这个向量可以代表文本的语义。向量数据库则存储了所有知识库文档的向量。检索的本质就是在这个向量空间中,快速找到与问题向量最相似的文档向量。 生成器: 即大型语言模型本身,它的角色是根据提供的资料“撰写”答案。
四、RAG的工作流程
知识库预处理: 首先,将外部知识源(如PDF、Word、网页)进行分块,通过嵌入模型转换为向量,并存入向量数据库。这一步是离线完成的。 用户提问: 用户提出一个问题,例如:“我们公司2024年的带薪年假政策有什么变化?” 检索相关文档: 系统使用相同的嵌入模型将用户问题转换为向量,然后在向量数据库中进行相似度搜索,找出最相关的几个文档片段(例如,《2024年人力资源政策更新V2.0》中的具体条款)。 增强提示: 系统将这些检索到的文档片段和用户问题组合成一个结构化的提示,例如: “请严格根据以下参考资料回答问题:[参考资料开始]文档1:… 自2024年1月1日起,员工带薪年假天数将根据司龄计算:1-3年增至7天,3-5年增至10天…[参考资料结束]问题:我们公司2024年的带薪年假政策有什么变化?” 生成答案: LLM接收到这个增强后的提示,它会严格遵守参考资料的内容生成答案:“根据公司2024年最新政策,带薪年假天数有所增加。具体变化为:司龄1-3年的员工,年假天数增至7天;司龄3-5年的员工,年假天数增至10天…” 这样生成的答案不仅准确,还能注明来源,极大提升了可信度。
原理流程图:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
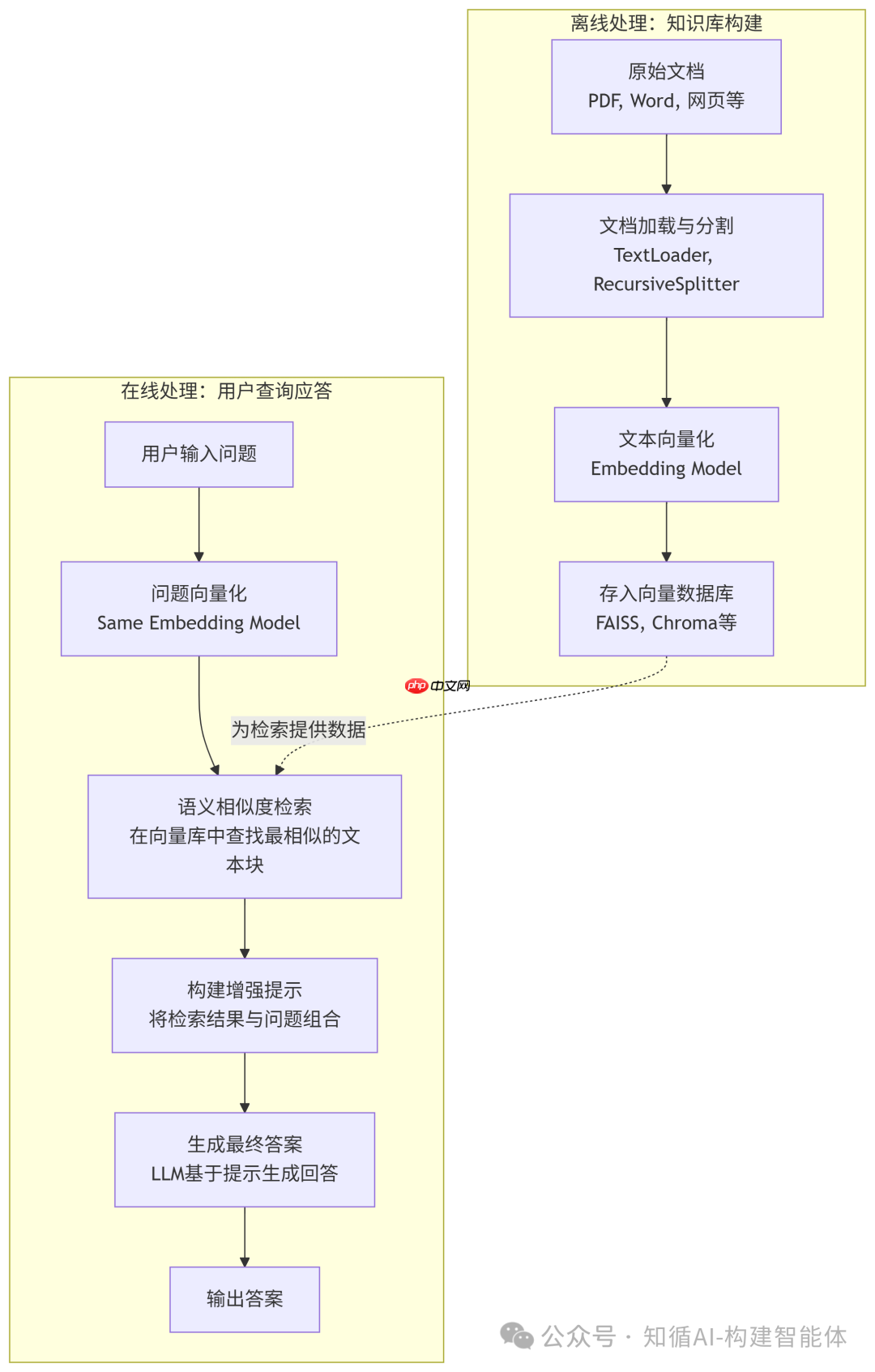
流程分析:
上述流程可以清晰地分为两个主要阶段:离线处理(知识库构建)和在线处理(用户查询应答)。
阶段一:离线处理 – 知识库构建
此阶段是准备工作,将原始知识源处理成可供快速检索的向量数据库,通常只需执行一次或在知识更新时重复执行。
1. 原始文档加载
从各种来源(如公司内部的PDF手册、Word文档、官网网页、Markdown文件等)加载原始文本数据。例如一家电商公司希望构建一个客服机器人,它加载了《退货政策文档》、《配送范围说明》、《最新促销活动页面》和《常见问题解答(FAQ)》作为其知识源。
2. 文档分割
使用文本分割器(如 RecursiveCharacterTextSplitter)将长文档切割成较小的、语义完整的“块”(chunks)。这是因为大语言模型(LLM)和嵌入模型都有输入长度限制,且小块信息更利于精准检索。例如一篇长达10页的《退货政策》被分割成多个小块,例如“7天无理由退货条件”、“退货物流流程”、“退款到账时间”等独立的段落。
