
模型
-
虽然3nm,但是挤牙膏?A17 Pro跑分出炉:CPU多核仅提升3.6%

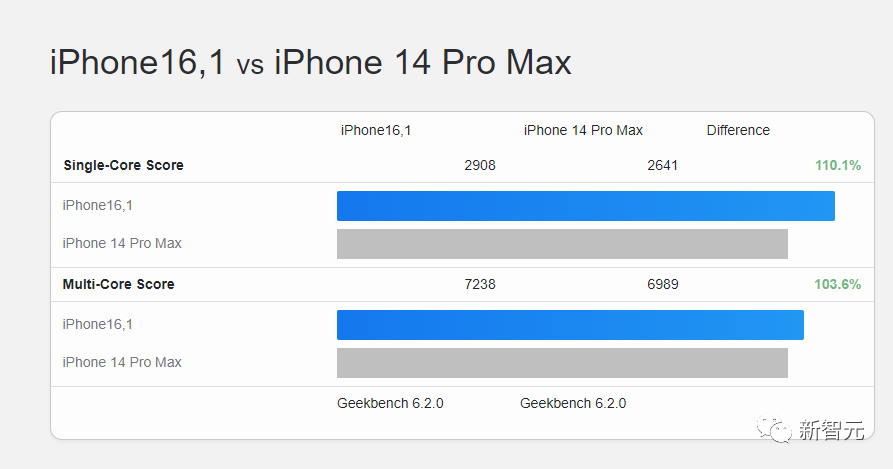
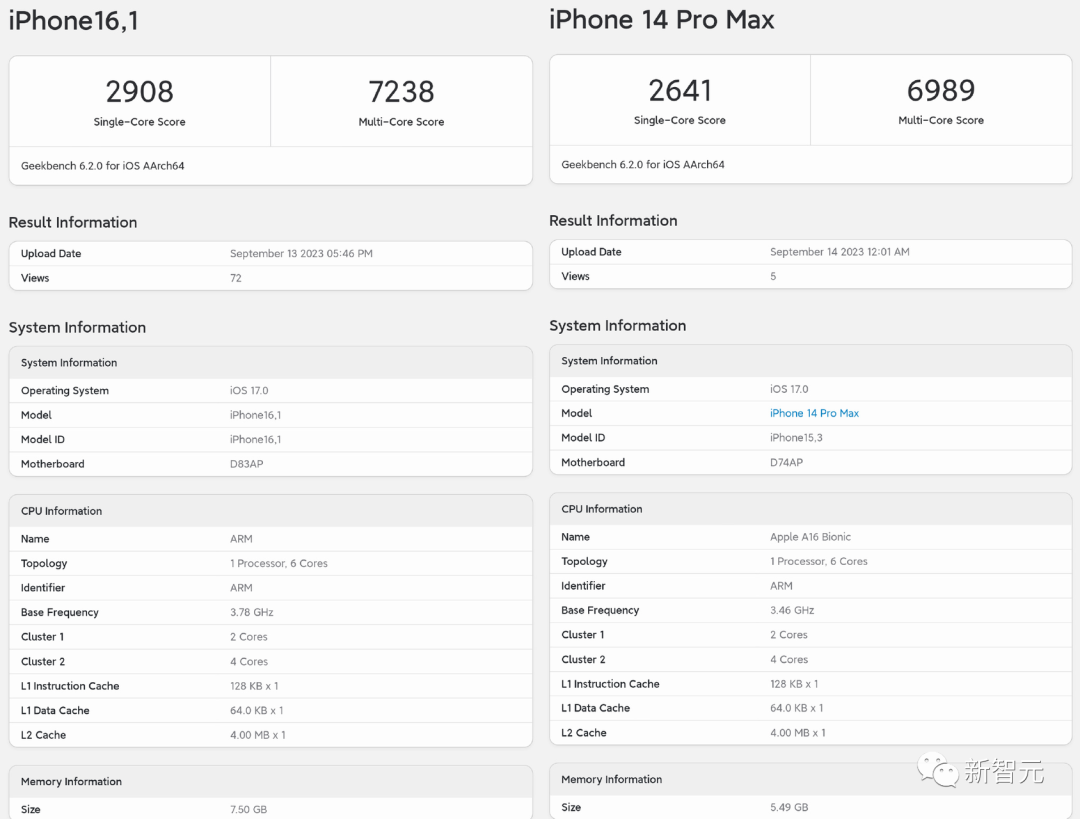

随着苹果A17 Pro昨天正式发布,采用了3纳米工艺,但是性能到底怎么样? ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 多核个位数提升 就苹果A17 Pro在Geekbench 6上的单核性能而言,它比其前身A16 Bionic快10%。…
-
大模型「上车」关键一步:全球首个语言+自动驾驶开源数据集来了
