
模型
-
GPT-4 做「世界模型」,让LLM从「错题」中学习,推理能力显著提升




近期来,大型语言模型在各种自然语言处理任务中取得了显著的突破,特别是在需要进行复杂思维链(CoT)推理的数学问题上 比如在 GSM8K、MATH 这样的高难度数学任务的数据集中,包括 GPT-4 和 PaLM-2 在内的专有模型已取得显著成果。在这方面,开源大模型还有相当的提升空间。为了进一步提高开…
-
OpenAI的Whisper蒸馏后,语音识别速度大幅提升:两天内star量突破千

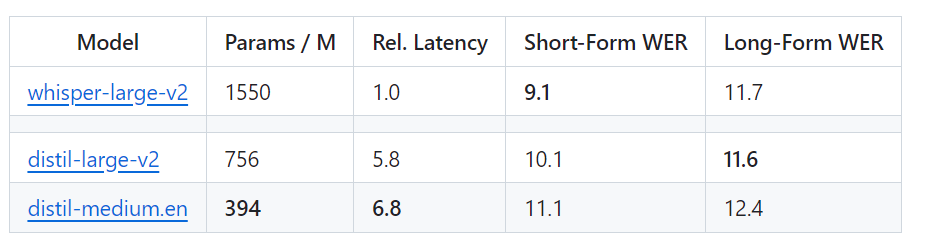
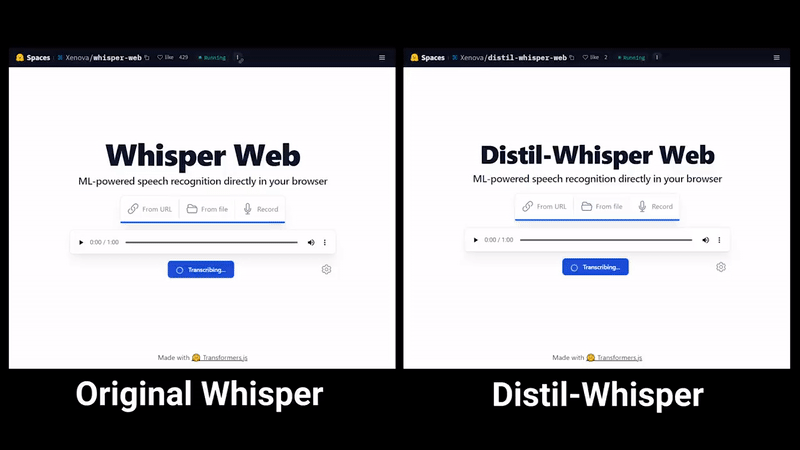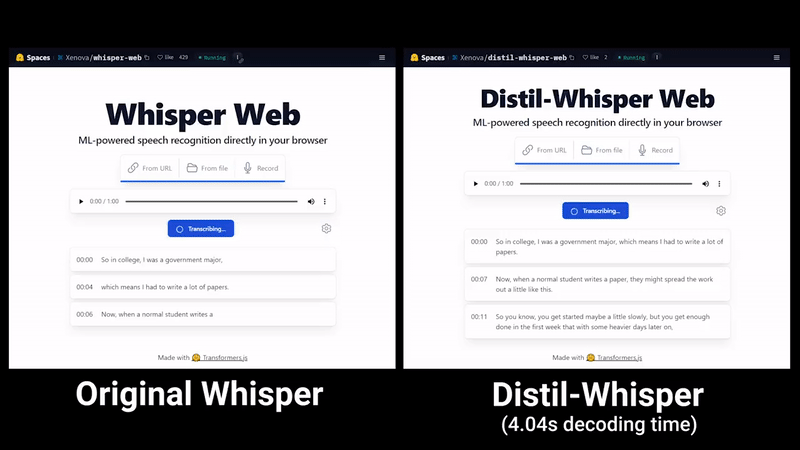