3. 文本向量化 (Embedding)
使用嵌入模型(Embedding Model)将每个文本块转换为一个高维向量(即一组数字)。这个向量代表了文本的语义信息。语义相似的文本,其向量在空间中的距离也更近。例如文本块“退款通常需要1-7个工作日到账”和“请问我的退款多久可以到银行卡?”这两个语义相似的句子,经过嵌入模型转换后,它们的向量在数学空间中的“距离”会非常近。
4. 存入向量数据库
将所有文本块对应的向量以及原始的文本内容,存储到专门的向量数据库(如FAISS、Chroma、Pinecone)中。这种数据库针对“近似最近邻(ANN)”搜索进行了优化,能快速找到相似的向量。例如将所有关于退货、配送、促销的文本块向量存入数据库,构建成一个专属于该电商公司的“知识大脑”。
阶段二:在线处理 – 用户查询应答
此阶段是实时响应用户查询的流程,每次用户提问都会触发以下步骤。
1. 用户输入问题 (Query)
用户提出一个自然语言问题。例如用户问:“请问商品破损了,如何申请退货?”
2. 问题向量化 (Query Embedding)
使用同一个嵌入模型将用户的问题也转换为一个向量。例子:将“商品破损了,如何申请退货?”转换为一个向量。这个向量会与向量数据库中所有关于“破损退货”的文本块向量很相似。
3. 语义相似度检索
在向量数据库中进行相似度搜索(计算余弦相似度或欧氏距离),寻找与“问题向量”最相似的“文本块向量”(通常返回前k个,如前3个)。这一步是RAG的核心,它找到了回答问题最相关的原始材料。例如系统检索到最相关的文本块是:《退货政策》中的“商品破损退货流程”段落和FAQ中的“如何处理运输途中损坏的商品”。
4. 构建增强提示
将检索到的多个相关文本块(作为上下文背景)与用户的原始问题组合成一个新的、内容丰富的提示(Prompt),并发送给大语言模型(LLM)。这是“增强”的关键一步。例如组合成的提示可能看起来像这样:
“请严格根据以下背景信息回答问题:
[背景信息开始]
 Cowriter
Cowriter
AI 作家,帮助加速和激发你的创意写作
 107 查看详情
107 查看详情 
如收到商品破损,请拍摄破损部位照片,在订单页面提交退货申请并上传照片,审核通过后客服将联系您安排上门取件。
运输途中损坏的商品可全额退款,无需承担退回运费。
[背景信息结束]
问题:请问商品破损了,如何申请退货?”