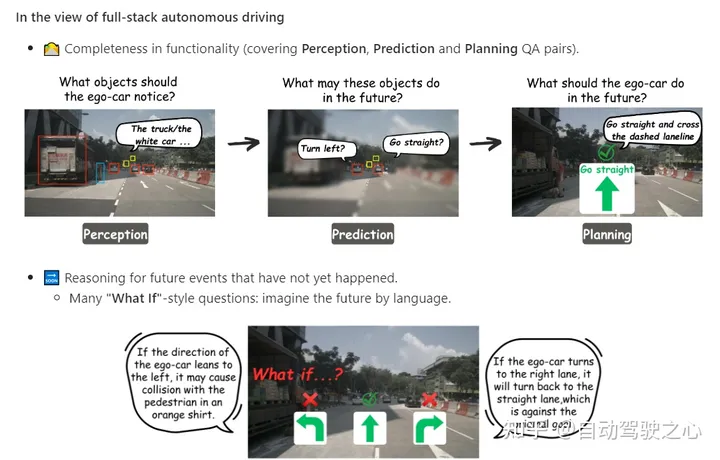

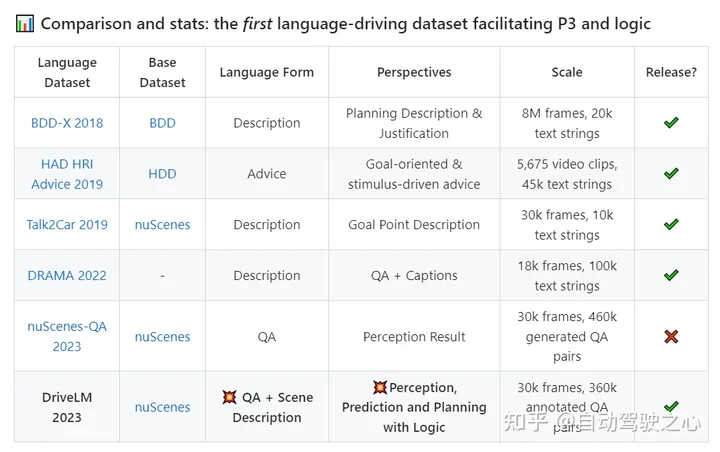
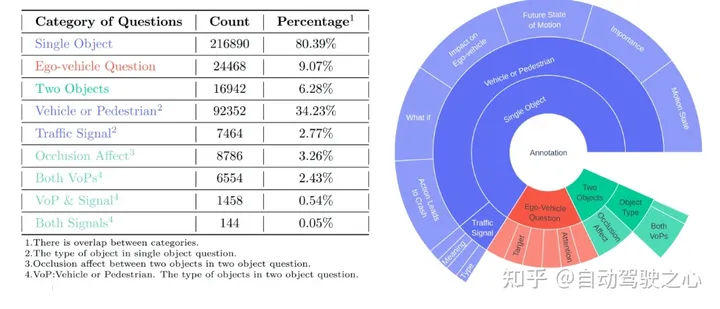
DriveLM是一个基于语言的驱动项目,它包含一个数据集和一个模型。通过DriveLM,我们介绍了自动驾驶(AD)中大型语言模型的推理能力,以做出决策并确保可解释的规划。 在DriveLM的数据集中,我们将人工书写的推理逻辑作为连接,以促进感知、预测和规划(P3)。在我们的模型中,我们提出了一个具备…
-
微软超强小模型引发热议:探讨教科书级数据的巨大作用