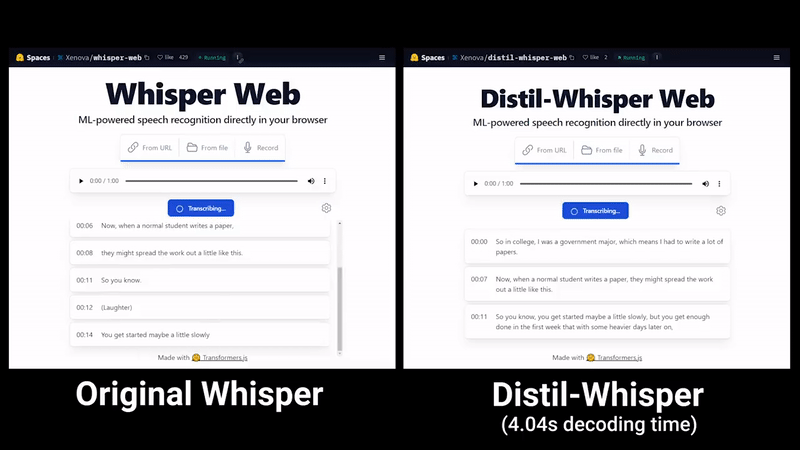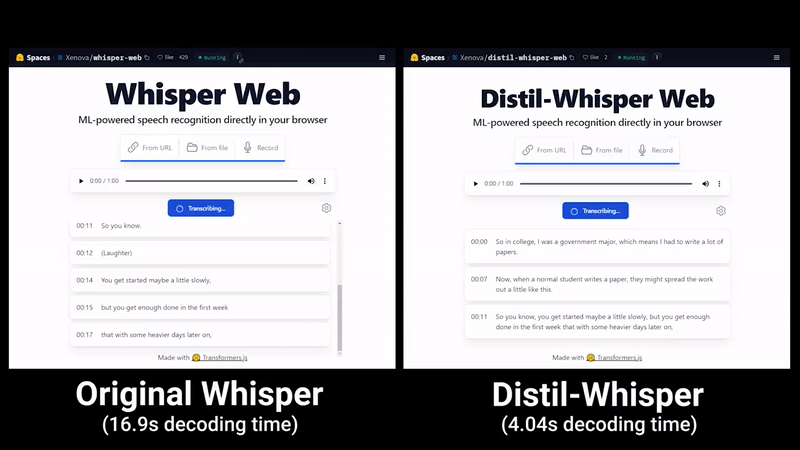
最近,「霉霉大秀中文」的视频在各大社交媒体上迅速走红,之后又出现了类似的「郭德纲大秀英语」等视频。这些视频中的许多都是由一款名为「HeyGen」的人工智能应用制作的 不过,从 HeyGen 现在的火爆程度来看,想用它制作类似视频可能要排很久。好在,这并不是唯一的制作方法。懂技术的小伙伴也可以寻找其他…
-
国内最大开源模型发布,无条件免费商用!参数650亿,基于2.6万亿token训练
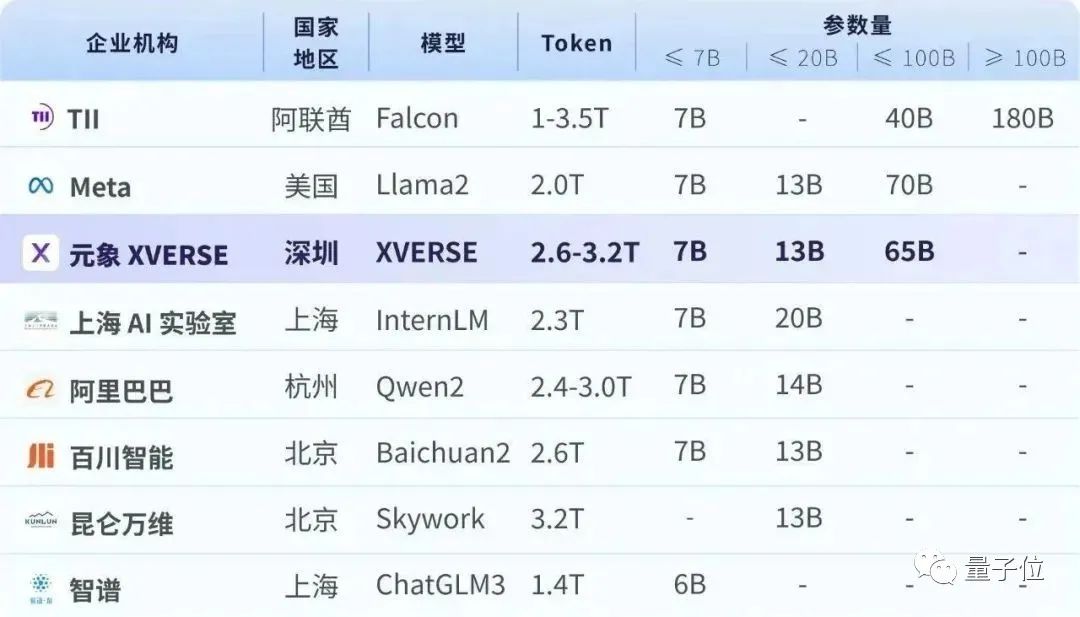

