
模型
-
开源大模型必须超越闭源——LeCun揭示2024年AI趋势图
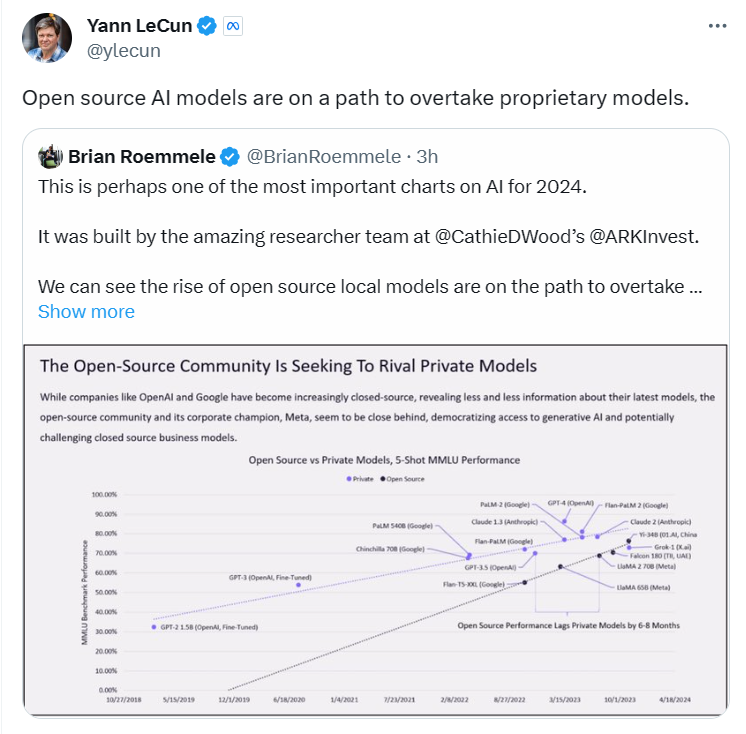
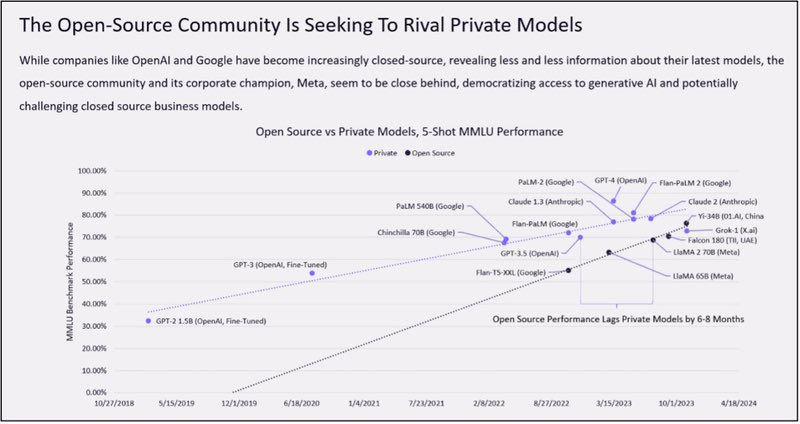


2023 年即将过去。一年以来,各式各样的大模型争相发布。当 OpenAI 和谷歌等科技巨头正在角逐时,另一方「势力」悄然崛起 —— 开源。 开源模型受到的质疑一向不少。它们是否能像专有模型一样优秀?是否能够媲美专有模型的性能?迄今为止,我们一直还只能说是某些方面接近。即便如此,开源模型总会给我们带…
-
更深层的理解视觉Transformer, 对视觉Transformer的剖析