随着大模型掀起新一轮 AI 热潮,人们开始思考:大模型的强大能力来源于什么? 当前,大模型一直在由不断增加的「大数据」来推动。「大模型 + 大数据」似乎已经成为构建模型的标准范式。但随着模型规模和数据量的不断增长,算力的需求会迅速膨胀。一些研究者尝试探索新思路。重写后的内容:目前,大型模型一直在依靠…
-
训练大模型缺少高质量数据?我们找到了一种新的解决方案
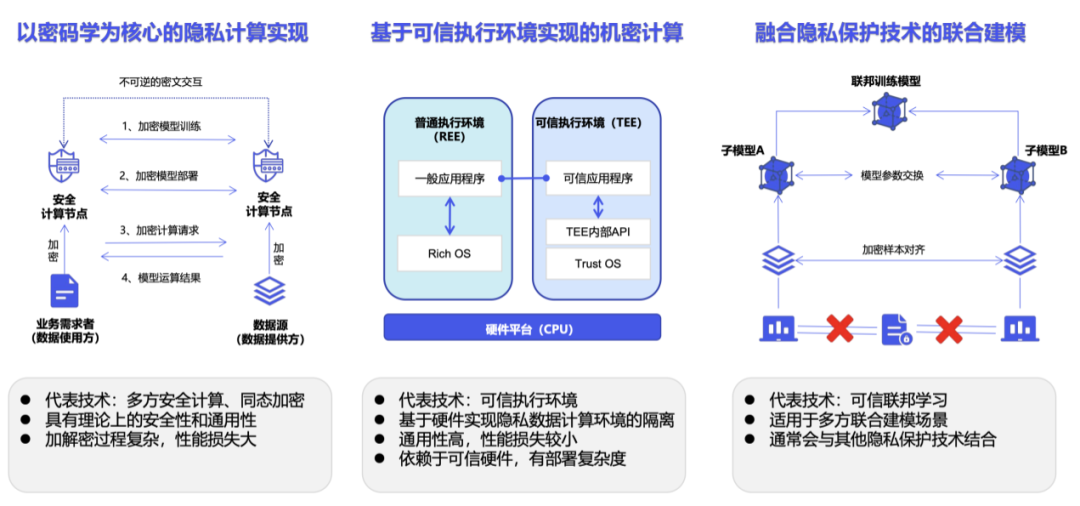
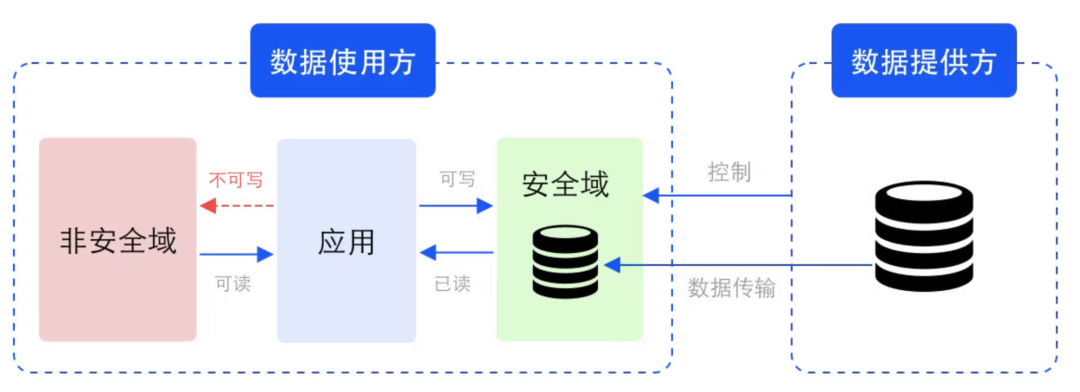
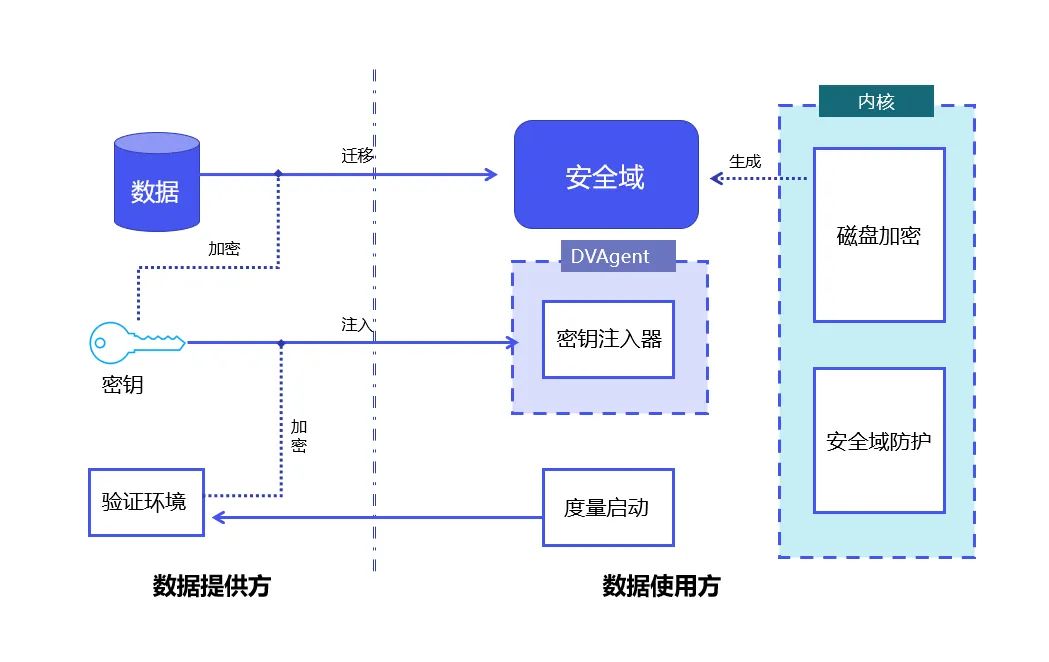

数据,作为决定机器学习模型性能的三大要素之一,正在成为制约大模型发展的瓶颈。