5. 生成最终答案
LLM接收到这个“增强后”的提示,它会严格遵守提供的背景信息来组织语言,生成一个准确、可靠且流畅的自然语言答案。因为它有了“参考资料”,所以极大地避免了幻觉。
针对上一部的问题,LLM可能生成:
“1. 如果您收到的商品有破损,请按以下步骤操作:
2. 拍摄清晰的商品破损部位照片。
3. 登录您的账户,找到相应订单,提交退货申请。
4. 在申请中上传破损照片以供审核。
5. 审核通过后,我们的客服会联系您安排免费上门取件服务。您无需支付退回运费。”
(答案完全来源于知识库,且格式清晰)
6. 输出答案
将LLM生成的答案返回给用户,完成一次查询。
通过这个流程,RAG成功地将大语言模型的强大生成能力与外部知识源的准确性、实时性结合了起来,既利用了LLM的理解和表达能力,又将其“框定”在可靠的信息范围内,从而生产出既流畅又可信的答案。
五、基于RAG的问答系统
下面我们实现一个基于RAG的问答系统,结合前期的知识点,使用了阿里千问模型(qwen-max)作为生成模型,使用ModelScope的嵌入模型(damo/nlp_corom_sentence-embedding_chinese-base)来生成文本的向量表示,处理文本向量化,并使用FAISS作为向量数据库进行高效相似性检索,从而实现完整的RAG流程:文档处理→向量化→检索→增强提示→生成回答;
代码示例:
import osfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.vectorstores import FAISS # 使用FAISS替代Chromafrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.document_loaders import TextLoaderfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.schema import Documentfrom typing import Listimport requestsimport jsonimport dashscopefrom dashscope import Generationfrom modelscope import snapshot_downloadfrom modelscope.models import Modelfrom modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasks# 配置阿里千问模型class QwenLLM: def __init__(self): # 设置阿里云API密钥 self.api_key = os.environ["DASHSCOPE_API_KEY"] # 从环境变量获取API密钥 dashscope.api_key = self.api_key # 设置dashscope的API密钥 def invoke(self, prompt: str) -> str: try: # 调用阿里千问大模型API生成回答 response = Generation.call( model="qwen-max", # 使用千问最大模型 prompt=prompt, # 传入提示词 temperature=0.1, # 低温度值使输出更确定性 top_p=0.9, # 核采样参数,控制生成多样性 result_format='message' # 返回消息格式 ) # 检查响应状态 if response.status_code == 200: return response.output.choices[0].message.content # 返回模型生成的内容 else: return f"请求失败: {response.message}" # 返回错误信息 except Exception as e: return f"请求异常: {str(e)}" # 返回异常信息# 从ModelScope下载并使用嵌入模型class ModelScopeEmbeddings: def __init__(self, model_name="damo/nlp_corom_sentence-embedding_chinese-base"): # 从ModelScope下载中文句子嵌入模型 self.model_dir = snapshot_download(model_name, cache_dir='D:modelscopehubmodels') print(f"模型已下载到: {self.model_dir}") # 使用HuggingFaceEmbeddings包装ModelScope模型,使其兼容LangChain self.embeddings = HuggingFaceEmbeddings( model_name=self.model_dir, # 使用下载的模型路径 model_kwargs={'device': 'cpu'}, # 指定使用CPU设备 encode_kwargs={'normalize_embeddings': True} # 对嵌入向量进行归一化 ) def embed_documents(self, texts: List[str]) -> List[List[float]]: """将文档列表转换为嵌入向量""" return self.embeddings.embed_documents(texts) def embed_query(self, text: str) -> List[float]: """将查询文本转换为嵌入向量""" return self.embeddings.embed_query(text)# 初始化RAG系统def setup_rag_system(knowledge_texts: List[str]): # 1. 