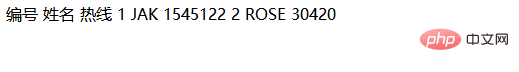本文深入探讨了在使用XPath进行文本提取时,text()函数可能无法按预期工作的问题,特别是在存在多个文本节点或空白字符时。文章通过一个具体案例,详细介绍了如何利用XPath 1.0的substring-after函数,结合精确的元素定位,从复杂HTML结构中准确提取出目标文本,避免了text()直接提取的局限性,并提供了实用的解决方案和注意事项。
理解XPath text() 函数的局限性
在xpath中,text()函数常用于提取元素的直接文本子节点。然而,当一个元素包含多个文本节点(例如,文本被其他子元素分隔,或包含空白字符的文本节点)时,text()的行为可能会变得复杂,尤其是在xpath 1.0环境中。
考虑以下HTML结构:
我们的目标是提取 Aug 7, 2019 at 9:34 am ET 这段文本。如果尝试使用常见的XPath表达式 //span[@class=”meta”]/text(),可能会发现它返回空值或者并非我们期望的结果。这是因为:
text() 返回的是一个文本节点集合(node-set),而不是一个单一的字符串。在这个特定的HTML结构中,span 元素内部的文本节点可能不止一个。例如, 之后可能有一个只包含换行符和空格的文本节点,然后是 |,再之后才是目标日期时间文本。在XPath 1.0中,当一个函数需要一个字符串参数,而你提供了一个节点集时,它通常只会使用节点集中的第一个节点进行字符串转换。如果第一个文本节点是空白或不相关的内容,那么结果就会不符合预期。
例如,在上述HTML中,//span[@class=”meta”]/text() 可能返回的第一个文本节点是 … 标签后的换行符和空格,或者 | 之前的空白。
利用 substring-after 进行精确文本提取
为了解决 text() 函数的局限性并精确提取目标文本,我们可以采用更高级的策略:
获取父元素的完整字符串值: 一个元素的字符串值是其所有后代文本节点(包括其自身直接的文本子节点)的连接。使用 substring-after 函数进行截取: 如果目标文本紧跟在一个已知的分隔符之后,我们可以使用 substring-after(string, delimiter) 函数来获取分隔符之后的所有内容。
针对上述HTML结构,我们可以使用 | 作为分隔符。首先,我们需要找到包含目标文本的父 元素。一个更健壮的方法是利用其子元素 的属性来定位:
//span[span/a/@rel="author"]
这个XPath表达式会找到所有 class=”meta” 的 元素,并且这个 元素内部含有一个 子元素,该子元素又含有一个 标签,且 标签的 rel 属性值为 “author”。这确保了我们定位到的是正确的父元素。
接下来,我们将 substring-after 函数应用于这个父元素的字符串值,并以 ‘ |’ 作为分隔符:
substring-after(//span[span/a/@rel="author"],' |')
解析这个表达式:
//span[span/a/@rel=”author”]:这部分定位到了包含目标文本的父 元素。它比 //span[@class=”meta”] 更具鲁棒性,因为它依赖于内部元素的特定结构,而不是仅仅一个可能重复的 class 属性。substring-after(string, delimiter):这是一个XPath 1.0函数,用于返回 string 中 delimiter 之后的部分。在这里,string 参数隐式地是 //span[span/a/@rel=”author”] 这个节点集的第一个节点的字符串值。这个字符串值会是 “Author | Aug 7, 2019 at 9:34 am ET”(忽略内部标签,连接所有文本)。delimiter 参数是 ‘ |’。
执行这个XPath表达式,将精确地返回:
Aug 7, 2019 at 9:34 am ET
注意事项与总结
XPath版本: 上述解决方案基于XPath 1.0。在XPath 2.0及更高版本中,text() 返回的节点集可以直接进行操作,例如 //span[@class=”meta”]/text()[last()] 可能会返回最后一个文本节点,或者 string-join(//span[@class=”meta”]/text(), ”) 可以连接所有文本节点。然而,substring-after 仍然是一个非常实用的函数,尤其是在有明确分隔符的情况下。分隔符的选择: 选择一个在目标文本之前且独一无二的分隔符至关重要。如果分隔符可能出现在目标文本内部,或者有多个相同分隔符,substring-after 可能会返回不期望的结果。元素定位的鲁棒性: 在实际应用中,构建XPath表达式时,应尽量使其具有鲁棒性,避免过度依赖可能变化的属性(如 class)或层级结构。通过结合子元素的特定属性(如 rel=”author”),可以大大提高XPath的稳定性。空白字符处理: substring-after 函数会保留分隔符之后的原始空白字符。如果需要去除这些空白,可以结合 normalize-space() 函数,例如 normalize-space(substring-after(//span[span/a/@rel=”author”],’ |’))。
通过理解 text() 的工作原理及其局限性,并灵活运用 substring-after 等字符串函数,我们可以更精确、更高效地从复杂的HTML或XML文档中提取所需文本。这种方法在处理非标准或结构不规整的网页数据时尤其有效。
以上就是XPath文本提取进阶:利用substring-after精确获取目标文本的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1582625.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