
fig
-
通义千问再开源,Qwen1.5带来六种体量模型,性能超越GPT3.5
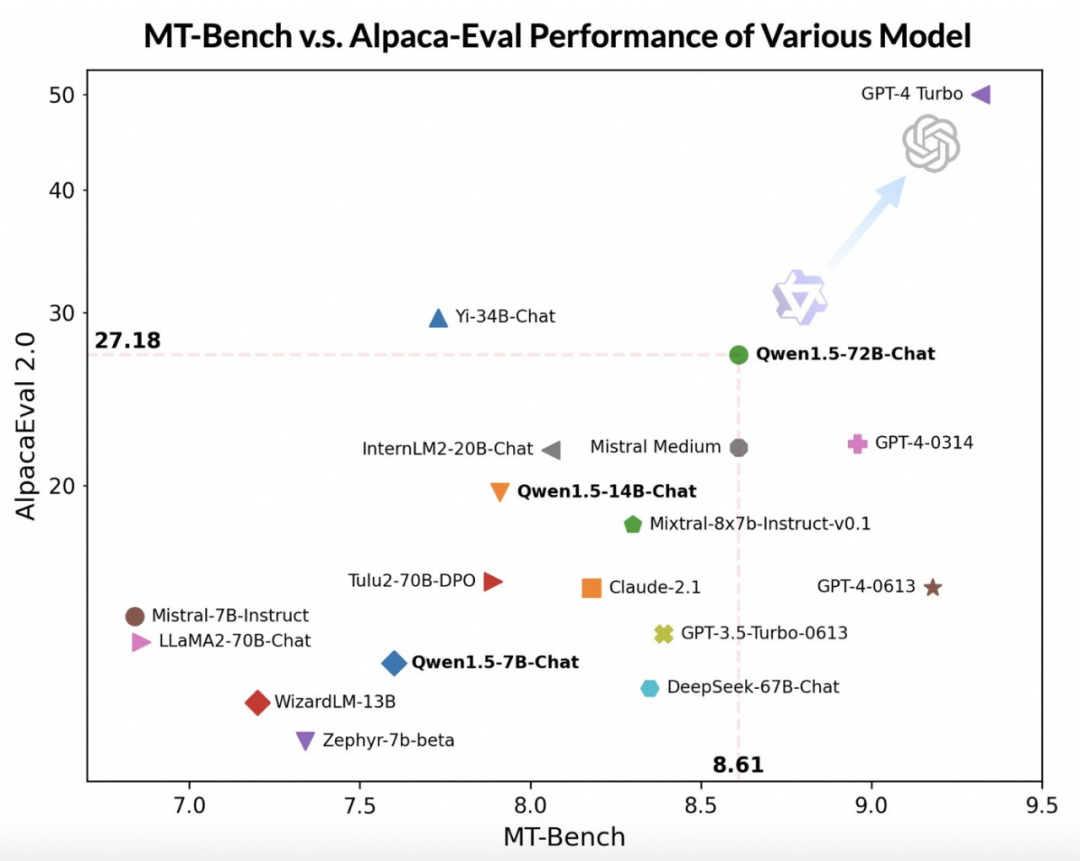

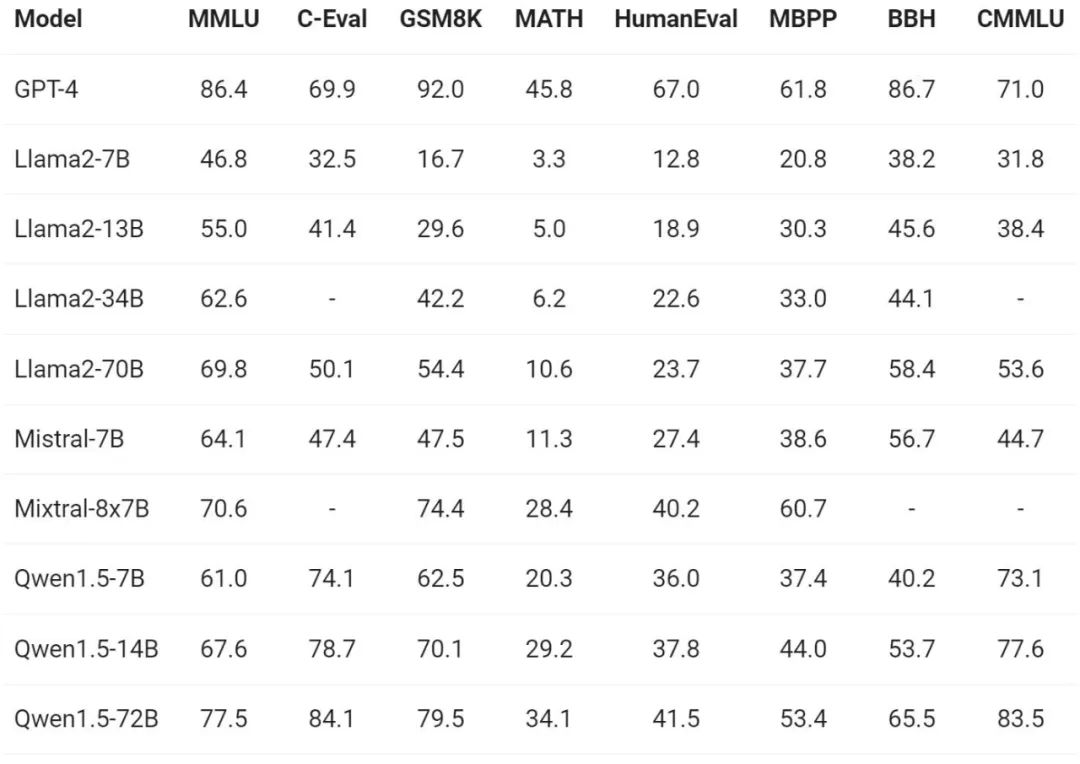
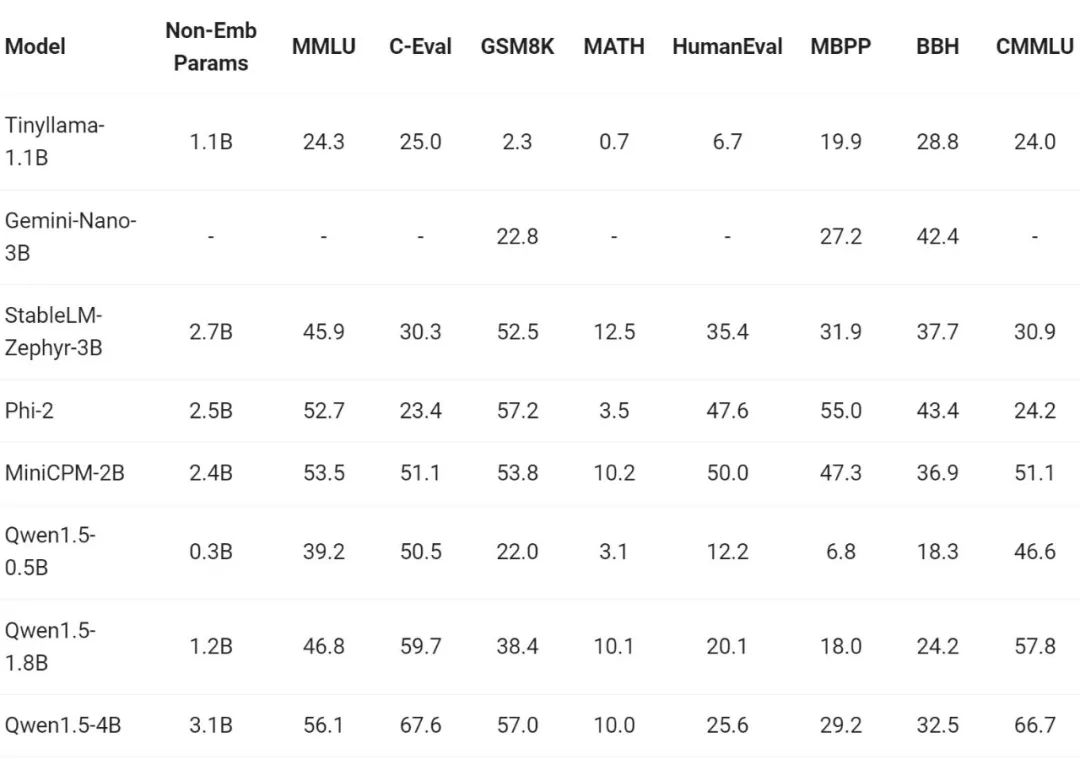
赶在春节前,通义千问大模型(qwen)的 1.5 版上线了。今天上午,新版本的消息引发了 ai 社区关注。 新版大模型包括六个型号尺寸:0.5B、1.8B、4B、7B、14B和72B。其中,最强版本的性能超越了GPT 3.5和Mistral-Medium。该版本包含Base模型和Chat模型,并提供…
-
机器学习中的十种非线性降维技术对比总结

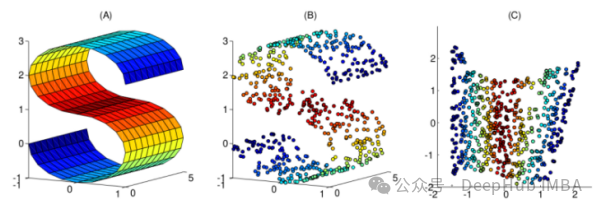
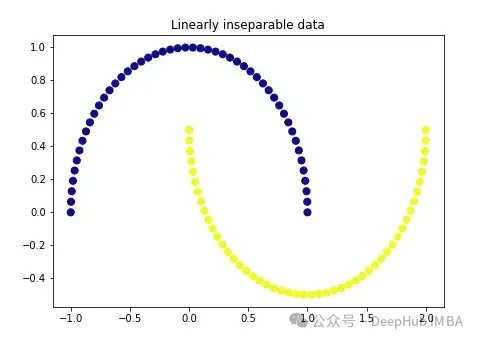