正所谓「Garbage in, garbage out」[1],无论你的算法多么优秀,你的计算资源多么强大,模型的质量都直接取决于你用来训练模型的数据。 随着各种开源大模型的涌现,数据的重要性进一步凸显,尤其是高质量的行业数…
-
不用4个H100!340亿参数Code Llama在Mac可跑,每秒20个token,代码生成最拿手
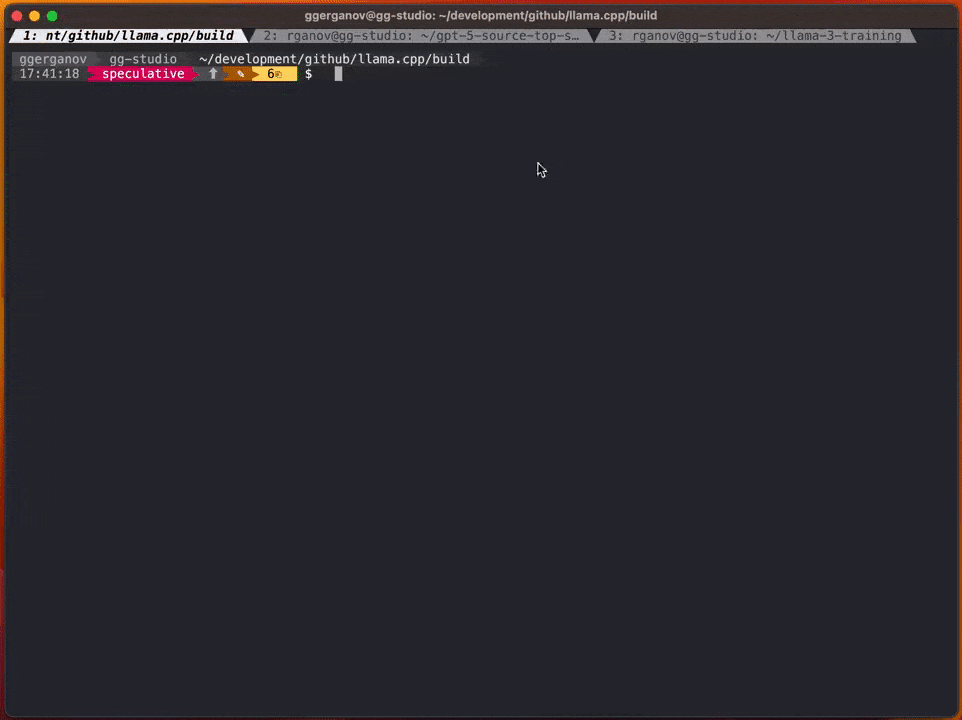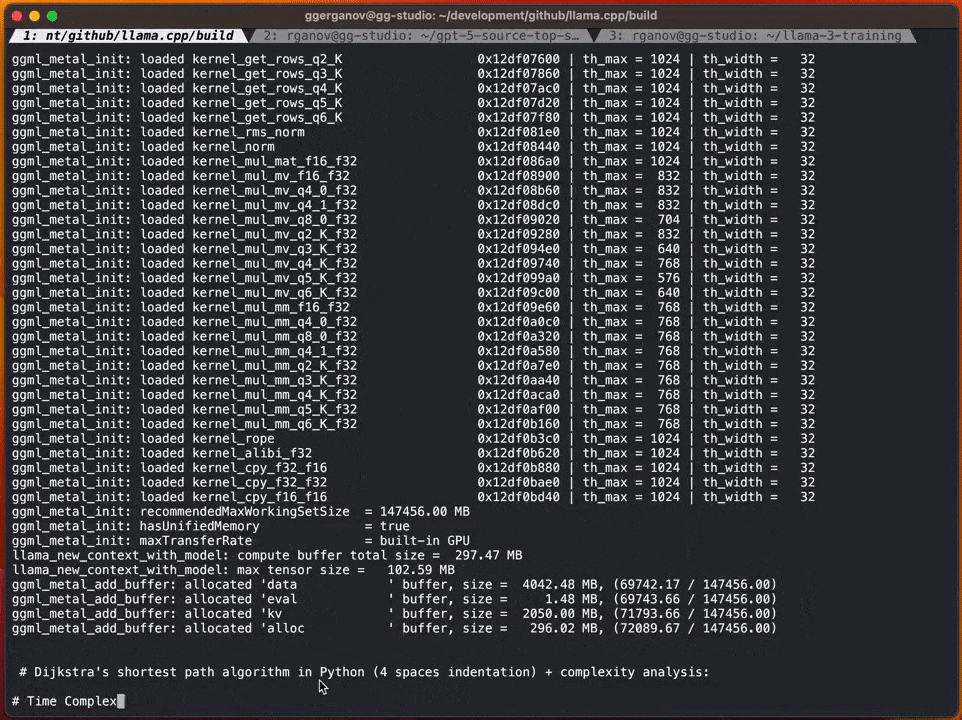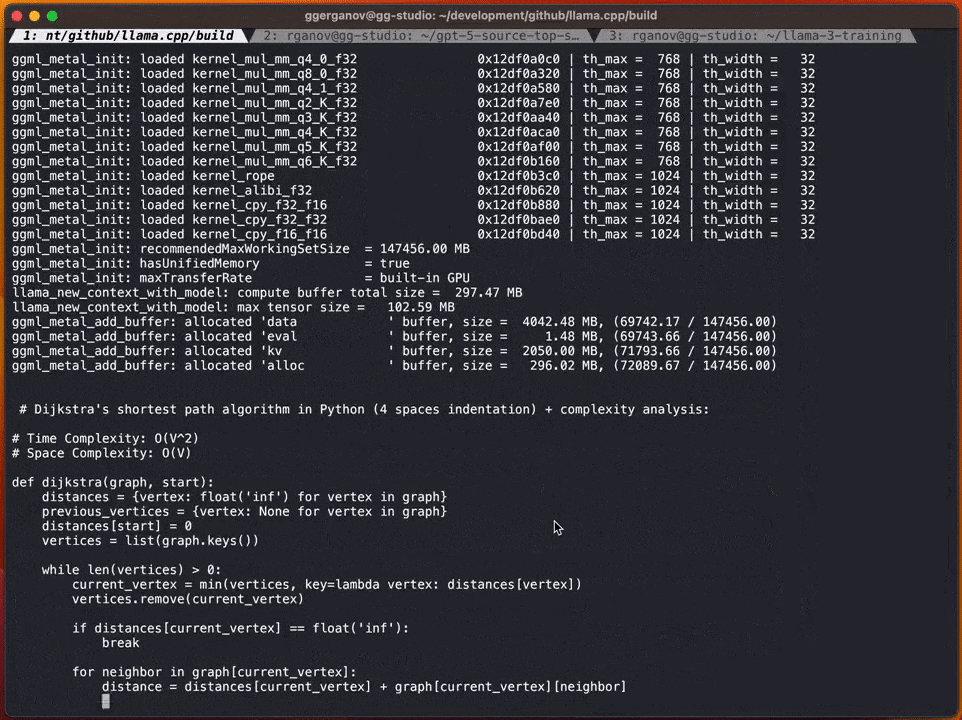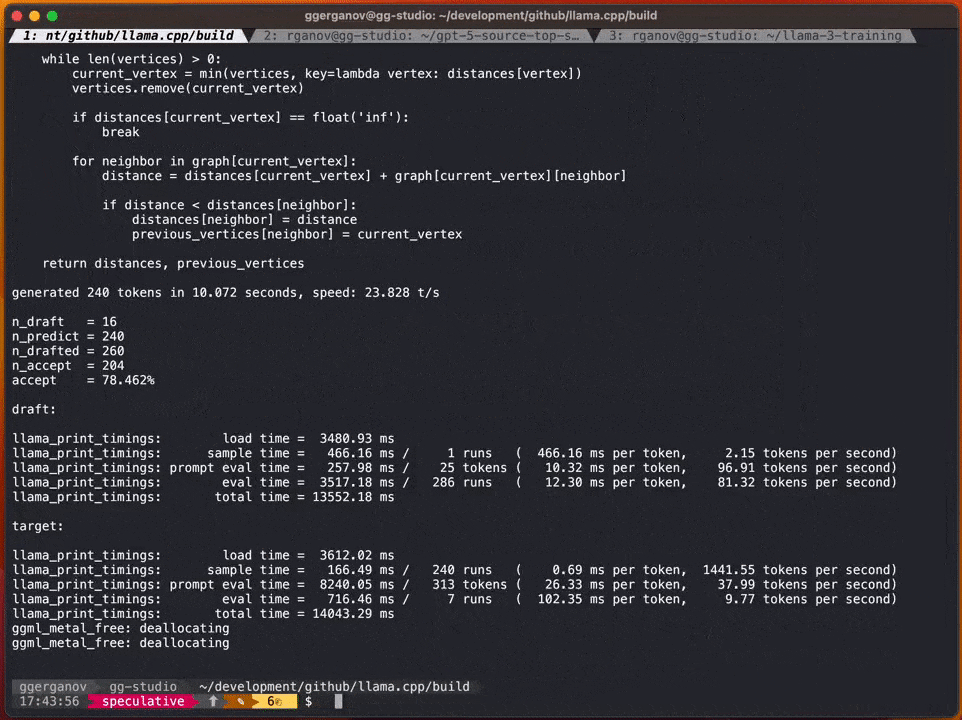