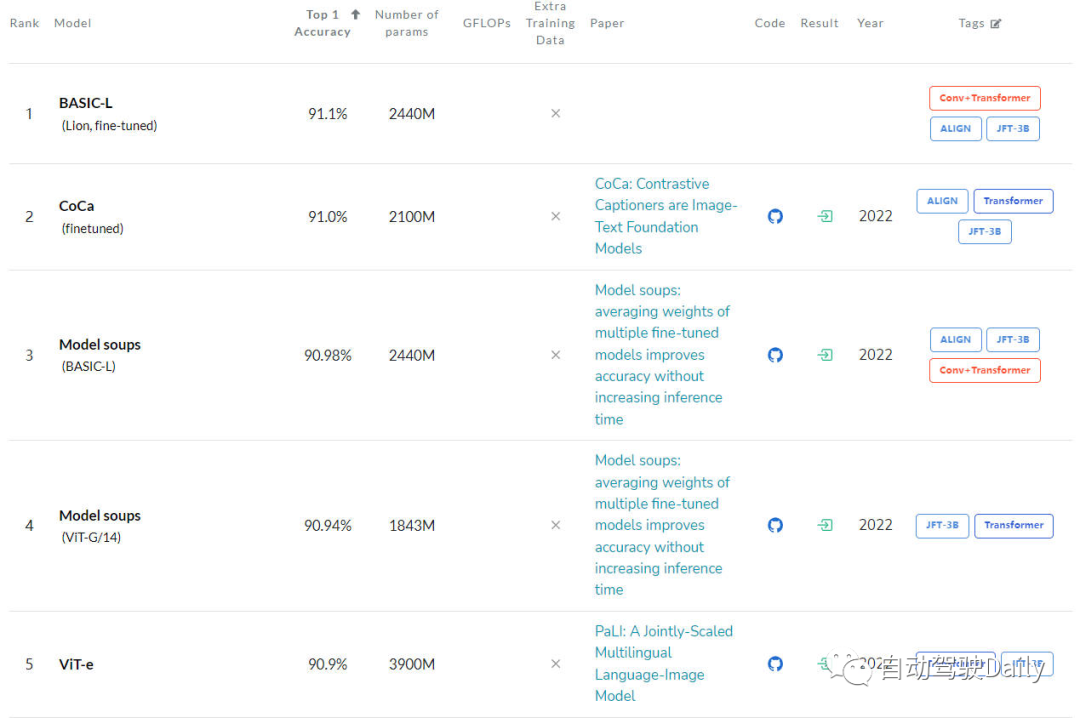
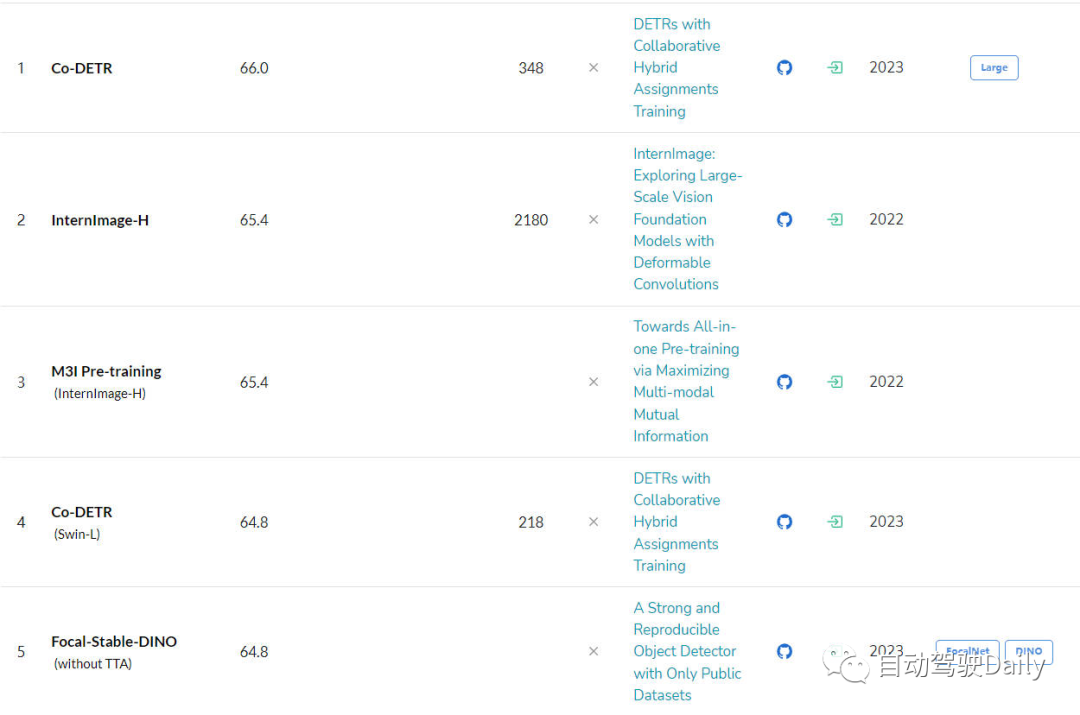
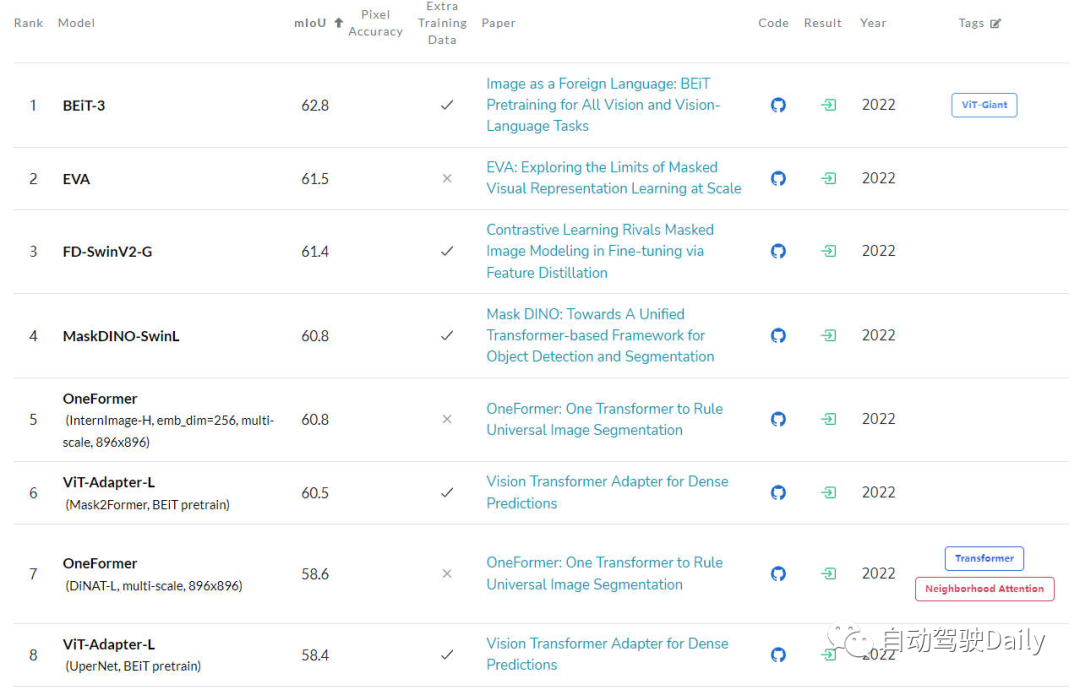

本文为经过自动驾驶之心公众号授权转载,请在转载时与出处联系 写在前面&&笔者的个人理解 目前,基于Transformer结构的算法模型已经在计算机视觉(CV)领域产生了极大的影响。它们在许多基本的计算机视觉任务上超越了以前的卷积神经网络(CNN)算法模型。以下是我找到的最新的不同基础…
-
基于Adaptor和GPT的时间序列多任务一体化大型模型
