
模型
-
首个支持4-bit浮点量化的LLM来了,解决LLaMA、BERT等的部署难题

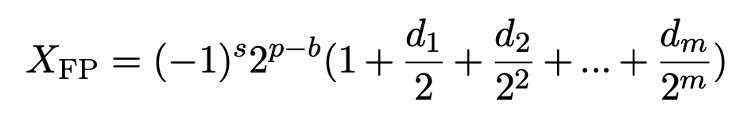
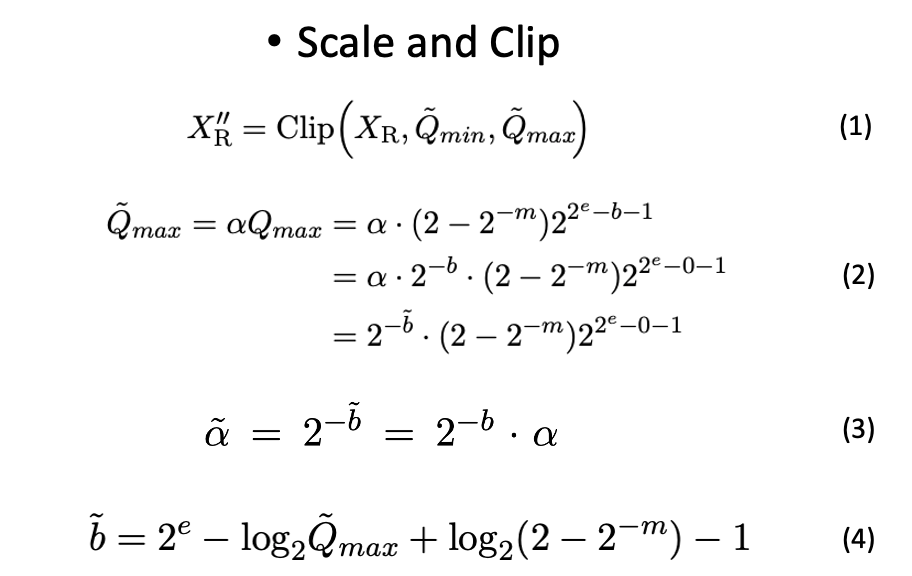
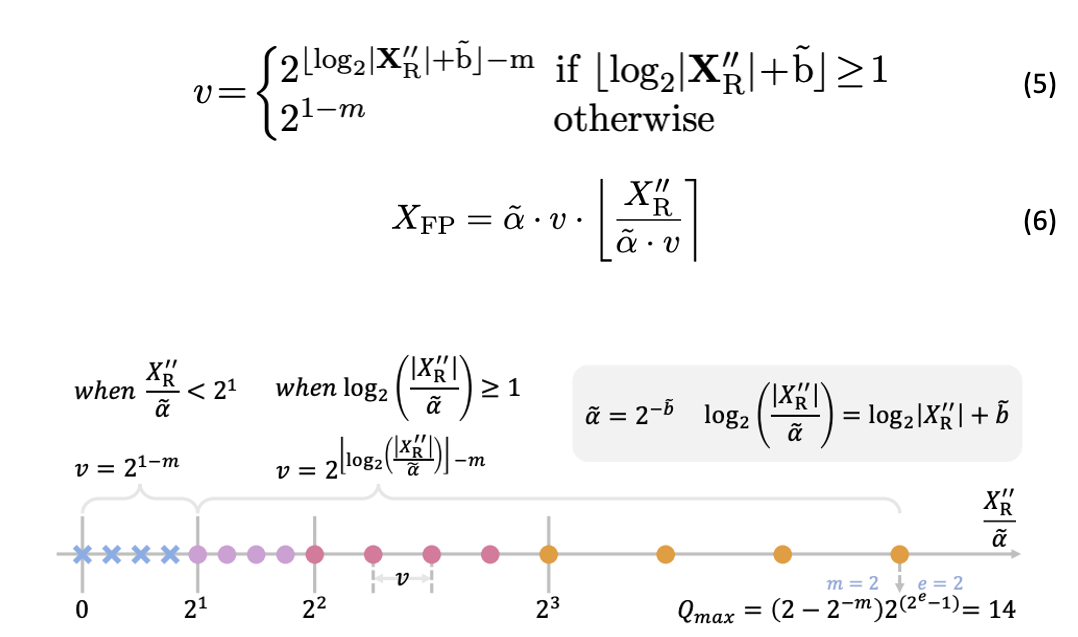
大语言模型 (LLM) 压缩一直备受关注,后训练量化(Post-training Quantization) 是其中一种常用算法,但是现有 PTQ 方法大多数都是 integer 量化,且当比特数低于 8 时,量化后模型的准确率会下降非常多。想较于 Integer (INT) 量化,Floating…
-
从 DeiT-B 到 DeiT-S,块结构化剪枝在深度 ViTs上 的应用 !