国内规模最大的开源大模型来了: 参数650亿、基于2.6-3.2万亿token训练。 排名仅次于“猎鹰”和“羊驼”,性能媲美GPT3.5,现在就能无条件免费商用。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 它就是来自深圳元象公司的XVE…
-
让大型AI模型自主提问:GPT-4打破与人类对话的障碍,展现更高水平的表现



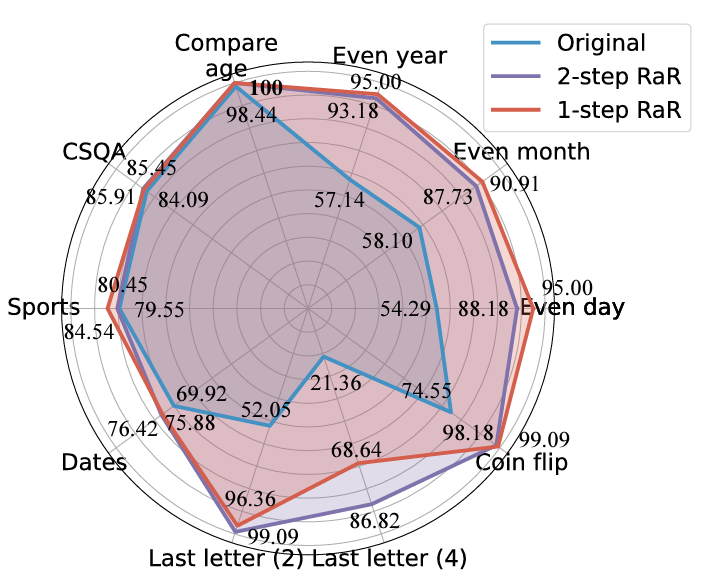
在最新的人工智能领域动态中,人工生成的提示(prompt)质量对大语言模型(LLM)的响应精度有着决定性影响。OpenAI 提出的建议指出,精确、详细且具体的问题对于这些大语言模型的表现至关重要。然而,普通用户是否能够确保他们的问题对于 LLM 来说足够清晰明了? 需要重新写的内容是:值得注意的是,…