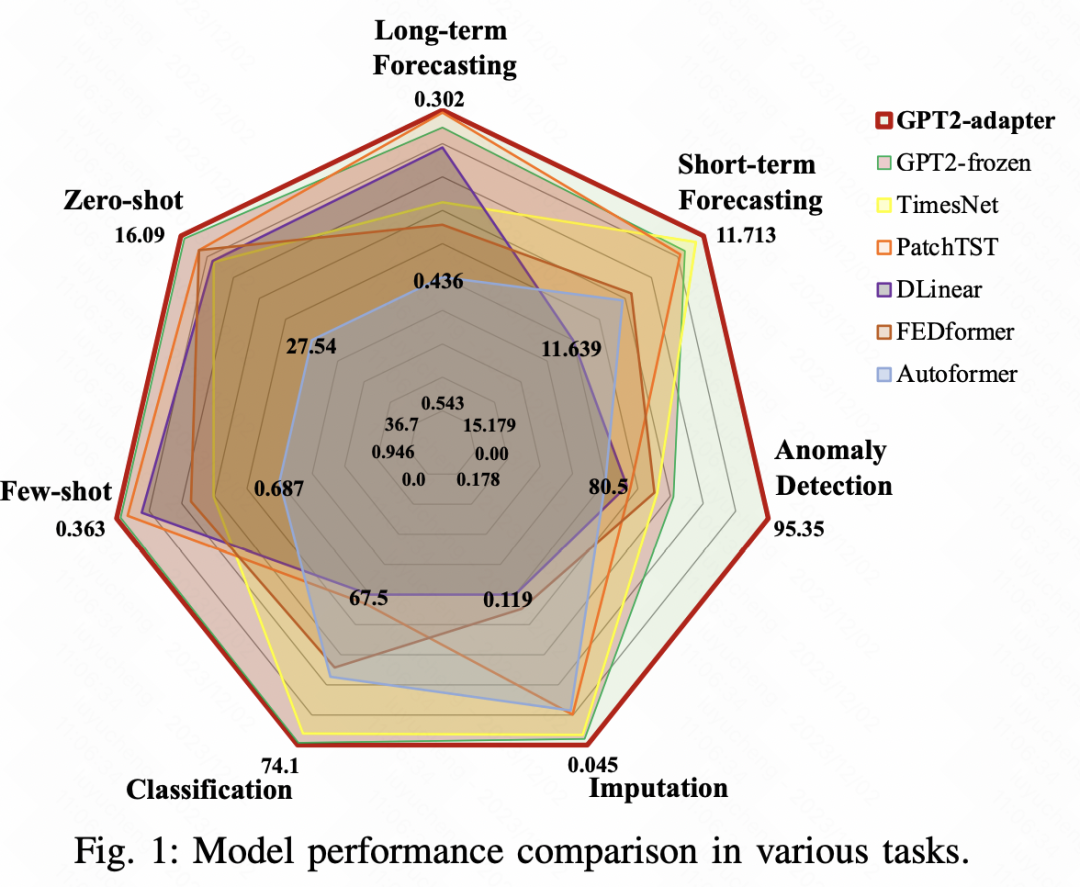
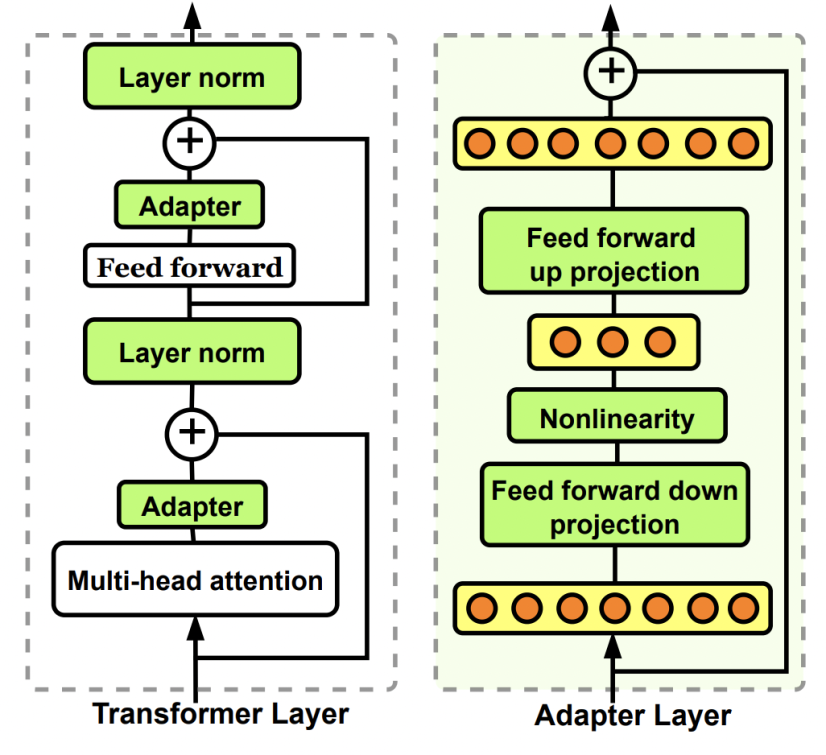
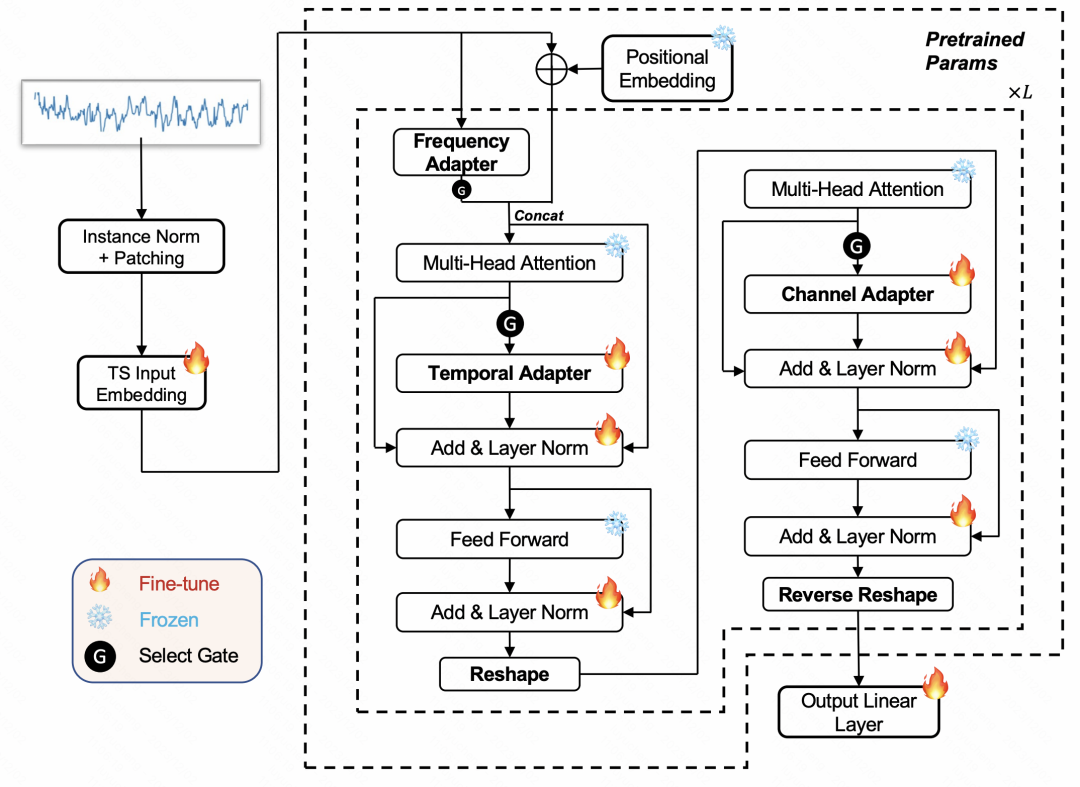

今天跟大家聊一聊大模型时间序列预测的最新工作,来自阿里巴巴达摩院,提出了一种基于adaptor的通用时间序列分析框架,在长周期预测、短周期预测、zero-shot、few-shot、异常检测、时间序列分类、时间序列填充等7项时间序列任务上都取得了显著的效果。 ☞☞☞AI 智能聊天, 问答助手, AI…
-
ReSimAD:如何通过虚拟数据提升感知模型的泛化性能