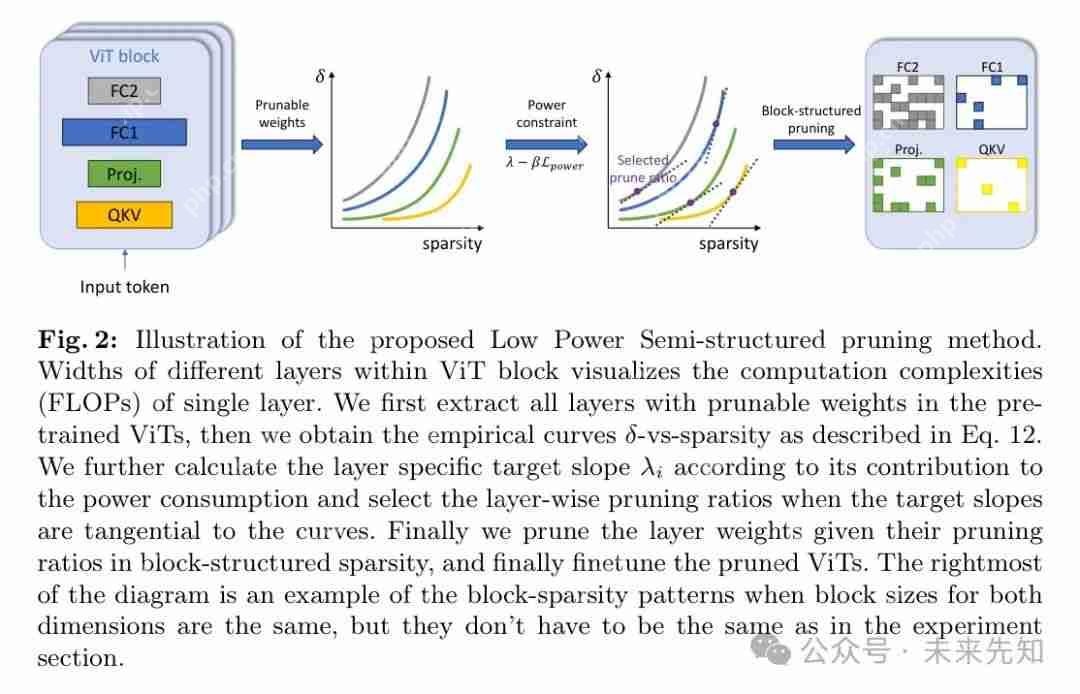

1 Introductions 近期,视觉 transformer (vits)成为一项新兴研究,极大地挑战了占主导地位的卷积神经网络(cnns),在诸如分类[9, 13, 18, 22, 44]、目标检测[1, 3, 61]、语义分割[5, 35]等各种图像分析和理解任务上表现出与cnns相当甚至…
-
「无需配对数据」就能学习!浙大等提出连接多模态对比表征C-MCR

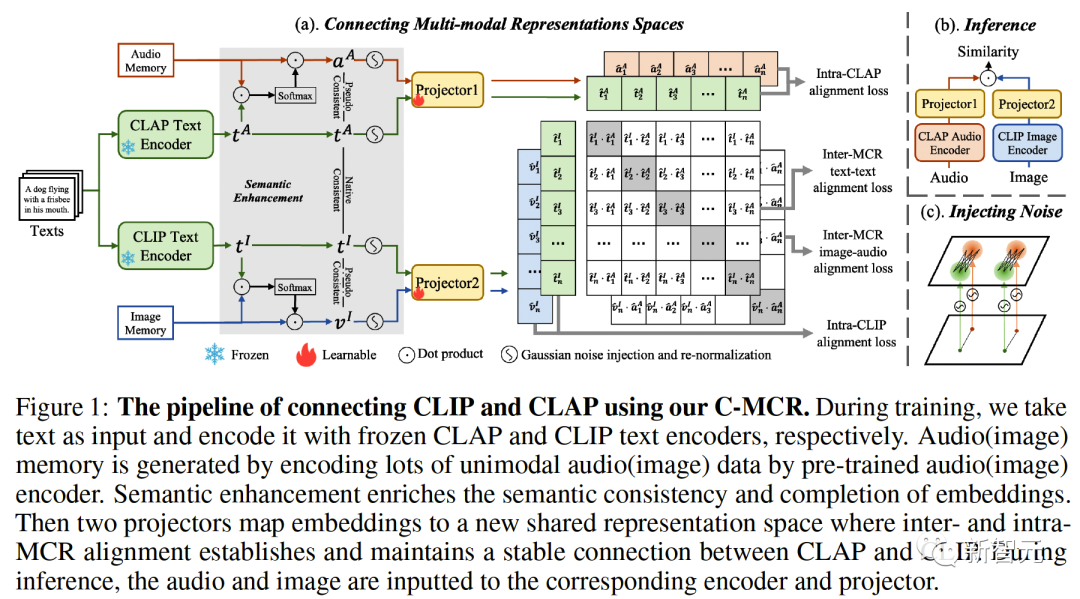
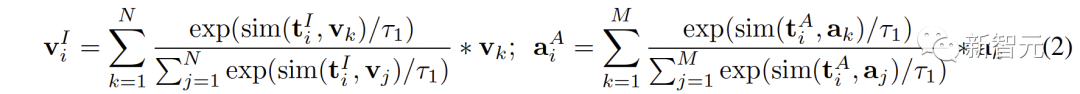
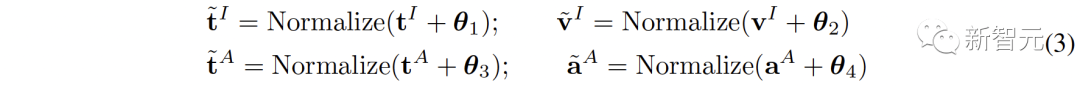