-
谷歌大模型研究引发激烈争议:训练数据之外的泛化能力受到质疑,网友表示AGI奇点或被推迟
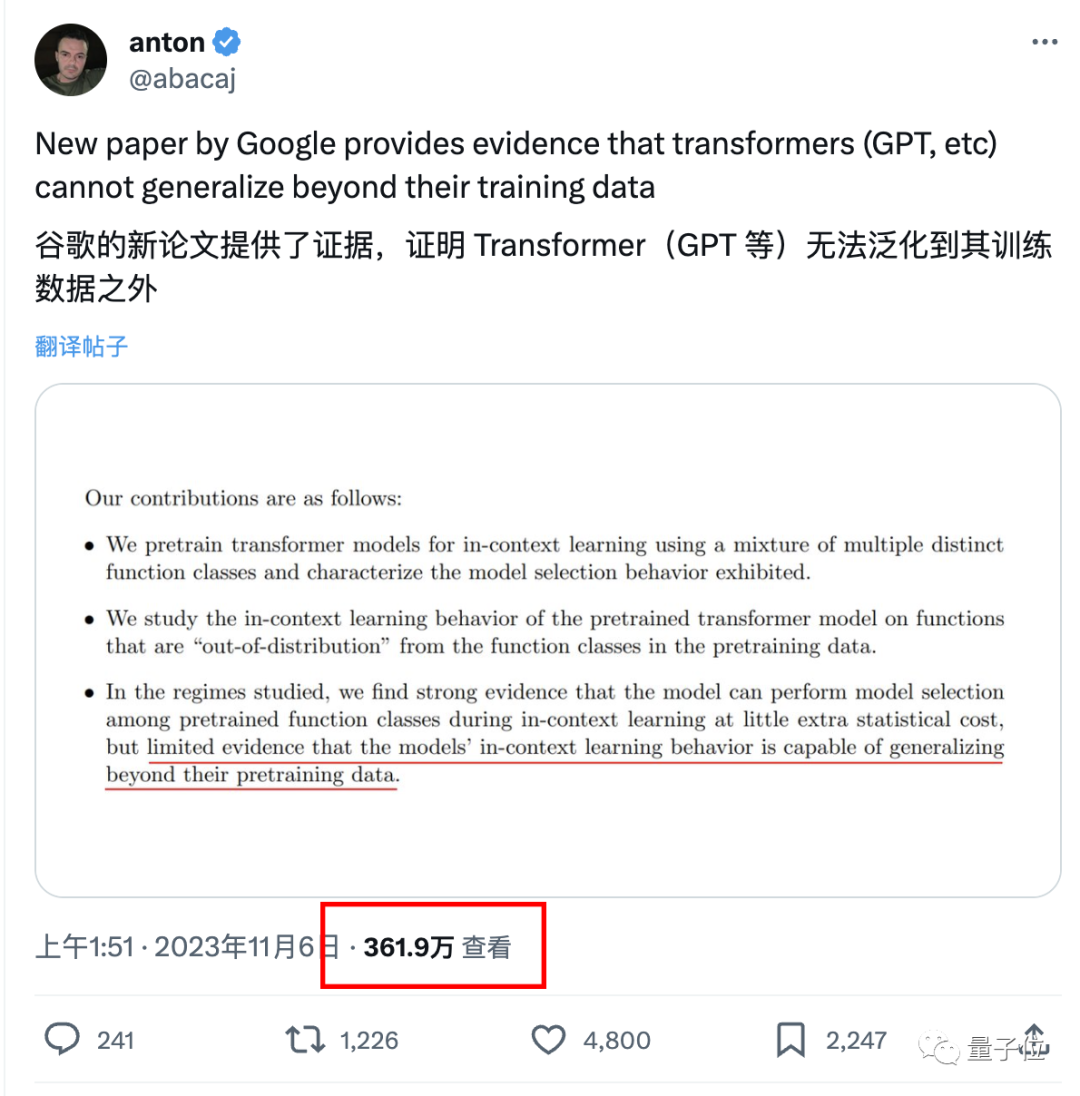

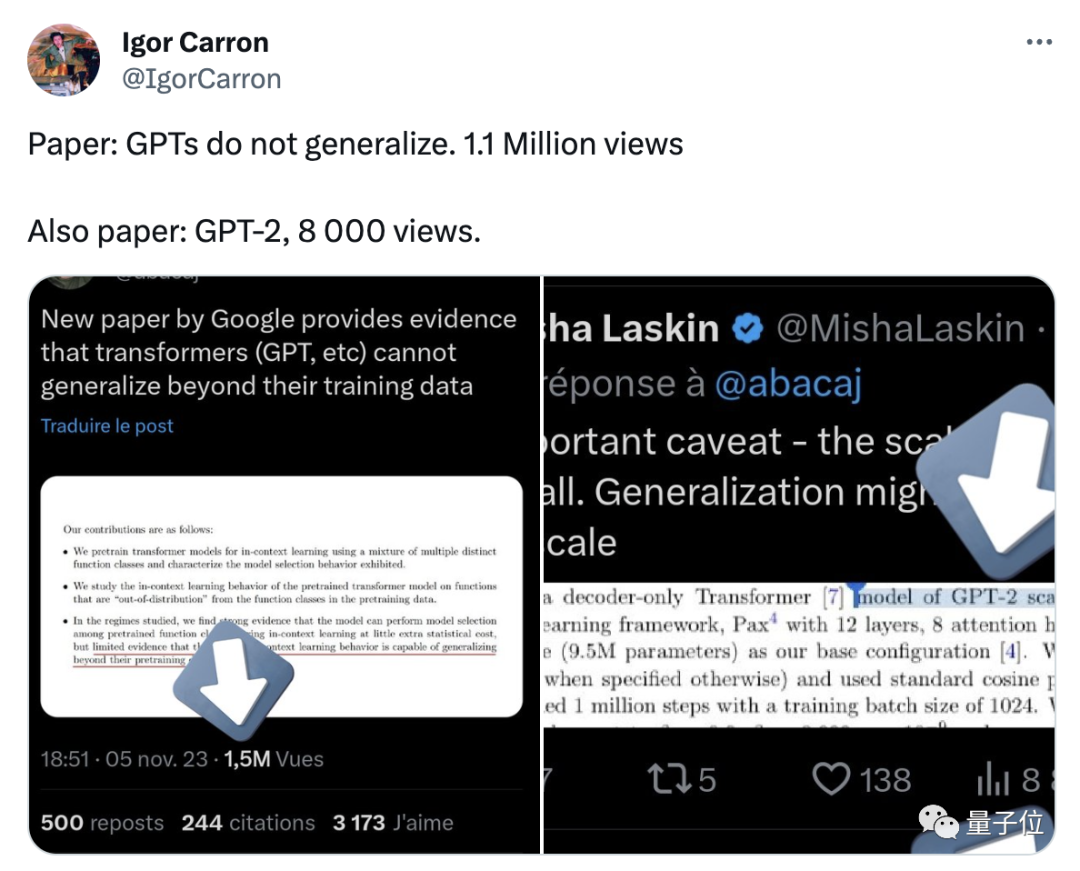
谷歌deepmind最近发现的一项新结果在transformer领域引起了广泛争议: 它的泛化能力,无法扩展到训练数据以外的内容。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 目前这一结论还没有进一步得到验证,但已经惊动了一众大佬,比如K…
-
全新近似注意力机制HyperAttention:对长上下文友好、LLM推理提速50%