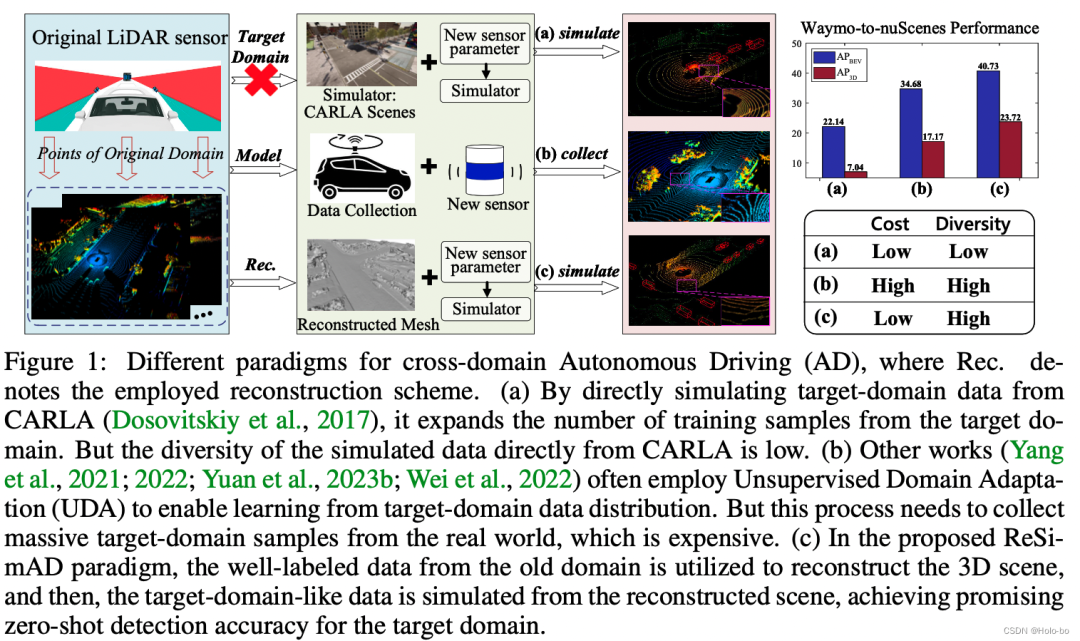
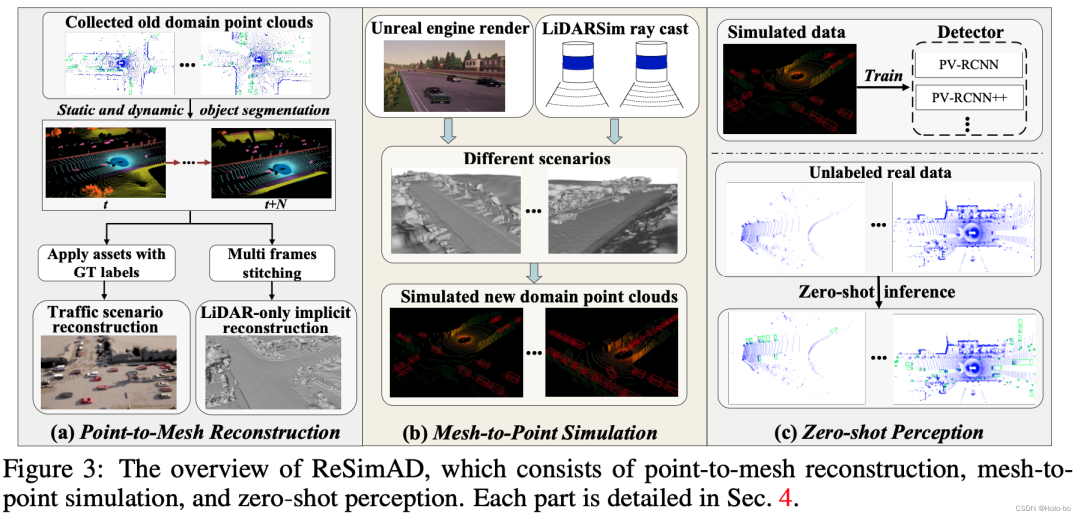
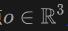
写在前面&笔者的个人理解 自动驾驶车辆传感器层面的域变化是很普遍的现象,例如在不同场景和位置的自动驾驶车辆,处在不同光照、天气条件下的自动驾驶车辆,搭载了不同传感器设备的自动驾驶车辆,上述这些都可以被考虑为是经典的自动驾驶域差异。这种域差异对于自动驾驶带来了挑战,主要因为依赖于旧域知识的自动…
-
UniVision引入新一代统一框架:BEV检测与Occupancy双任务达到最先进水平!