多模态对比表示(MCR)旨在将来自不同模态的输入编码到一个语义对齐的共享空间中 随着视觉-语言领域中CLIP模型的巨大成功,越来越多的模态对比表征开始出现,并在许多下游任务上取得明显的改善,但这些方法严重依赖于大规模高质量的配对数据 为了解决这个问题,来自浙江大学等机构的研究人员提出了连接多模态对比…
-
阿里 8B 模型拿下多页文档理解新 SOTA,324 个视觉 token 表示一页,缩减 80%

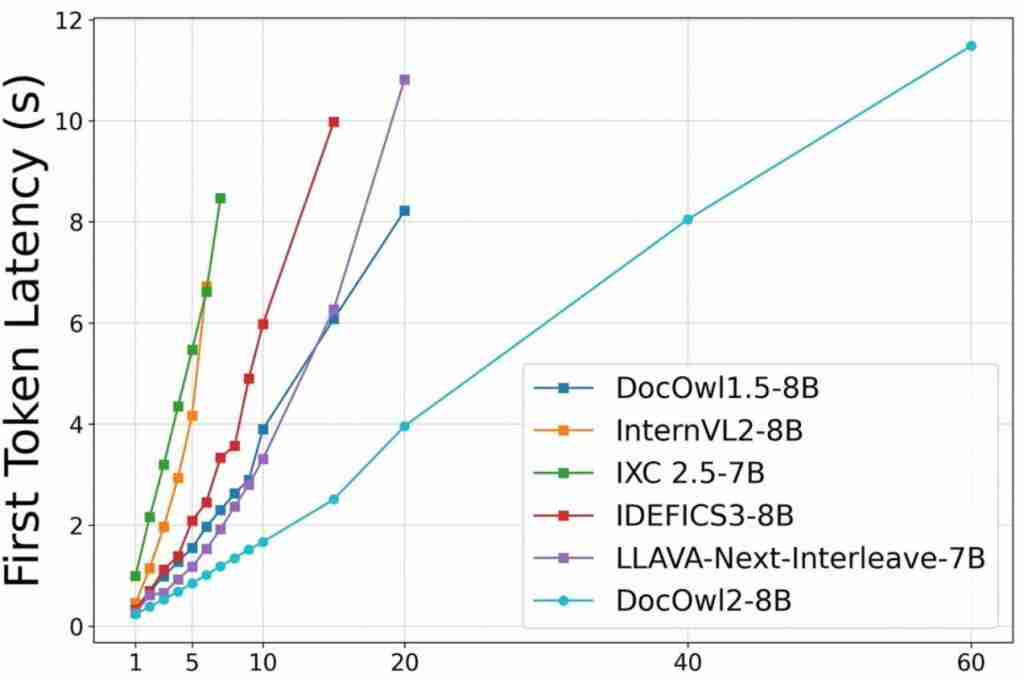
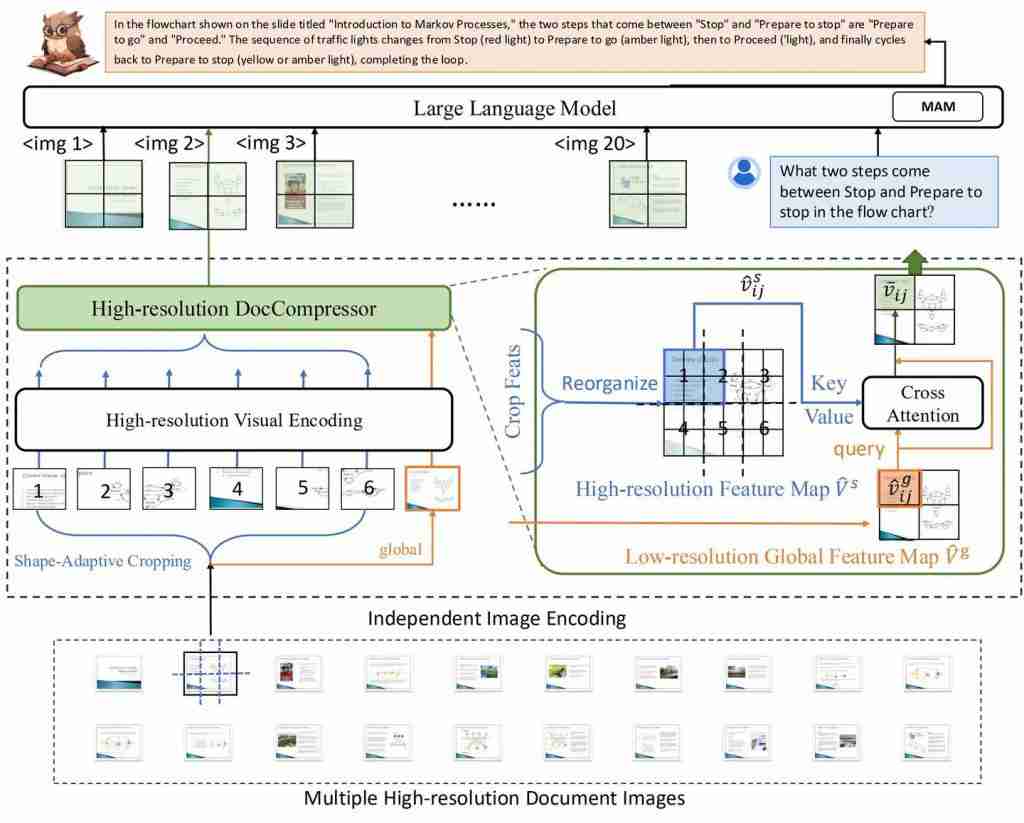
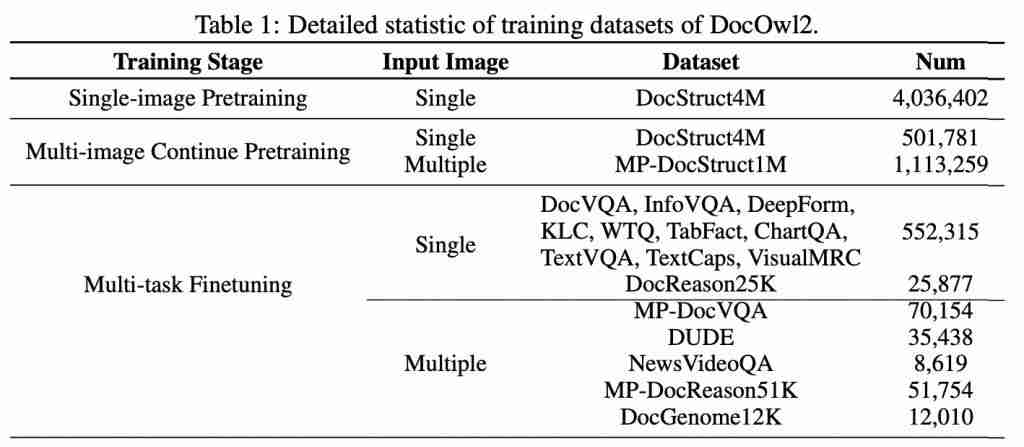