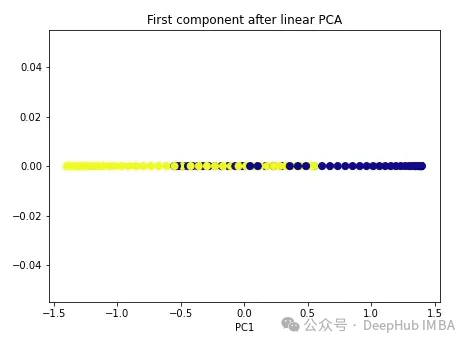
降维是指在减少数据集特征数量的同时,尽可能保留数据的主要信息。降维算法属于无监督学习,通过未标记数据来训练算法。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 尽管降维方法种类繁多,但它们都可以归为两大类:线性和非线性。 线性方法将数据从高…
-
斯坦福20亿参数端测多模态AI Agent模型大升级,手机汽车机器人都能用

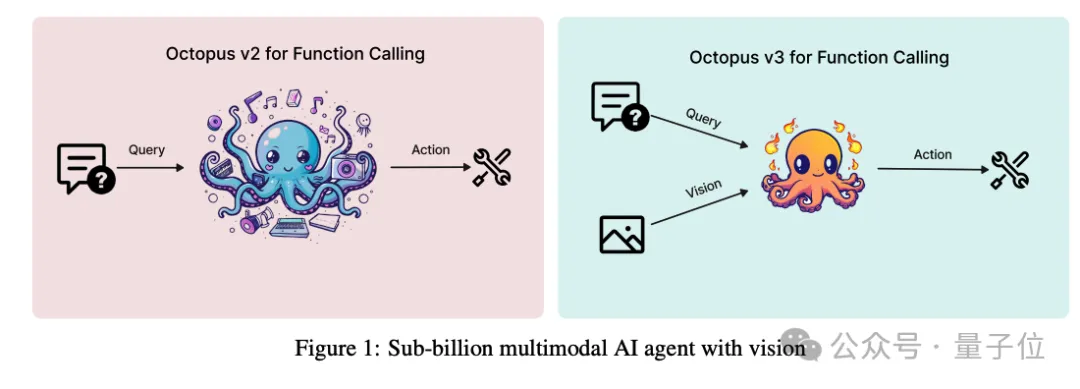
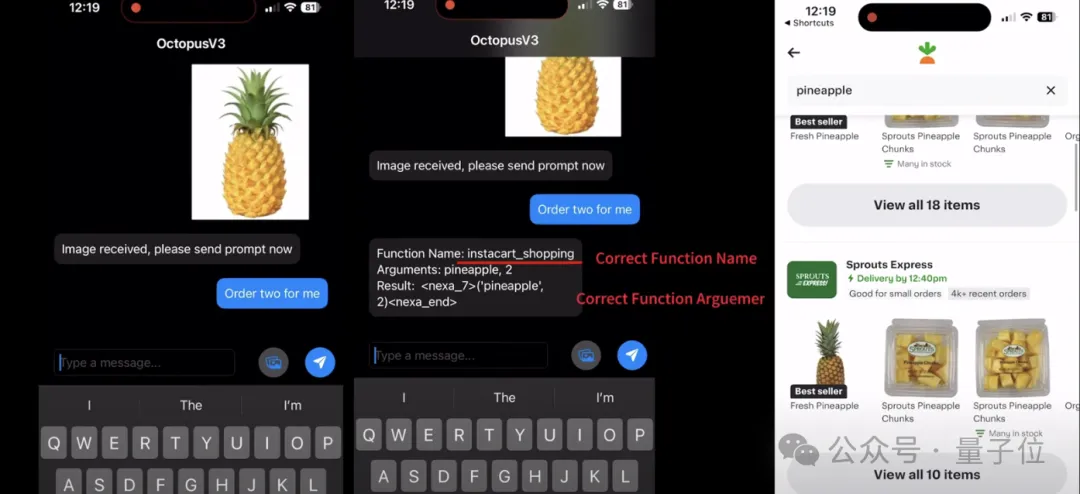
全球首个超小型多模态ai agent模型octopus v3,来自斯坦福大学的nexa ai团队,让agent更加智能、快速、能耗及成本降低。