
beam可以解决什么问题?当mapreduce作业从hadoop迁移到spark或flink,就需要大量的重构。dataflow试图成为代码和执行运行时环境之间的一个抽象层。代码用dataflow sdk实施后,会在多个后端上运行,比如flink和spark。beam支持java和python,与其他语言绑定的机制在开发中。它旨在将多种语言、框架和sdk整合到一个统一的编程模型。
背景
Google是最早实践大数据的公司,目前大数据繁荣的生态很大一部分都要归功于Google最早的几篇论文,这几篇论文早就了以Hadoop为开端的整个开源大数据生态,但是很可惜的是Google内部的这些系统是无法开源的,在开源生态和云计算兴起之后,Google也是受够了闭源的痛苦,据说为了给用户提供HBase服务,Google还为BigTable写了兼容HBase的API,在Google看来这就是一种羞辱,痛定思痛,Google开始走开源之路,将自己的标准推广给社区,这就是Apache Beam项目诞生的整个大背景。整个Beam项目的演进历史为:
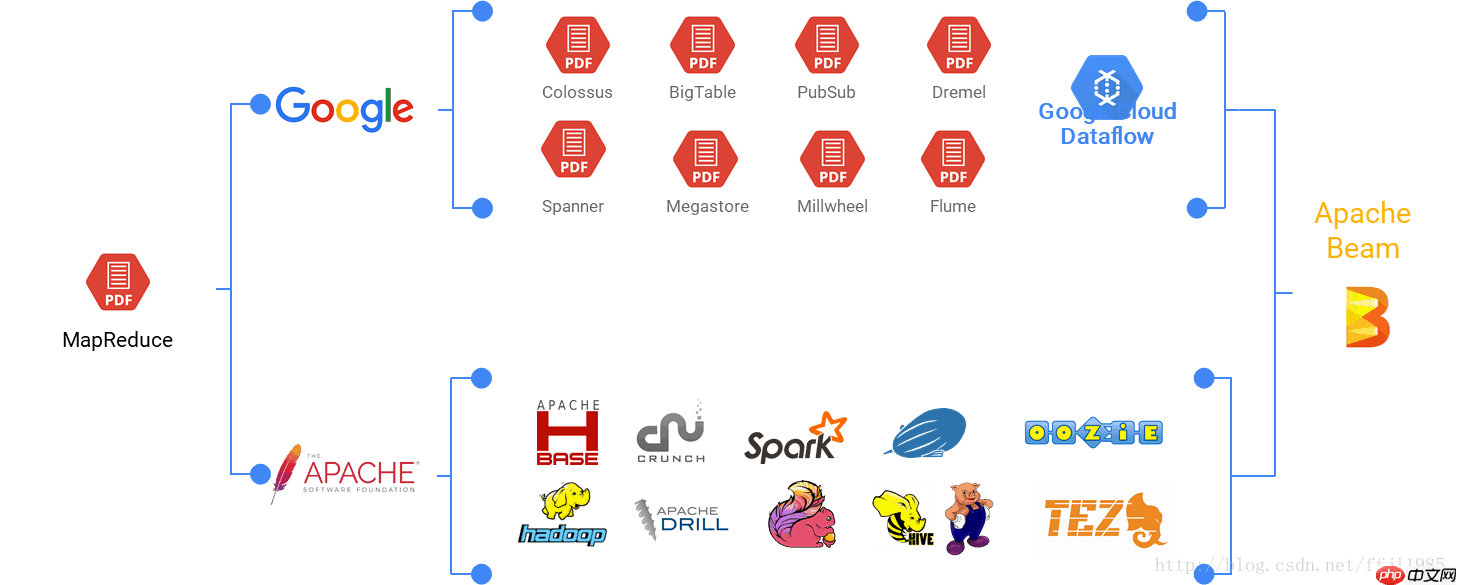
要说Apache Beam,先要说说谷歌Cloud Dataflow。Dataflow是一种原生的谷歌云数据处理服务,是一种构建、管理和优化复杂数据流水线的方法,用于构建移动应用、调试、追踪和监控产品级云应用。它采用了谷歌内部的技术Flume和MillWhell,其中Flume用于数据的高效并行化处理,而MillWhell则用于互联网级别的带有很好容错机制的流处理。该技术提供了简单的编程模型,可用于批处理和流式数据的处理任务。她提供的数据流管理服务可控制数据处理作业的执行,数据处理作业可使用DataFlow SDK创建。
Apache Beam本身不是一个流式处理平台,而是一个统一的编程框架,它提供了开源的、统一的编程模型,帮助你创建自己的数据处理流水线,实现可以运行在任意执行引擎之上批处理和流式处理任务。Beam对流式计算场景中的所有问题重新做了一次归纳,然后针对这些问题提出了几种不同的解决模型,然后再把这些模型通过一种统一的语言给实现出来,最终这些Beam程序可以运行在任何一个计算平台上(只要相应平台——即Runner实现了对Beam的支持)。它的特点有:
统一的:对于批处理和流式处理,使用单一的编程模型;可移植的:可以支持多种执行环境,包括Apache Apex、Apache Flink、Apache Spark和谷歌Cloud Dataflow等;可扩展的:可以实现和分享更多的新SDK、IO连接器、转换操作库等;