文本分割 - 将长文本分割成适合处理的小块 text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 每个文本块的最大字符数 chunk_overlap=50, # 块之间的重叠字符数,保持上下文连贯 length_function=len # 使用Python内置len函数计算长度 ) # 创建文档对象 documents = [] for i, text in enumerate(knowledge_texts): docs = text_splitter.split_text(text) # 分割文本 for doc in docs: # 创建LangChain文档对象,包含内容和元数据 documents.append(Document(page_content=doc, metadata={"source": f"doc_{i}"})) # 2. 初始化ModelScope嵌入模型 embeddings = ModelScopeEmbeddings() # 3. 创建FAISS向量数据库 - 高效的相似性搜索库 vectorstore = FAISS.from_documents( documents=documents, # 文档列表 embedding=embeddings.embeddings # 嵌入模型 ) return vectorstore, embeddings # 返回向量存储和嵌入模型# 构建RAG链def create_rag_chain(vectorstore, embeddings): # 创建检索器 - 用于从向量库中搜索相关文档 retriever = vectorstore.as_retriever( search_type="similarity", # 使用相似性搜索 search_kwargs={"k": 3} # 返回最相关的3个文档 ) # 定义提示模板 - 指导模型如何基于上下文回答问题 template = """ 你是一个专业的助手,请根据以下背景信息回答问题。 背景信息: {context} 问题:{question} 请根据背景信息提供准确、简洁的回答。如果背景信息中没有相关答案,请如实告知。 """ prompt = ChatPromptTemplate.from_template(template) # 创建提示模板 # 创建RAG处理函数 def rag_chain(question: str) -> str: # 检索相关文档 - 基于问题查找最相关的文档片段 relevant_docs = retriever.invoke(question) # 合并检索到的文档内容作为上下文 context = "".join([doc.page_content for doc in relevant_docs]) # 构建提示 - 将上下文和问题填入模板 formatted_prompt = prompt.invoke({ "context": context, "question": question }) # 调用千问模型生成回答 qwen_llm = QwenLLM() response = qwen_llm.invoke(str(formatted_prompt)) return response, context # 返回模型回答和使用的上下文 return rag_chain # 返回RAG处理函数# 示例知识库数据knowledge_data = [ """ 人工智能发展趋势:2024年,生成式AI技术将继续快速发展,多模态能力成为重点。 企业应用AI的主要方向包括智能客服、内容生成、数据分析等。深度学习和神经网络 技术不断突破,大模型参数规模持续增长。 """, """ 公司规章制度:员工工作时间为每周5天,每天8小时。年假根据工龄计算,1-3年员工 享有5天年假,3-5年员工享有10天年假。所有员工需要遵守保密协议,不得泄露公司 商业秘密和技术信息。 """, """ 产品介绍:我司主要产品包括智能客服系统、企业知识管理平台和AI内容生成工具。 智能客服系统支持多渠道接入,能够自动回答常见问题,提升客户服务效率。知识管理 平台帮助企业构建专属知识库,实现知识的集中管理和智能检索。 """]# 初始化RAG系统print("正在初始化RAG系统...")vectorstore, embeddings = setup_rag_system(knowledge_data)rag_chain = create_rag_chain(vectorstore, embeddings)# 进行问答测试questions = [ "公司的年假政策是怎样的?", "智能客服系统有哪些功能?", "2024年AI发展趋势是什么?"]for question in questions: print(f"问题:{question}") answer, context = rag_chain(question) print(f"答案:{answer}") print(f"检索到的上下文:{context[:100]}...") # 只显示前100个字符