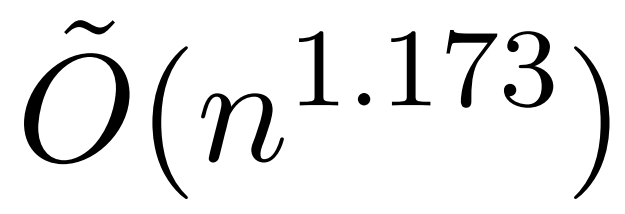
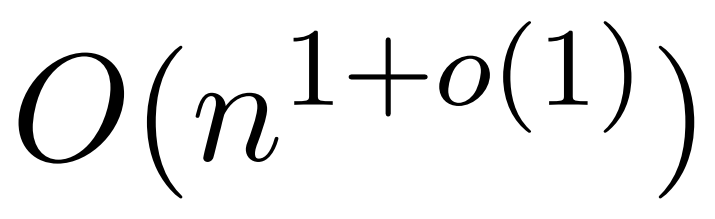


Transformer 已经在自然语言处理、计算机视觉和时间序列预测等领域的各种学习任务中取得成功。虽然取得了成功,但是这些模型仍然面临着严重的可扩展性限制。原因是对注意力层的精确计算导致了二次(在序列长度上)的运行时间和内存复杂性。这给将Transformer模型扩展到更长的上下文长度带来了根本性…
-
UC伯克利谷歌革新LLM,实现终结扩散模型并用于IGN单步生成逼真图像,美剧成为灵感来源


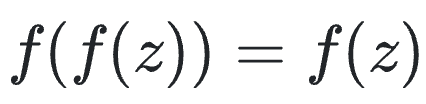