Beam特别适合应用于并行数据处理任务,只要可以将要处理的数据集分解成许多相互独立而又可以并行处理的小集合就可以了。Beam也可以用于ETL任务,或者单纯的数据整合。这些任务主要就是把数据在不同的存储介质或者数据仓库之间移动,将数据转换成希望的格式,或者将数据导入一个新系统。
概念
Apache Beam是大数据的编程模型,定义了数据处理的编程范式和接口,它并不涉及具体的执行引擎的实现,但是,基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上,目前Dataflow、Spark、Flink、Apex提供了对批处理和流处理的支持,GearPump提供了流处理的支持,Storm的支持也在开发中。
综上所述,Apache Beam的目标是提供统一批处理和流处理的编程范式,为无限、乱序、互联网级别的数据集处理提供简单灵活、功能丰富以及表达能力十分强大的SDK,目前支持Java、Python和Golang。
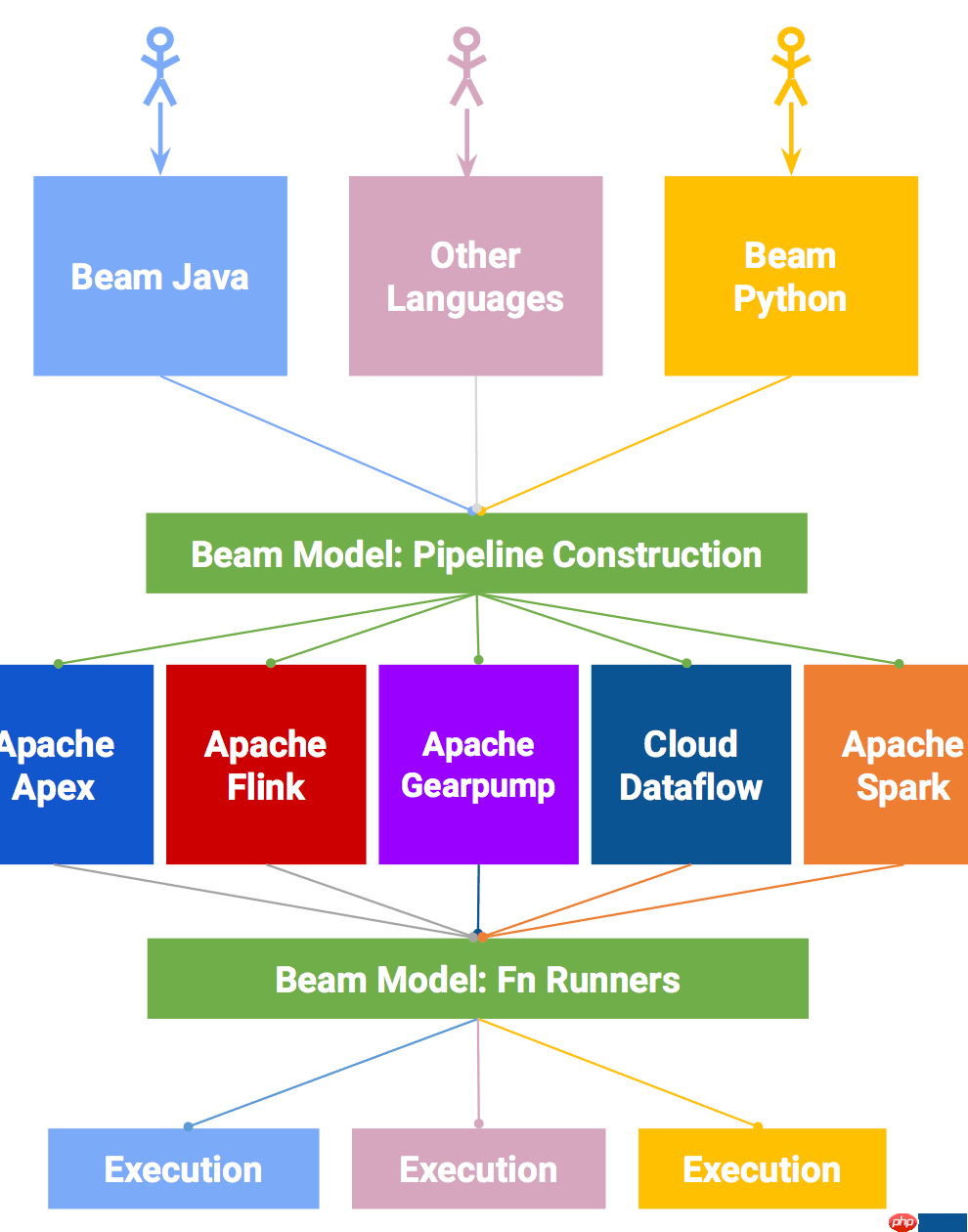
通过上图,我们可以清楚的知道,执行一个流程分以下步骤:
End Users:选择一种你熟悉的编程语言提交应用。SDK Writers:该编程语言必须是 Beam 模型支持的。Library Writers:转换成Beam模型的格式。Runner Writers:在分布式环境下处理并支持Beam的数据处理管道。IO Providers:在Beam的数据处理管道上运行所有的应用。DSL Writers:创建一个高阶的数据处理管道。SDK & Runner
Beam主要包含两个关键的部分:
 仿探探应用首页滑动切换
仿探探应用首页滑动切换
仿探探应用首页滑动切换
 27 查看详情
27 查看详情  Beam SDK
Beam SDK
Beam SDK提供一个统一的编程接口给到上层应用的开发者,开发者不需要了解底层的具体的大数据平台的开发接口是什么,直接通过Beam SDK的接口,就可以开发数据处理的加工流程,不管输入是用于批处理的有限数据集,还是流式的无限数据集。对于有限或无限的输入数据,Beam SDK都使用相同的类来表现,并且使用相同的转换操作进行处理。Beam SDK可以有不同编程语言的实现,目前已经完整地提供了Java,python的SDK还在开发过程中,相信未来会有更多不同的语言的SDK会发布出来。