高效多页文档理解,阿里通义实验室 mplug 团队拿下新 sota。 最新多模态大模型mPLUG-DocOwl 2,仅以 324 个视觉 token 表示单个文档图片,在多个多页文档问答 Benchmark 上超越此前 SOTA 结果。 并且在 A100-80G 单卡条件下,做到分辨率为 1653&…
-
Stable Video Diffusion来了,代码权重已上线


AI 画图的著名公司 Stability AI,终于入局 AI 生成视频了。 这周二,基于稳定扩散的视频生成模型 Stable Video Diffusion 推出了,AI 社区立即展开了讨论 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ …
-
深度学习中的代码数据增强:5年89篇研究综述

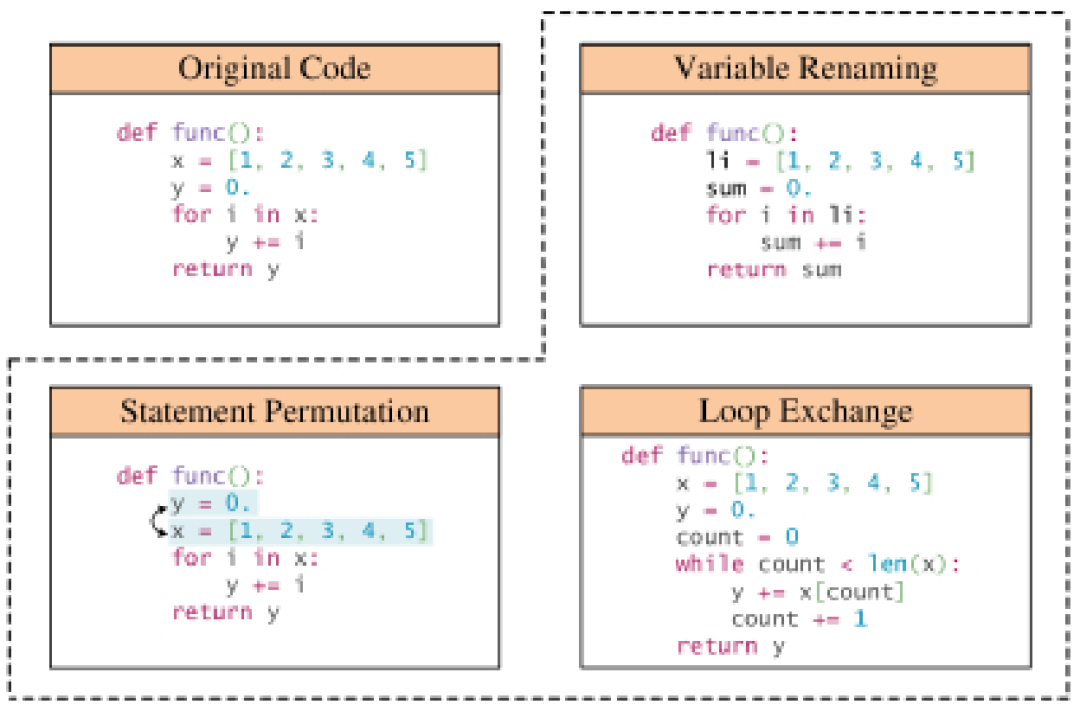

随着深度学习和大型模型的快速发展,对创新技术的追求不断增加。在这个过程中,数据增强技术展现出了不可忽视的价值 最近,由蒙纳士大学、新加坡管理大学、华为诺亚方舟实验室、北京航空航天大学以及澳大利亚国立大学联合进行的对近 5 年的 89 篇相关研究调查,发布了一份关于代码数据增强在深度学习中应用的全面综…
-
新标题:Meta改进Transformer架构:强化推理能力的新注意力机制




大型语言模型(LLM)的强大已经是不容置疑的事实,然而它们有时仍然会犯一些简单的错误,显示出推理能力较弱的一面 举个例子,LLM 可能会因为不相关的上下文或者输入提示中固有的偏好或意见而做出错误的判断。