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 今年四月份初,NEXA AI推出了备受瞩目的Oct…
-
NeurIPS 2024 | 消除多对多问题,清华提出大规模细粒度视频片段标注新范式VERIFIED




☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢…
-
全自动打工「人」!波士顿动力Atlas进厂视频火了,不断电不下班




波士顿动力atlas进厂打工,不靠远程操控,转身动作像惊悚电影。 波士顿动力的人形机器人,进厂了。 本周三,波士顿动力发来一条喜讯。其最新披露的视频展示了机器人在工厂环境中的任务完成能力。机器人现在已经可以全自动干活了,它可以在储物柜之间搬动汽车发动机零件: ☞☞☞AI 智能聊天, 问答助手, AI…
-
基于paddlehub2.4.0: 让动态视频生成漫画书!【一键运行】


该项目基于PaddleHub2.4.0,实现动态视频转漫画书功能。以人民美术出版社版《水浒传》连环画为风格学习数据,借助其预训练模型,通过安装依赖、处理数据、图片转漫画、视频关键帧转漫画等步骤,抽取视频关键帧并转为漫画风格,为视频创作提供新形式,展现了AI在文化创意领域的潜力。 ☞☞☞AI 智能聊天…
-
【AI达人特训营第三期】时频图分类项目

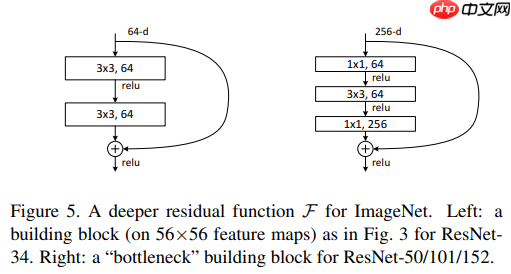

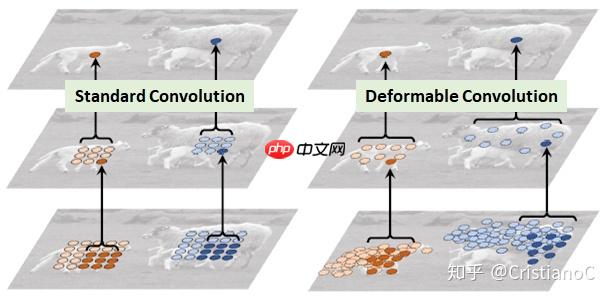
本项目基于ResNet50,将其BottleneckBlock模块中conv2特征层的标准卷积替换为DCN可变性卷积,构建ResNet50-DCN模型,用于科大讯飞24类语音时序图谱分类。使用2143条训练样本、429条验证样本训练,90轮后验证集最高准确率79%,未深入调优,有提升空间,还包含数据…
-