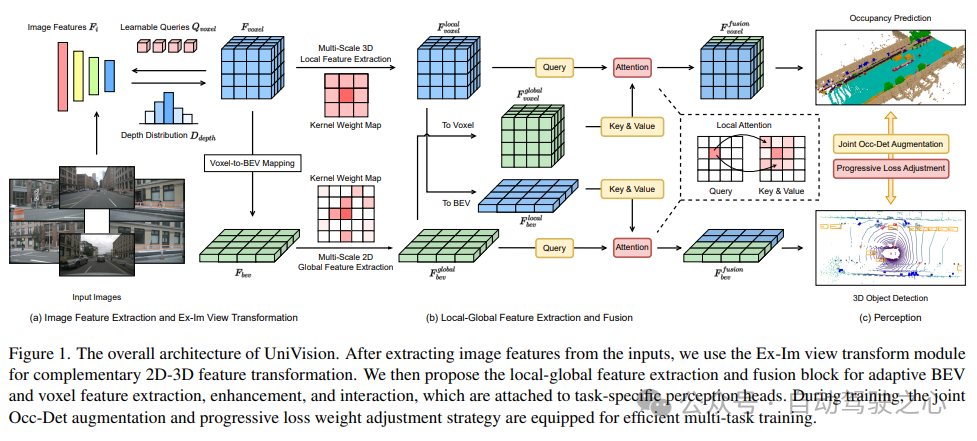
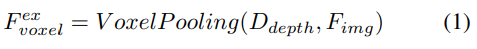
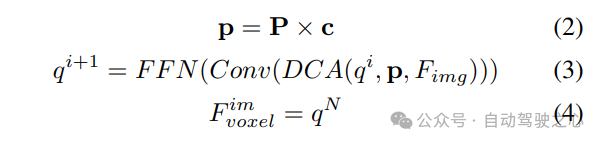
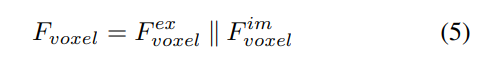
写在前面&个人理解 近年来,自动驾驶技术中以视觉为中心的3D感知得到了迅猛发展。尽管3D感知模型在结构和概念上相似,但在特征表示、数据格式和目标方面仍存在差距,这对设计统一高效的3D感知框架提出了挑战。因此,研究人员需要努力解决这些差距,以实现更准确、可靠的自动驾驶系统。通过合作和创新,我们…
-
RNN模型挑战Transformer霸权!1%成本性能比肩Mistral-7B,支持100+种语言全球最多


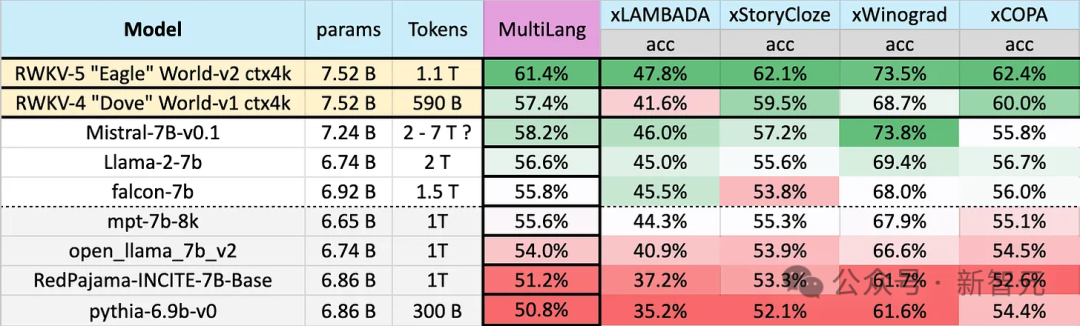