后一种情况表现出的问题被称为「阿谀奉承」,即模型与输入保持一致 是否有任何方法可以缓解这类问题呢?…
-
视频生成新突破:PixelDance,轻松呈现复杂动作与炫酷特效


近期,除了广受关注的大型语言模型持续占据头条,视频生成技术也在不断取得重大突破,多家公司已经相继发布了新的模型 首先,Runway作为最早探索视频生成领域的领头羊之一,升级了其Gen-2模型,带来了电影级别的高清晰度,令人瞩目。同时,视频生成的一致性也得到了重大改进 但是,这种一致性的提升似乎是以牺…
-
SDXL Turbo和LCM带来AI画图的实时生成时代:速度跟打字一样快,图像瞬间呈现


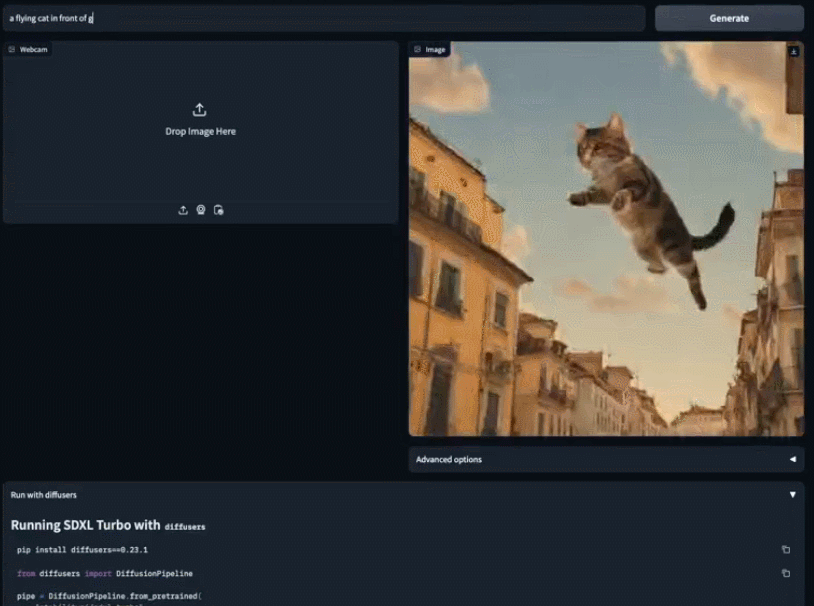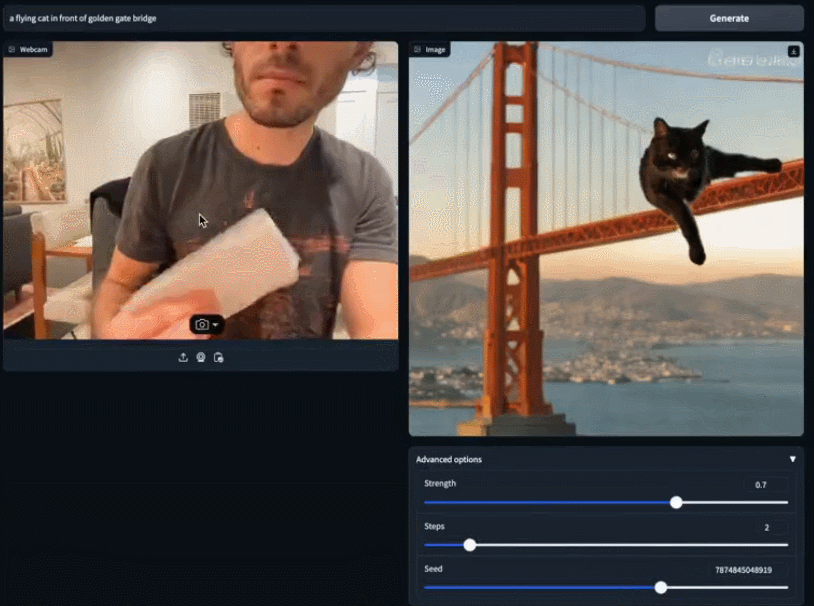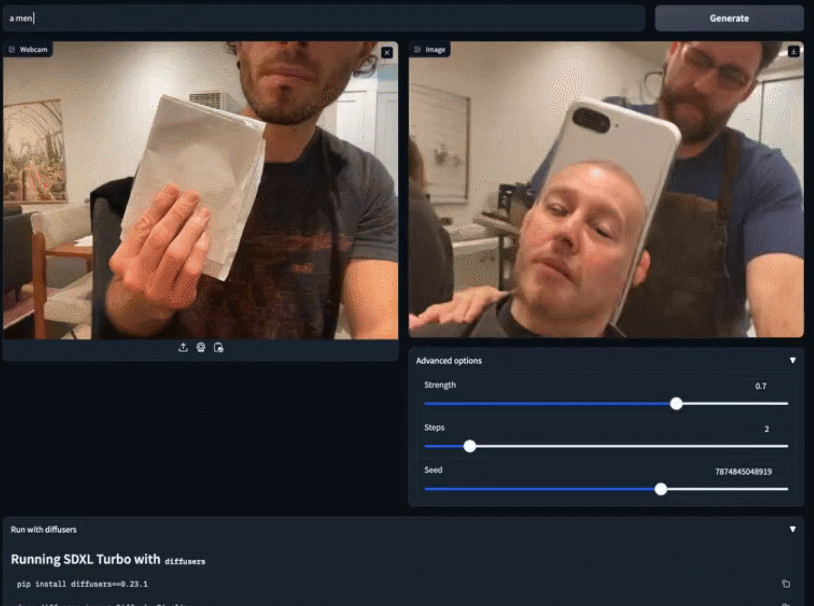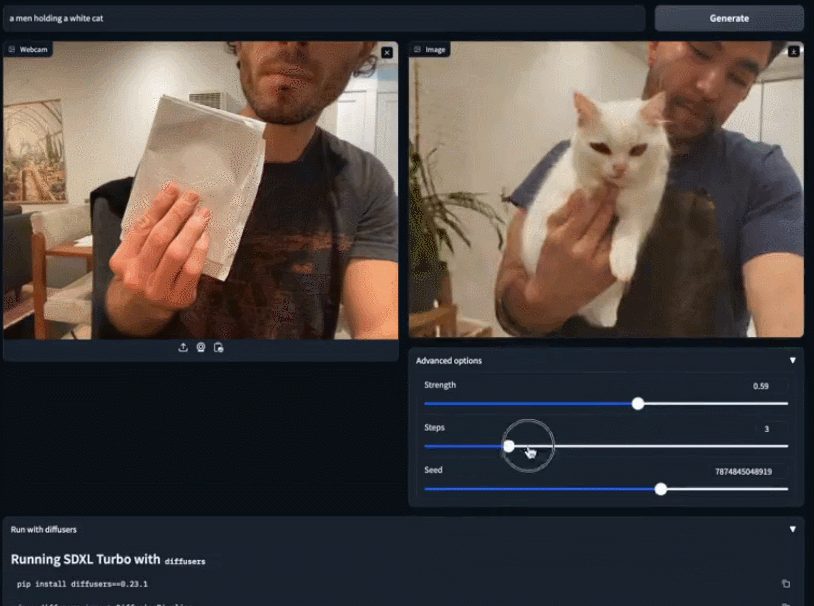

Stability AI在本周二推出了新一代的图像合成模型——Stable Diffusion XL Turbo,这款模型引起了人们的热烈反响。许多人表示,使用该模型进行图像到文本生成变得前所未有的容易 在输入框中输入你的想法,SDXL Turbo 将快速响应并生成相应的内容,无需其他操作。无论你输…
-
一张照片生成视频,张嘴、点头、喜怒哀乐,都可以打字控制