代码结构说明:
1. 导入必要的库。
2. 定义QwenLLM类:用于调用阿里千问模型生成答案。
3. 定义ModelScopeEmbeddings类:从ModelScope下载嵌入模型,并用HuggingFaceEmbeddings进行包装,处理中文文本嵌入,将文本转换为向量表示。
4. setup_rag_system函数:处理知识库文本,分割文本,初始化嵌入模型,创建FAISS向量数据库。初始化RAG系统,处理文档分割和向量库构建。
5. create_rag_chain函数:创建RAG链,包括检索器、提示模板和调用千问模型生成答案的函数。完整的RAG处理流水线。
6. 示例知识库数据:包含三个方面的文本。
7. 初始化RAG系统并进行问答测试。
注意:代码中使用了dashscope库调用千问模型,需要设置DASHSCOPE_API_KEY环境变量。
代码执行会先下载指定模型
运行结果:
正在初始化RAG系统...Downloading Model from ModelScope 魔搭社区 to directory: D:modelscopehubmodelsdamolp_corom_sentence-embedding_chinese-base2025-08-29 15:09:10,402 - modelscope - WARNING - Model revision not specified, use revision: v1.1.0模型已下载到: D:modelscopehubmodelsdamolp_corom_sentence-embedding_chinese-base问题:公司的年假政策是怎样的?答案:根据公司规章制度,年假政策如下:- 工龄在1至3年的员工享有5天年假。- 工龄在3至5年的员工享有10天年假。检索到的上下文:公司规章制度:员工工作时间为每周5天,每天8小时。年假根据工龄计算,1-3年员工 享有5天年假,3-5年员工享有10天年假。所有员工需要遵守保密协议,不得泄露公司 商业秘密和技术信息。...问题:智能客服系统有哪些功能?答案:根据背景信息,智能客服系统的主要功能包括:- **多渠道接入**:支持通过多种沟通渠道(如网站、社交媒体等)与客户进行互动。- **自动回答常见问题**:能够识别并自动回复客户的常见咨询,提高服务效率。这些功能旨在提升客户服务体验的同时,也帮助企业更高效地管理客户关系。检索到的上下文:产品介绍:我司主要产品包括智能客服系统、企业知识管理平台和AI内容生成工具。 智能客服系统支持多渠道接入,能够自动回答常见问题,提升客户服务效率。知识管理 平台帮助企业构建专属知识库,...问题:2024年AI发展趋势是什么?答案:2024年AI发展趋势主要体现在生成式AI技术的持续快速发展上,其中多模态能力成为重点发展方向。同时,深度学习和神经网络技术也将不断取得新突破,大模型的参数规模会继续增长。这些技术进步将推动企业在智能客服、内容生成、数据分析等领域的应用更加广泛和深入。检索到的上下文:人工智能发展趋势:2024年,生成式AI技术将继续快速发展,多模态能力成为重点。 企业应用AI的主要方向包括智能客服、内容生成、数据分析等。深度学习和神经网络 技术不断突破,大模型参数...六、RAG的应用场景
智能客服与问答机器人:电商、SaaS企业的客服系统。 企业知识库管理:任何拥有大量内部文档(操作手册、规章制度、项目报告)的大中型企业。 内容创作与市场研究:市场分析师、内容写手。可以让RAG系统先从最新的行业报告、财经新闻、财报电话会议记录中检索相关信息。LLM基于这些新鲜出炉的数据,帮助他生成一份论据充分、数据翔实的文章大纲或初稿,极大提升了研究效率和内容质量。 教育与个性化学习:在线教育平台,RAG系统可以从教科书、相对论科普文章、教学视频讲义等多样化资料中检索出最适合该学生理解水平的解释,然后让LLM整合成一个深入浅出的答案,从而实现因材施教。
七、总结
RAG技术通过巧妙地结合信息检索与大型语言模型,为解决LLM的“幻觉”问题提供了一条高效且实用的路径。它极大地增强了AI在专业和实时领域应用的可靠性和可信度,是AI真正融入企业核心工作流的关键一步。
但RAG技术仍面临一些挑战和发展方向,如何更精准地找到最相关的片段、处理复杂多步问题的能力,简化多轮检索、多模态RAG,不仅能处理文本,还能理解图片、表格中的信息,以及溯源验证,如何更直观地向用户展示答案来源,确保透明度。所以我们广大的IT工作者,既是指引,也是被指引,技术永远革新,我们也会持续突破。加油,奥里给!

以上就是构建AI智能体:大模型的幻觉难题:RAG 解决AI才华横溢却胡言乱语的弊病的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/986318.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