点云生成:基于Paddle2.0实现WGAN-GP在点云上的一些尝试
本文尝试在点云上应用WGAN-GP,判别器借鉴PointNet结构,生成器为自定义搭建。使用ModelNet40数据集,取1024个点训练。定义了FeatureNet、UFeatureNet等网络,通过Adam优化器训练,每2轮可视化生成结果,20轮保存模型,目前可运行但效果待提升。 ☞☞☞AI 智…
-
【AI达人特训营第三期】Conv2Former:一种ViT风格的卷积模块

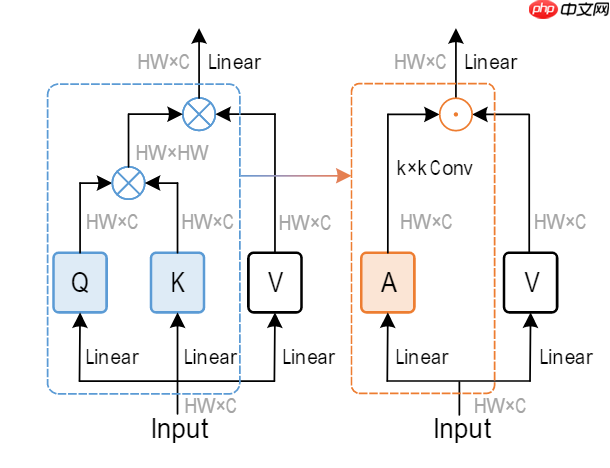
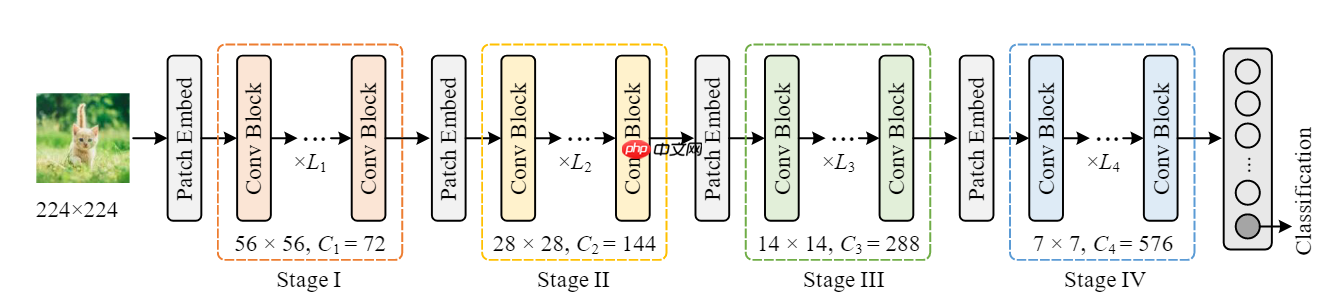
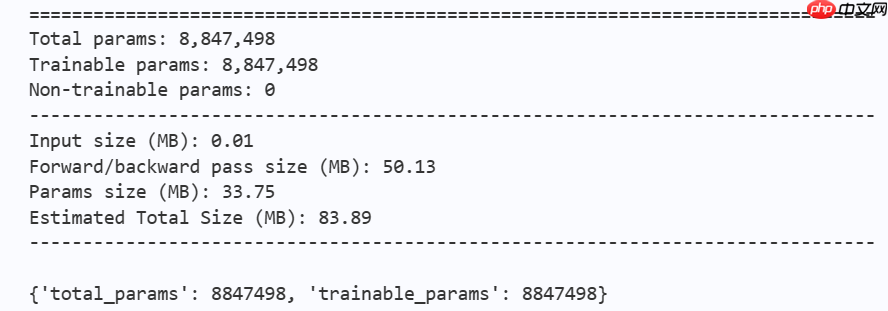
本文复现了Conv2Former模型,其采用Transformer风格的QKV结构,以卷积生成权重加权,平衡全局信息提取与计算开销。