开源社区的一位开发者Georgi Gerganov发现,自己可以在M2 Ultra上运行全F16精度的34B Code Llama模型,而且推理速度超过了20 token/s。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ M2 Ultra…
-
视觉Transformer中ReLU替代softmax,DeepMind新招让成本速降

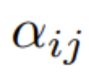
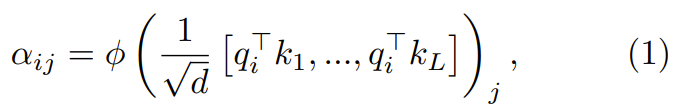
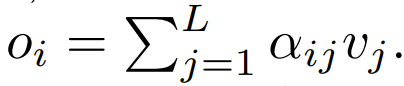
Transformer 架构已经在现代机器学习领域得到了广泛的应用。重点是要集中注意力是 transformer 的一大核心组件,其中包含了一个 softmax,作用是产生 token 的一个概率分布。softmax 有较高的成本,因为其会执行指数计算和对序列长度求和,这会使得并行化难以执行。 Go…
-
马斯克公布消息:Neuralink首次进行人体试验,或将帮助渐冻症患者实现「秒变霍金」的愿望
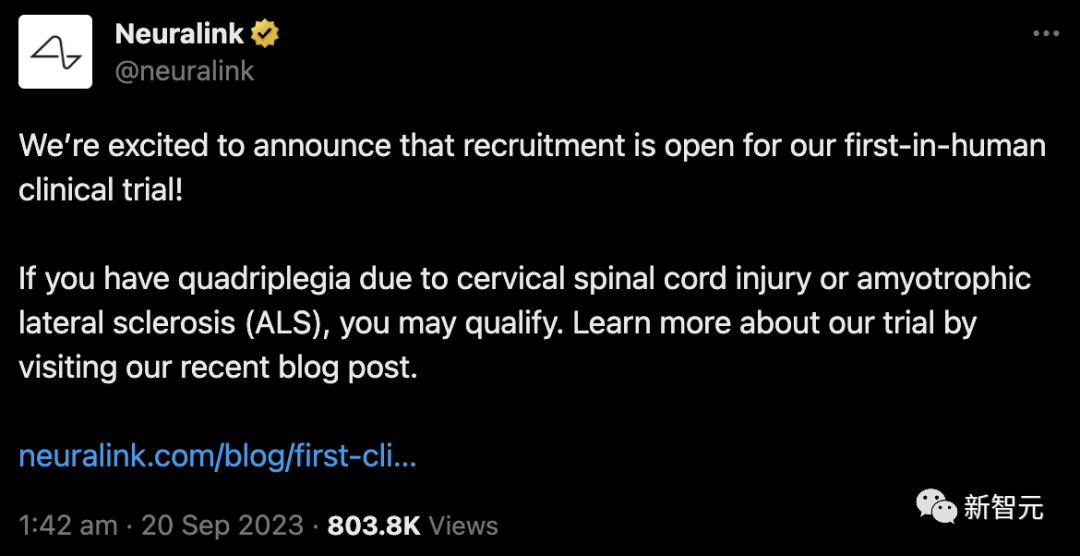


马斯克宇宙中开发「脑机接口」的公司Neuralink今天宣布:正式开始招募人体临床试验对象! ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 根据Neuralink官方博客的说法,他们已经通过审查委员会的审查,并且医院选址也已经获得批准 Ne…