在大模型内卷的同时,transformer的地位也接连受到挑战。 近日,RWKV发布了Eagle 7B模型,基于最新的RWKV-v5架构。 Eagle 7B在多语言基准测试中脱颖而出,在英语测试中与顶尖模型不相上下。 同时,Eagle 7B用的是RNN架构,相比于同尺寸的Transformer模型,…
-
只需少量计算和内存资源即可运行的小型 Llama 大模型

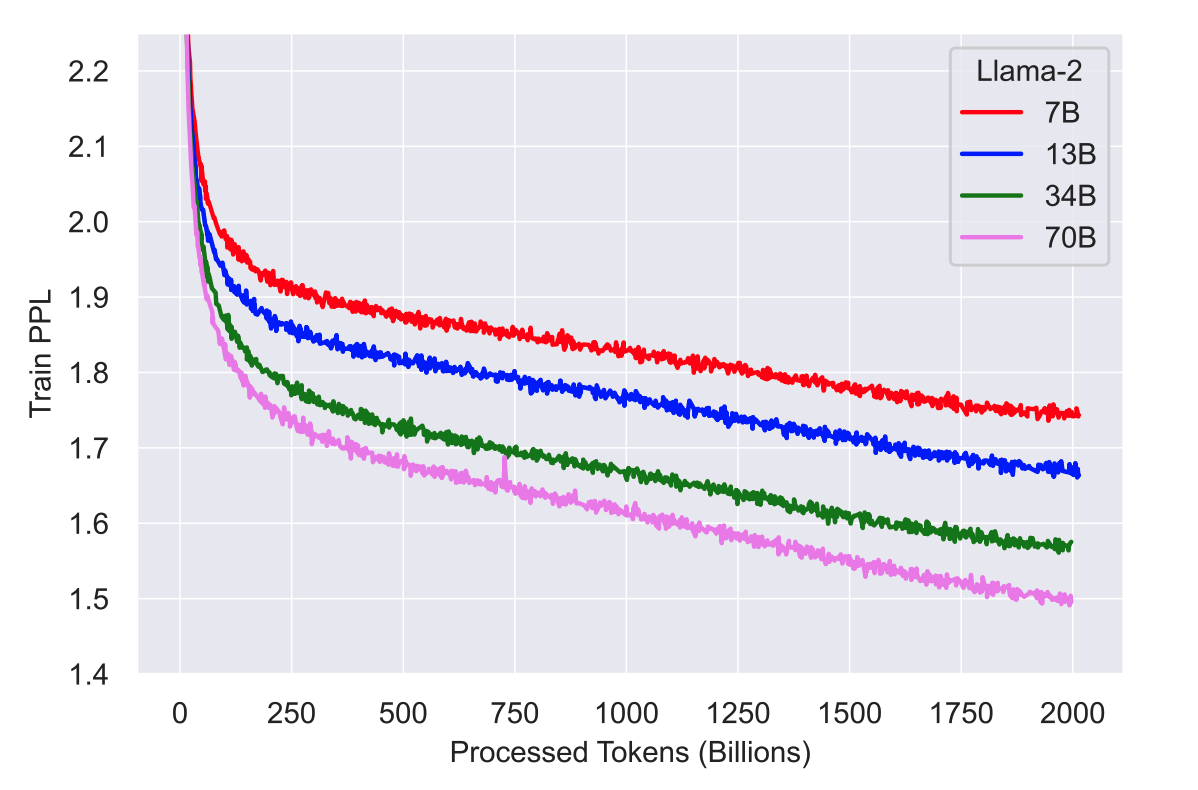
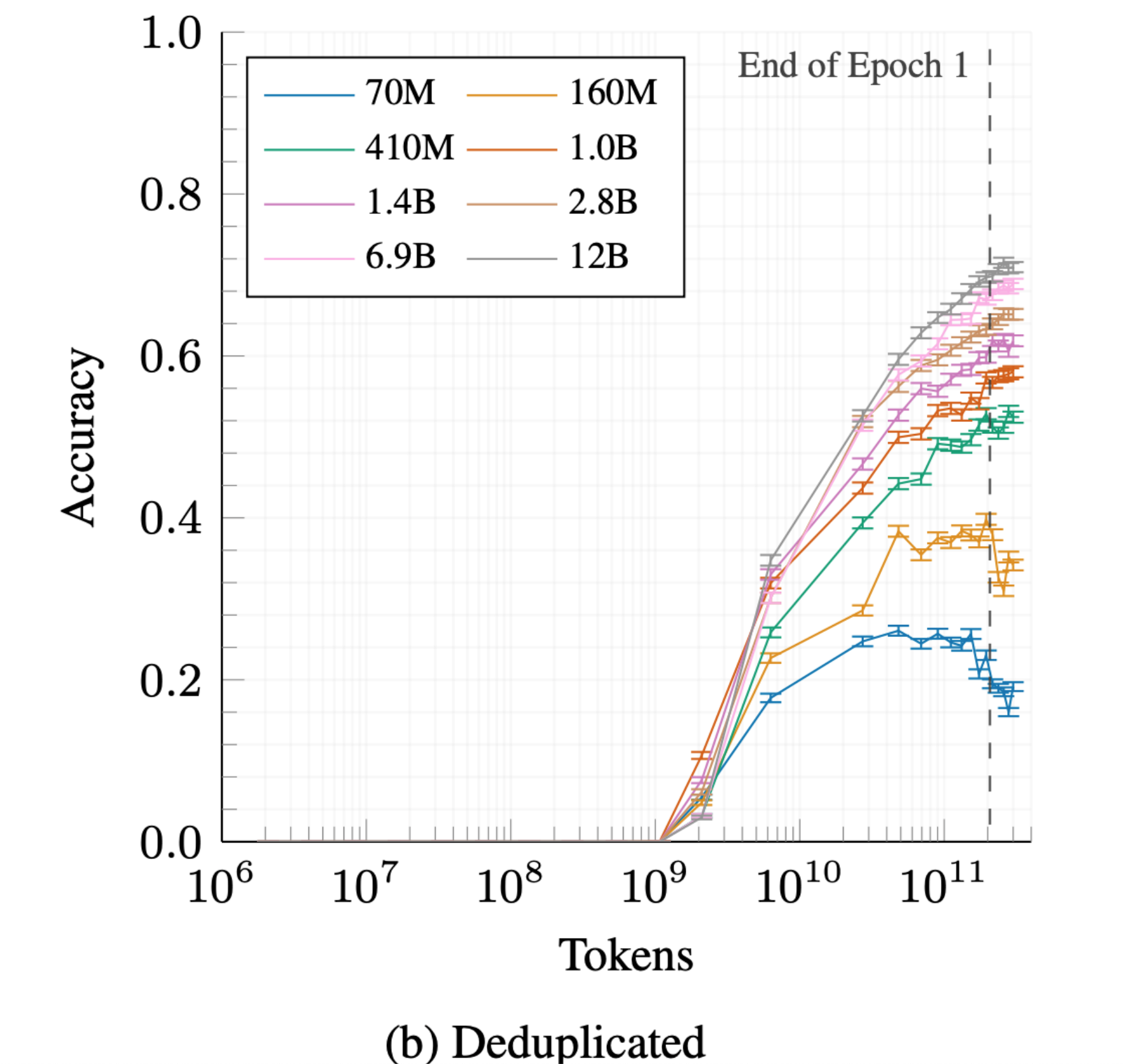
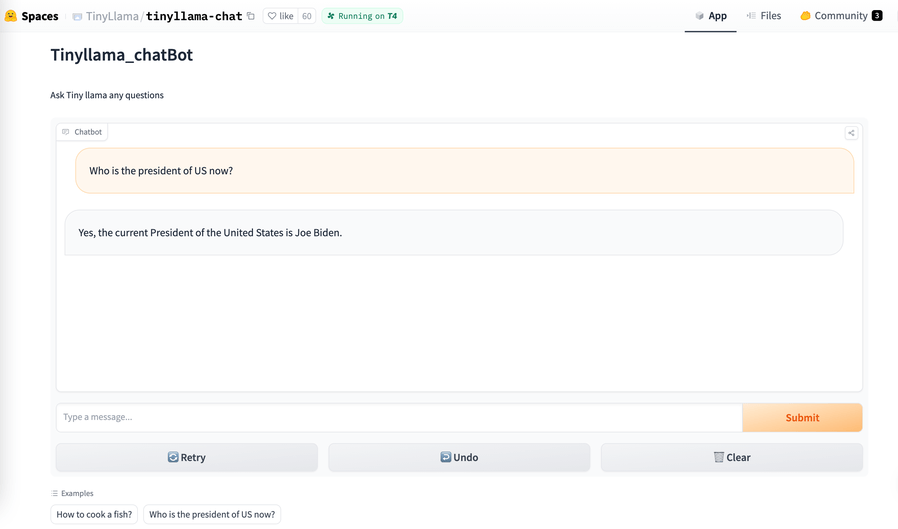
背景介绍 在当前信息量爆炸的时代,语言模型的训练日益变得复杂和困难。为了培训一个高效的语言模型,我们需要大量的计算资源和时间,这对很多人来说是不切实际的。同时,我们也面临着如何在有限的内存和计算资源下运用大型语言模型的挑战,尤其是在边缘设备上。 今天要给大家推荐一个 GitHub 开源项目 jzha…
-
清华、哈工大把大模型压缩到了1bit,把大模型放在手机里跑的愿望就快要实现了!