在CIFAR-10数据集上,用Conv2Former-N参数({64,128,256,512}维度,{2,2,8,2}深度)训练50个epoch,验证集准确率达82%,…
-
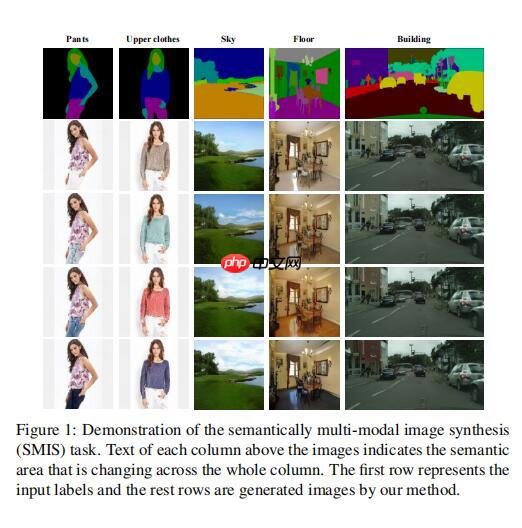
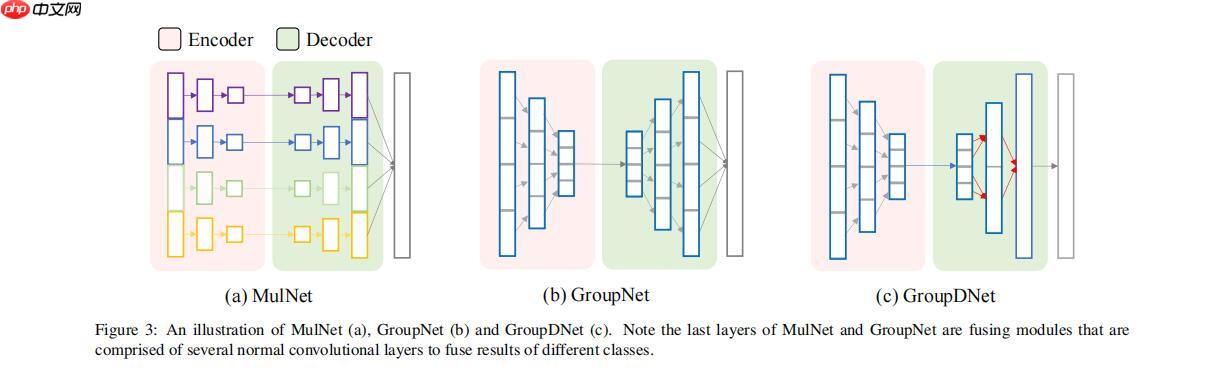
论文解读一篇关于语义生成论文(要求控制单独语义生成)

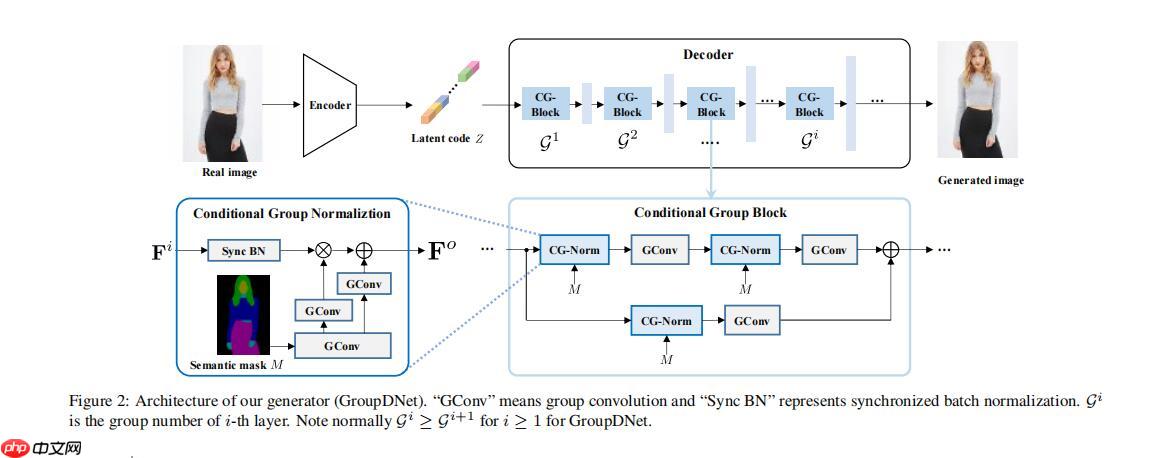
本文聚焦语义多模态图像合成(SMIS)任务,旨在通过特定类控制器调整对应区域生成图像,且不影响其他部分。针对现有方法局限,提出GroupDNet,利用组卷积并逐步减少解码器组数,提升可控性与生成质量。实验表明其优越性,还能支持多种合成应用。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费…