-
4 秒看完 2 小时电影!阿里发布通用多模态大模型 mPLUG-Owl3

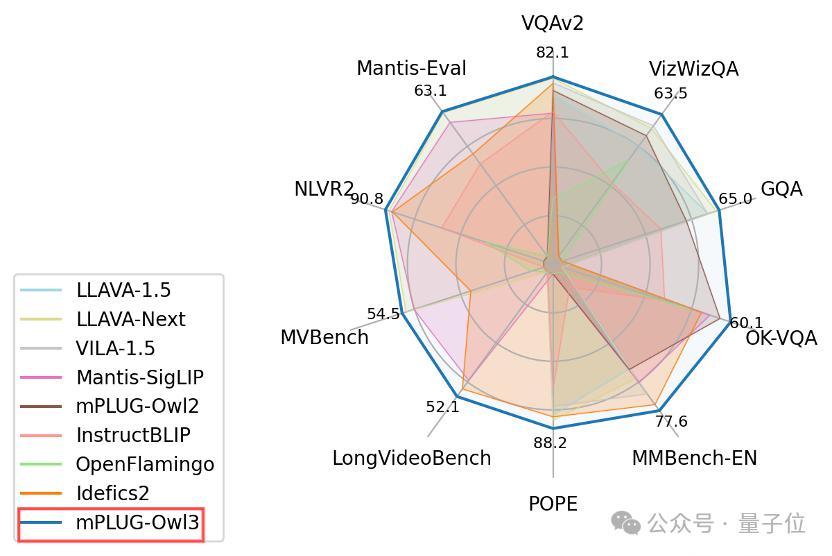


4 秒看完 2 小时电影,阿里团队新成果正式亮相—— 推出通用多模态大模型 mPLUG-Owl3,专门用来理解多图、长视频。 具体来说,以 LLaVA-Next-Interleave 为基准,mPLUG-Owl3 将模型的First Token Latency 缩小了 6 倍,且单张 A100 能建…
-
Open Interpreter:一款让大型语言模型在本地执行代码的开源工具
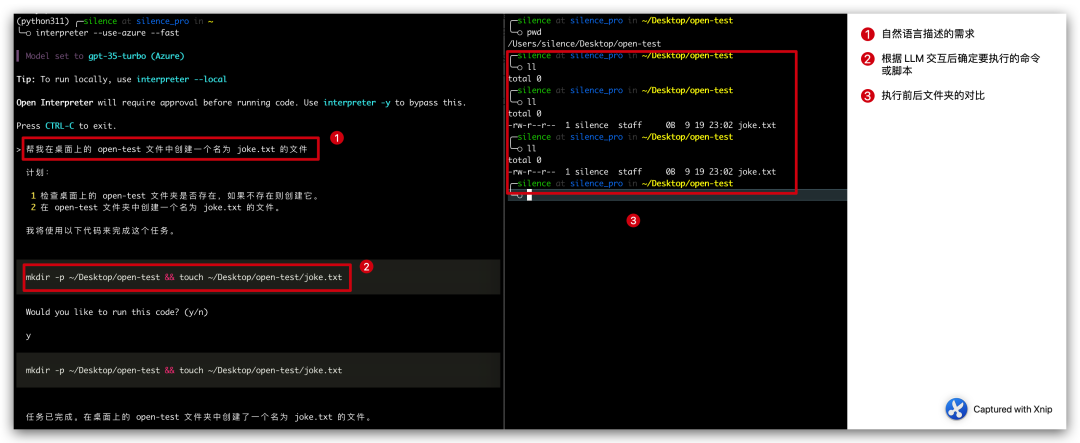

最近在逛 github 的时候发现了一款神器,叫做 open interpreter,主要是用来实现在本地和大语言模型进行交互的,通过大语言模型将自然语言转换为脚本代码,然后在本地执行从而实现目标。 简而言之,如果你想在桌面上创建一个名为joke.txt的文件,你不需要手动创建,而是可以通过自然语言…
-
机器学习模型的过拟合问题


☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 机器学习模型的过拟合问题及其解决方法 在机器学习领域中,模型的过拟合是一个常见且具有挑战性的问题。当一个模型在训练集上表现优秀,但在测试集上表现较差时,就表明该模型出现了过拟合现象。本文将介绍过…