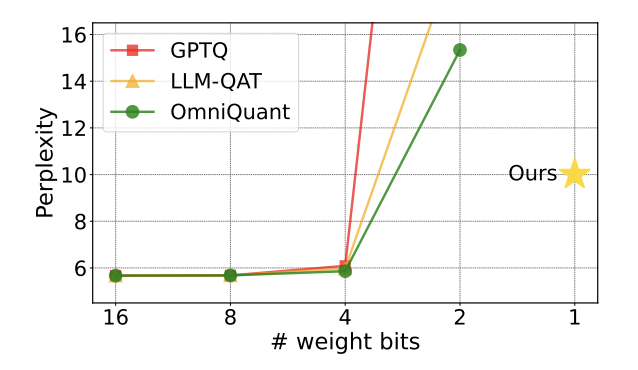

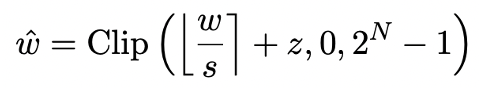
自从大模型火爆出圈以后,人们对压缩大模型的愿望从未消减。这是因为,虽然大模型在很多方面表现出优秀的能力,但高昂的的部署代价极大提升了它的使用门槛。这种代价主要来自于空间占用和计算量。「模型量化」 通过把大模型的参数转化为低位宽的表示,进而节省空间占用。目前,主流方法可以在几乎不损失模型性能的情况下把…
-
复旦等发布AnyGPT:任意模态输入输出,图像、音乐、文本、语音都支持
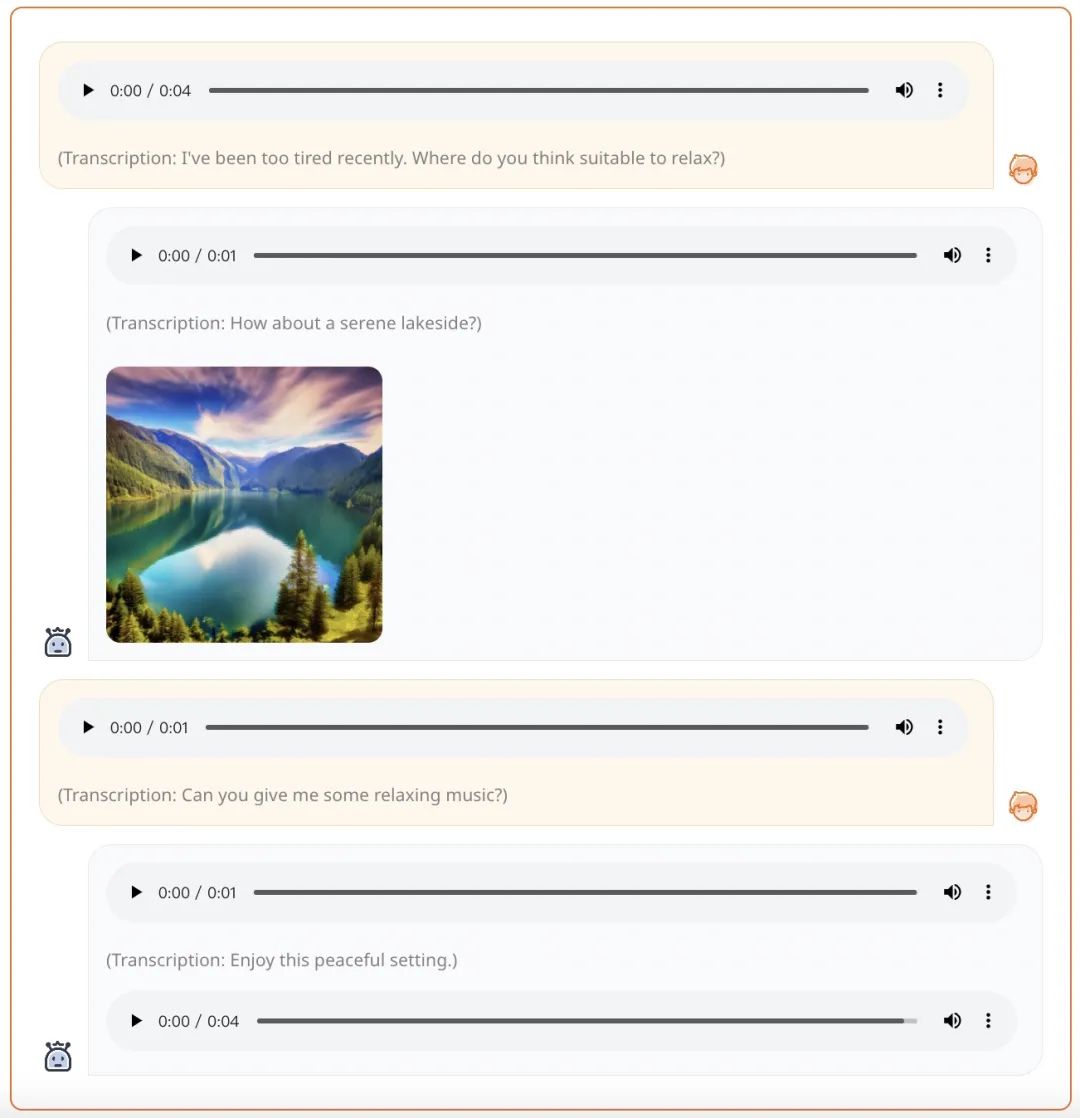
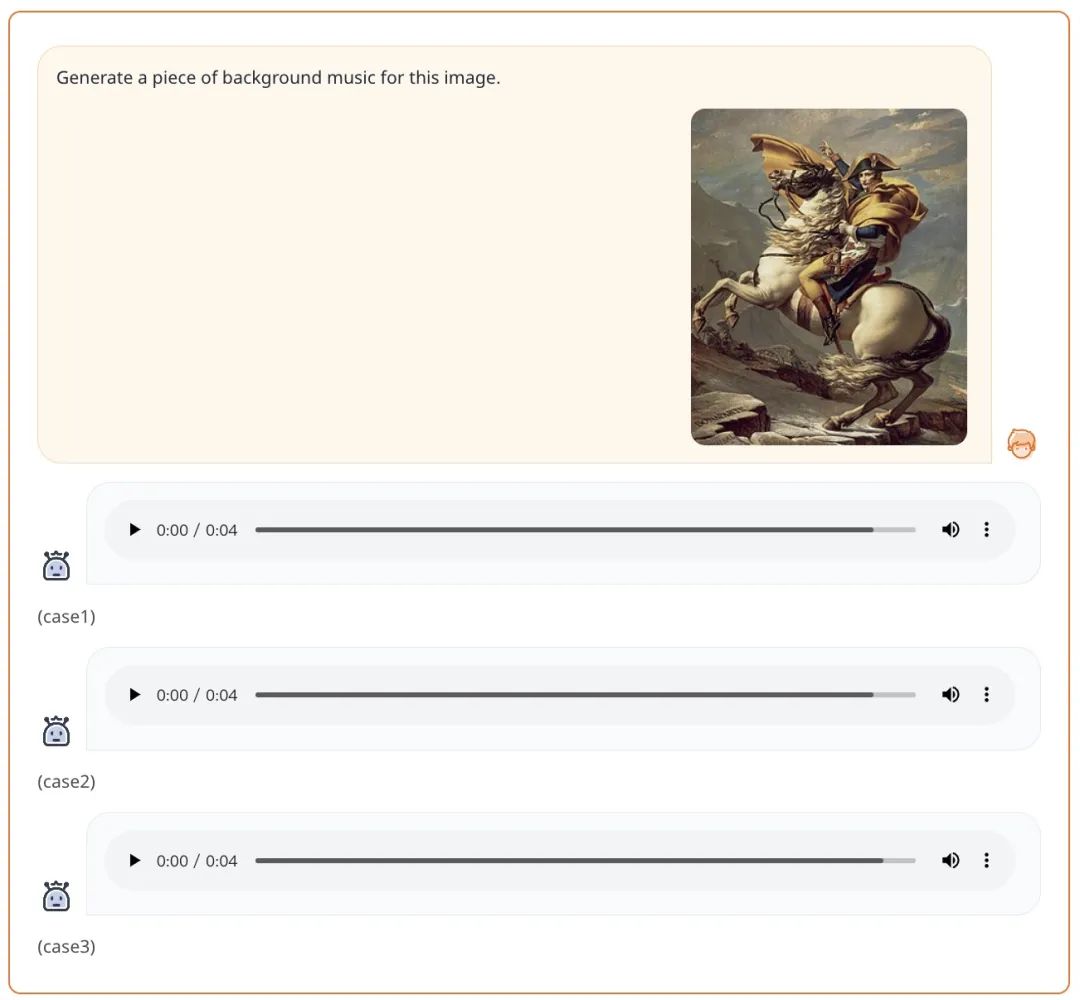

