
工程
-
Make U-Nets Great Again!北大&华为提出扩散架构U-DiT,六分之一算力即可超越DiT




☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢…
-
上交大o1复现新突破:蒸馏超越原版,警示AI研发”捷径陷阱”



☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢…
-
文本、图像、点云任意模态输入,AI能够一键生成高质量CAD模型了

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢…
-
跨模态大升级!少量数据高效微调,LLM教会CLIP玩转复杂文本


在当今多模态领域,clip 模型凭借其卓越的视觉与文本对齐能力,推动了视觉基础模型的发展。clip 通过对大规模图文对的对比学习,将视觉与语言信号嵌入到同一特征空间中,受到了广泛应用。 然而,CLIP 的文本处理能力被广为诟病,难以充分理解长文本和复杂的知识表达。随着大语言模型的发展,新的可能性逐渐…
-
HuggingFace工程师亲授:如何在Transformer中实现最好的位置编码
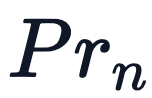

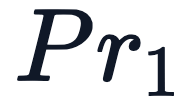

一个有效的复杂系统总是从一个有效的简单系统演化而来的。——John Gall 在 Transformer 模型中,位置编码(Positional Encoding) 被用来表示输入序列中的单词位置。与隐式包含顺序信息的 RNN 和 CNN 不同,Transformer 的架构中没有内置处理序列顺序的…
-
官宣开源 阿里云与清华大学共建AI大模型推理项目Mooncake
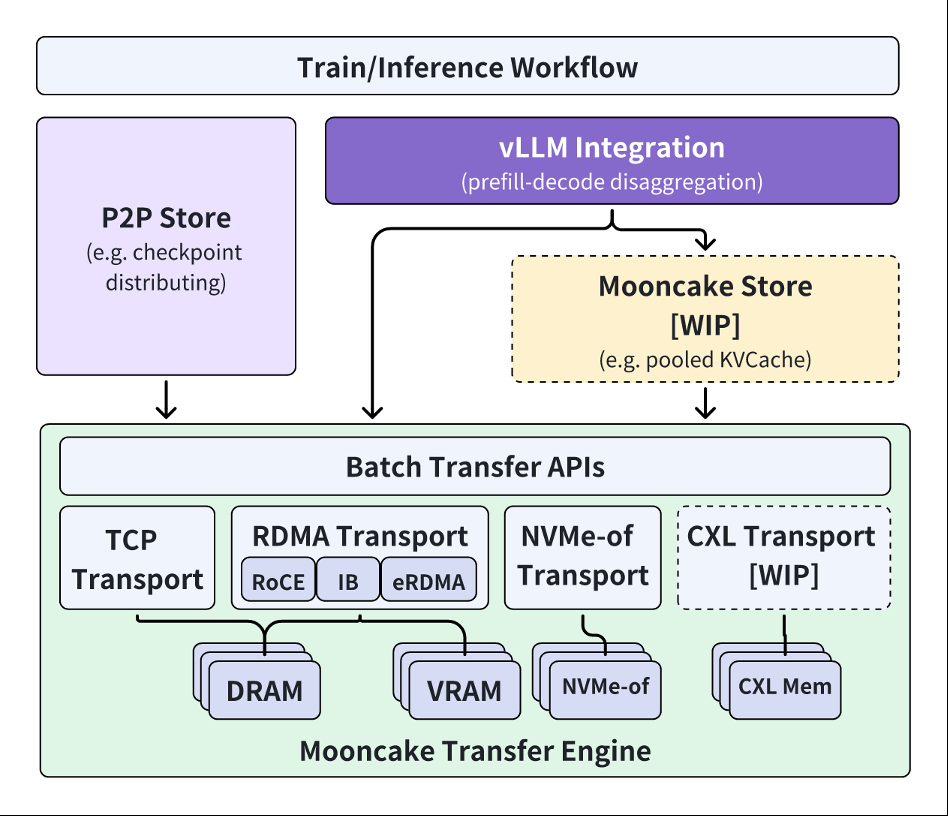