已经红遍半边天的%ignore_a_1%模型,将被淘汰了? 当前,生成式AI模型,比如GAN、扩散模型或一致性模型,通过将输入映射到对应目标数据分布的输出,来生成图像需要进行改写的内容是: 通常情况下,这种模型需要学习很多真实的图片,然后才能尽量保证生成图片的真实特征需要进行改写的内容是: 最近,来…
-
大模型幻觉率排行:GPT-4 3%最低,谷歌Palm竟然高达27.2%
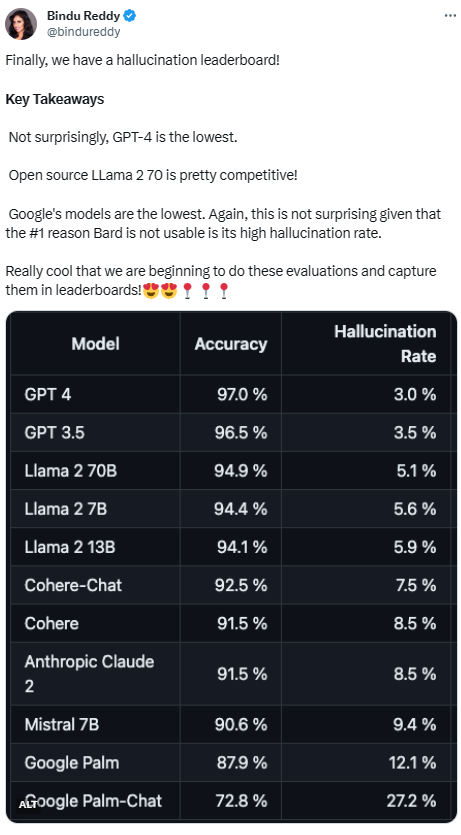
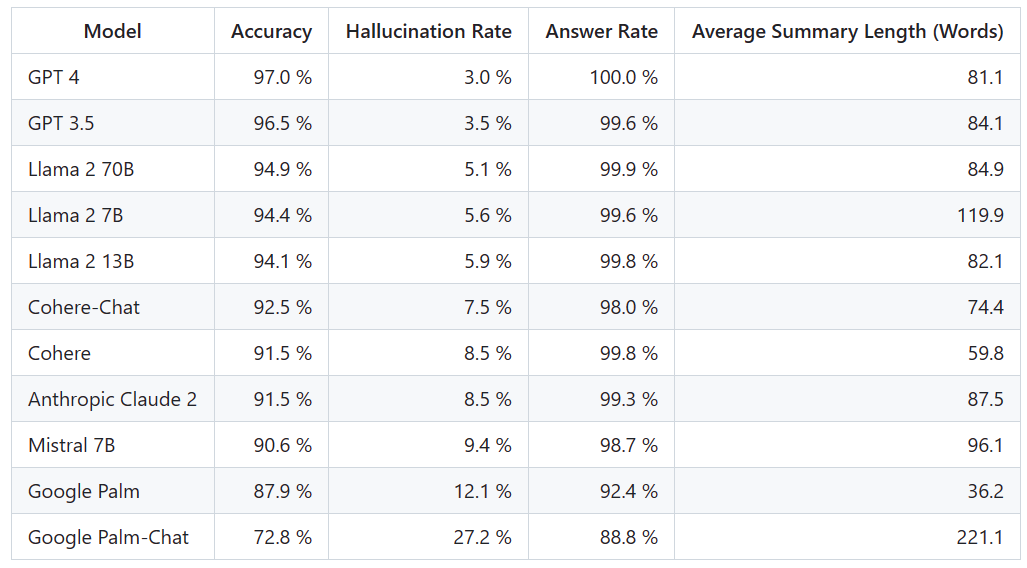

人工智能发展进步神速,但问题频出。OpenAI 新出的 GPT 视觉 API 前脚让人感叹效果极好,后脚又因幻觉问题令人不禁吐槽。 