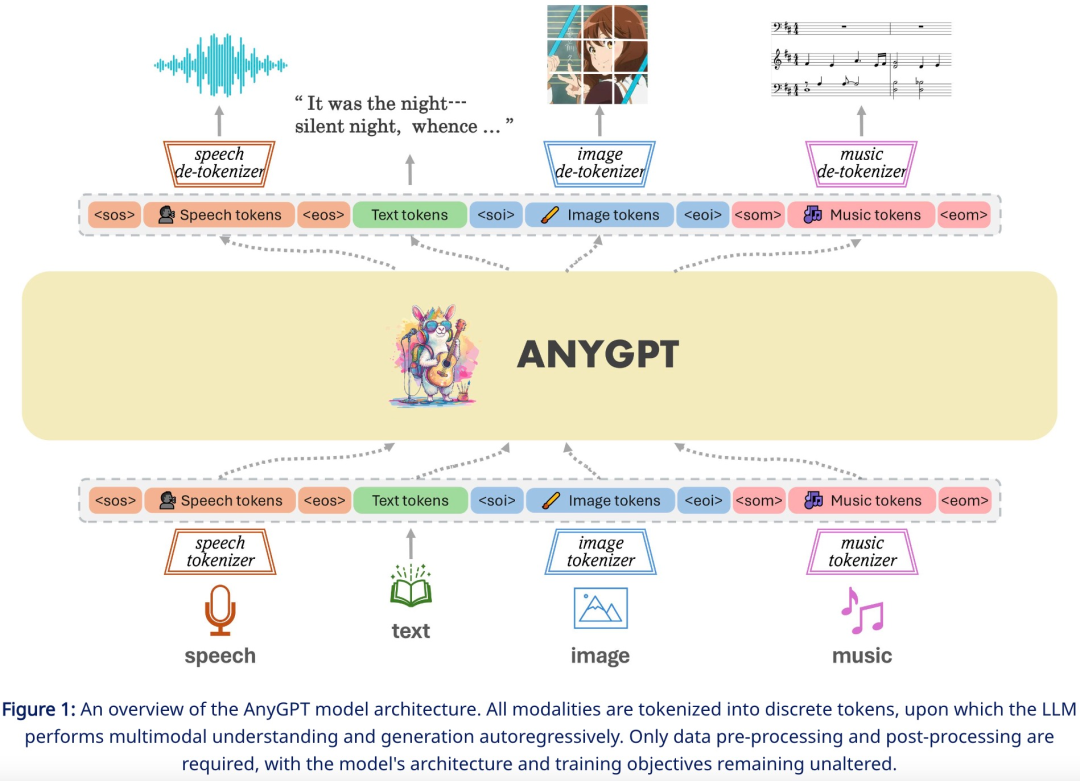
最近,OpenAI 的视频生成模型 Sora 爆火,生成式 AI 模型在多模态方面的能力再次引起广泛关注。 现实世界本质上是多模态的,生物体通过不同的渠道感知和交换信息,包括视觉、语言、声音和触觉。开发多模态系统的一个有望方向是增强 LLM 的多模态感知能力,主要涉及多模态编码器与语言模型的集成,从…
-
室温超导新瓜!LK-99团队展示全新材料完全悬浮及电阻测量结果,报告现场人挤人



☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 火龙果写作 用火龙果,轻松写作,通过校对、改写、扩展等功能实现高质量内容生产。 106 查看详情 以上就是室温超导新瓜!LK-99团队展示全新材料完全悬浮及电阻测量结果,报告现场人挤人的详细内容…