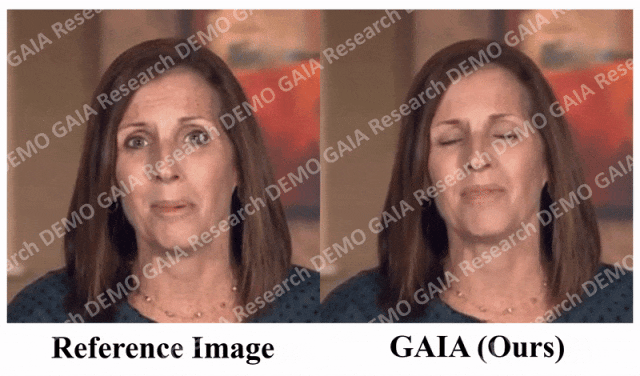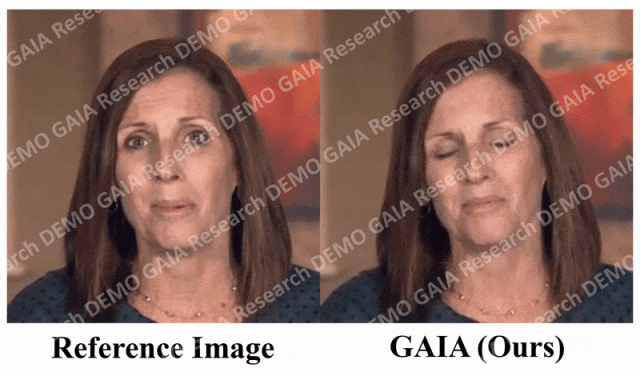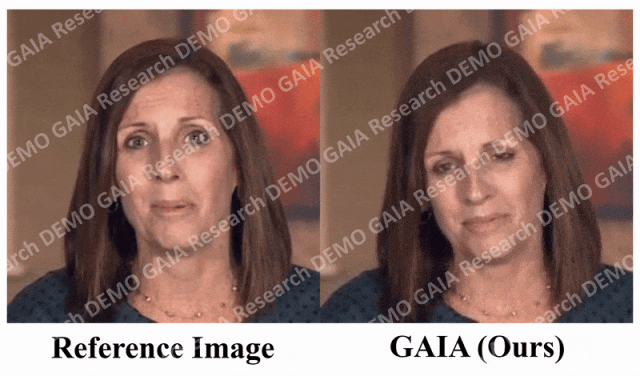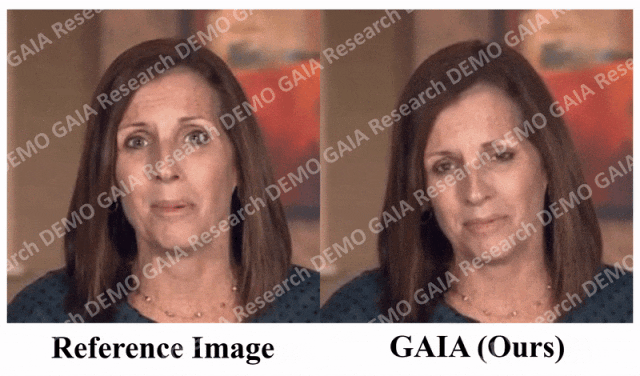


最近,微软进行的一项研究揭示了视频处理软件PS的灵活程度有多高 在这项研究中,你只要给 AI 一张照片,它就能生成照片中人物的视频,而且人物的表情、动作都是可以通过文字进行控制的。比如,如果你给的指令是「张嘴」,视频中的人物就会真的张开嘴。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费…