幻觉一直是大模型的致命缺陷。由于数据集庞杂,其中难免会有过时、错误的信息,导致输出质量面临着严峻的考验。过多重复的信息还会使大模型形成偏见,这也是幻觉的一种。但是幻觉并…
-
基于LLaMA却改张量名,李开复公司大模型引争议,官方回应来了
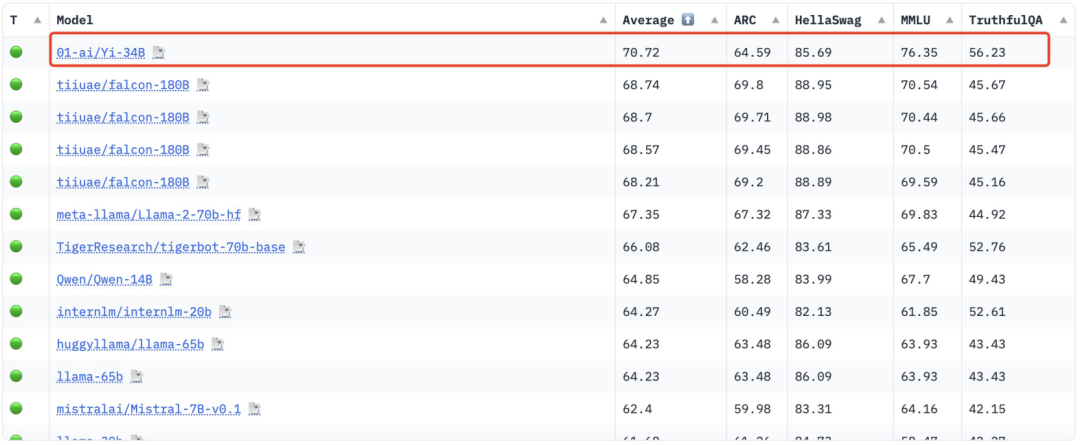
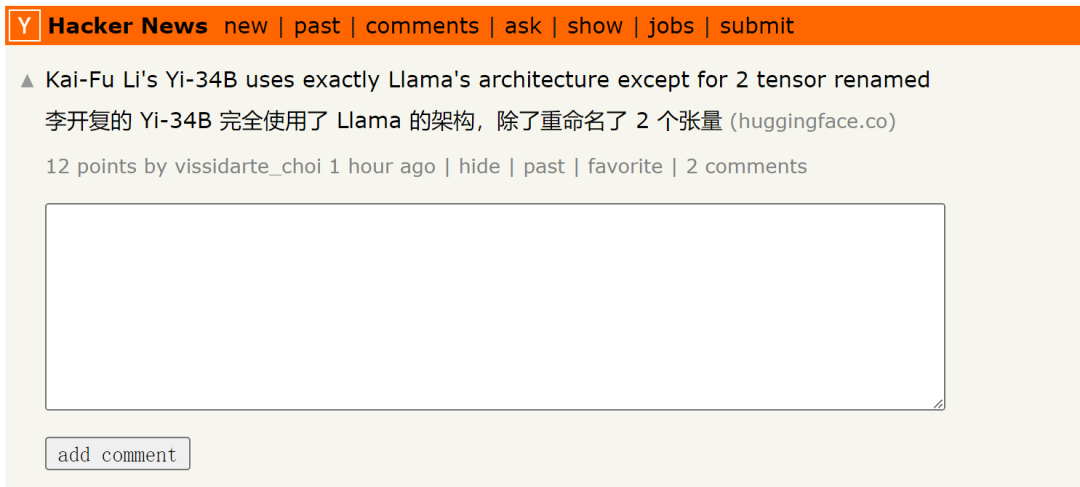
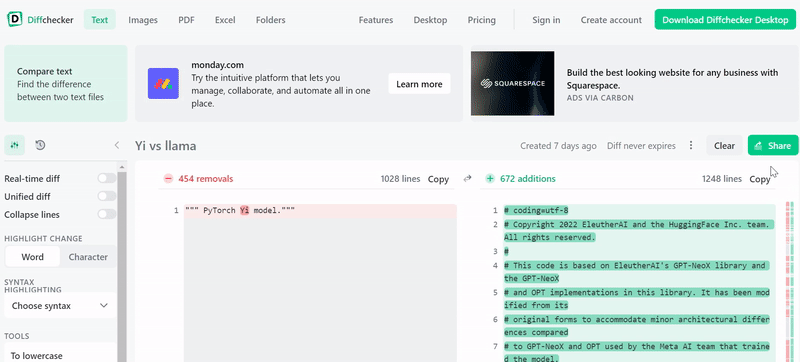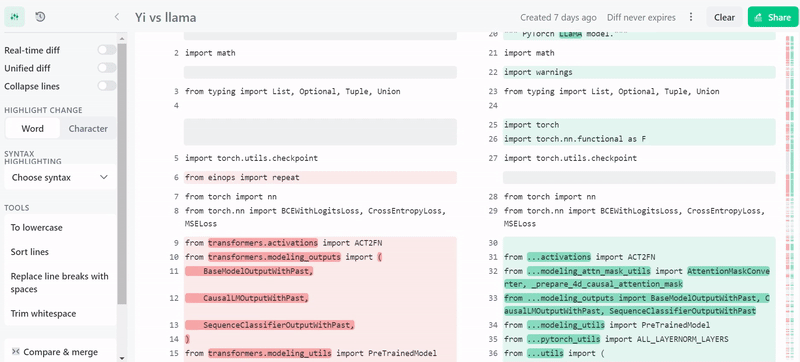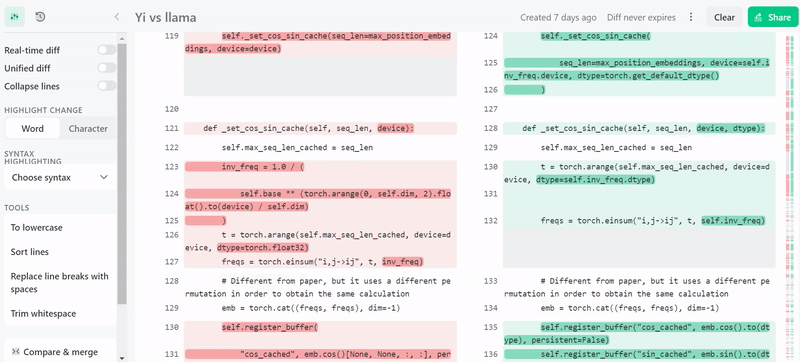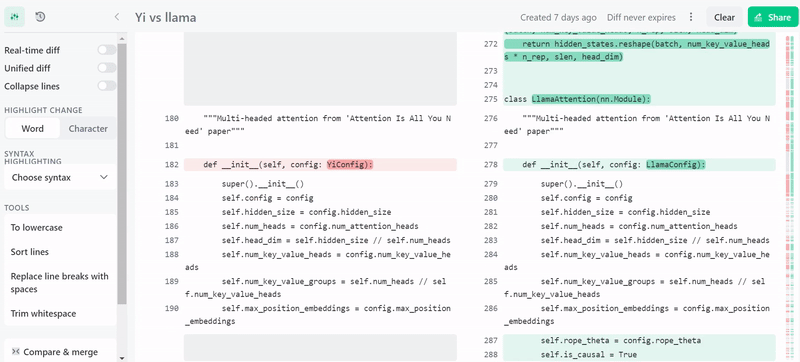

前段时间,开源大模型领域迎来了一个新的模型 —— 上下文窗口大小突破 200k,能一次处理 40 万汉字的「Yi」。 创新工场董事长兼 CEO 李开复创立了大模型公司「零一万物」,并且构建了这个大模型,其中包括了 Yi-6B 和 Yi-34B 两个版本 根据 Hugging Face 英文开源社区平…
-
MySQL 中 QueryCache 的锁模型
有同学在问 MySQL中 QueryCache(QC)的锁是 全局锁还是 表锁。这里简要说明一下。 1、 QC基本概念 这个是实现在MySQL层(非引擎层)的一个内存结构,基本规则是将满足一定条件的查询结果缓存在内存中,若同样的查询再执行第二次,而且缓存没有失效,则可以直接返 有同学在问 MySQL…