Beam Pipeline Runner
Beam Pipeline Runner将用户用Beam模型定义开发的处理流程翻译成底层的分布式数据处理平台支持的运行时环境。在运行Beam程序时,需要指明底层的正确Runner类型。针对不同的大数据平台,会有不同的Runner。目前Flink、Spark、Apex以及谷歌的Cloud DataFlow都有支持Beam的Runner。
需要注意的是,虽然Apache Beam社区非常希望所有的Beam执行引擎都能够支持Beam SDK定义的功能全集,但是在实际实现中可能并不一定。例如,基于MapReduce的Runner显然很难实现和流处理相关的功能特性。就目前状态而言,对Beam模型支持最好的就是运行于谷歌云平台之上的Cloud Dataflow,以及可以用于自建或部署在非谷歌云之上的Apache Flink。当然,其它的Runner也正在迎头赶上,整个行业也在朝着支持Beam模型的方向发展。
Sum up
随着分布式数据处理不断发展,新的分布式数据处理技术也不断被提出,业界涌现出了越来越多的分布式数据处理框架,从最早的Hadoop MapReduce,到Apache Spark,Apache Storm,以及更近的Apache Flink,Apache Apex等。新的分布式处理框架可能带来的更高的性能,更强大的功能,更低的延迟等,但用户切换到新的分布式处理框架的代价也非常大:需要学习一个新的数据处理框架,并重写所有的业务逻辑。解决这个问题的思路包括两个部分,首先,需要一个编程范式,能够统一,规范分布式数据处理的需求,例如,统一批处理和流处理的需求。其次,生成的分布式数据处理任务应该能够在各个分布式执行引擎上执行,用户可以自由切换分布式数据处理任务的执行引擎与执行环境。Apache Beam正是为了解决以上问题而提出的。
如Apache Beam项目的主要推动者Tyler Akidau所说:
对此,Data Artisan的Kostas Tzoumas在他的博客中说:
目前主流流数据处理框架Flink、Spark、Apex以及谷歌的Cloud DataFlow等都有了支持Beam的Runner。
以上就是Apache Beam 初探的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/366535.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