2024年6月,国内领先的大模型应用kimi携手清华大学madsys实验室,联合发布了基于kvcache的大模型推理架构mooncake。该架构通过pd分离和存算一体化设计,显著提升了kimi智能助手的推理吞吐量,并有效降低了推理成本,引发业界广泛关注。近日,清华大学、9#aisoft研究组织及阿里…
-
多模态慢思考:分解原子步骤以解决复杂数学推理


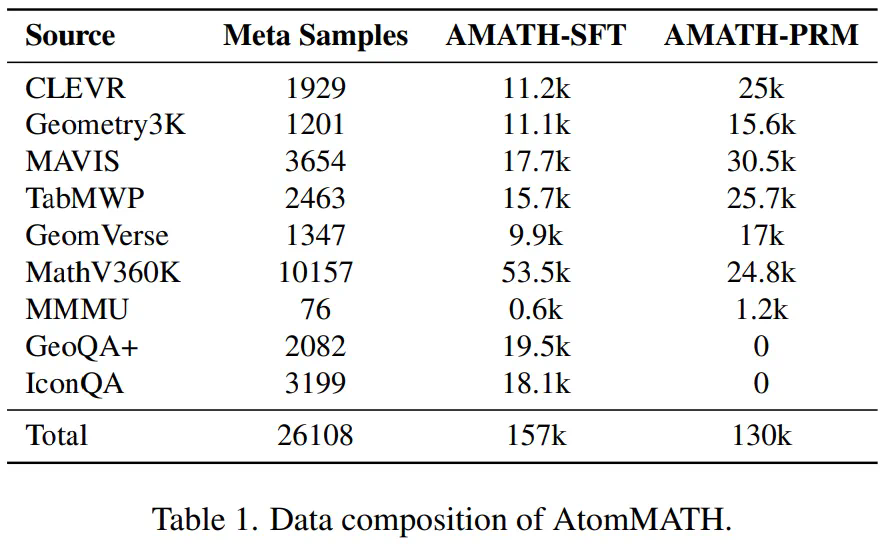

中山大学、香港科技大学、上海交通大学和华为诺亚方舟实验室的研究人员提出了一种名为 atomthink 的新框架,旨在提升多模态大语言模型 (mllm) 解决高级数学推理问题的能力。该框架通过将“慢思考”策略融入mllm,显著提高了模型在基准数学测试中的性能,并具有良好的可迁移性。 ☞☞☞AI 智能聊…
-
NeurIPS 2024 | 数学推理场景下,首个分布外检测研究成果来了
上海交通大学与阿里巴巴通义实验室合作,在neurips 2024上发表了一篇关于数学推理场景下分布外检测的论文,提出了名为“tv score”的全新算法。该算法利用动态嵌入轨迹,有效解决了传统静态嵌入方法在数学推理场景中失效的问题。 传统的分布外(OOD)检测方法主要针对翻译、摘要等任务,通过计算样…
-
NeurIPS 2024|杜克大学&谷歌提出SLED解码框架,无需外部数据与额外训练,有效缓解大语言模型幻觉,提高事实准确性
杜克大学和谷歌研究院的研究人员提出了一种名为自驱动logits进化解码(sled)的新型解码框架,旨在提高大型语言模型(llm)的事实准确性,无需外部知识库或额外微调。该研究成果已被neurips 2024收录,第一作者是杜克大学电子与计算机工程系博士生张健一。 LLM虽然性能卓越,但容易出现事实性…
-
推动大模型自我进化,北理工推出「流星雨计划」


北京理工大学计算机科学与技术学院的direct lab启动了“流星雨”研究计划,旨在探索大模型的自我进化理论与方法。该计划的核心思想源于人类个体能力提升的模式:在掌握基本技能后,通过与环境及自身的交互,不断学习和改进。 本文将重点介绍该计划在代码大模型和垂域大模型进化方面的成果。 SRA-MCTS:…


