
latte
-
【PaddlePaddle】基础理论教程 – 机器学习理论实践
本篇讲解机器学习理论。涵盖线性回归与逻辑回归的理论与实践,重点讲解数据预处理、模型构建与训练、性能评估及可视化,结合PaddlePaddle框架,系统学习深度学习开发流程并积累实战经验 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ 前言 上…
-
SimAM:无参数Attention!助力分类/检测/分割涨点!

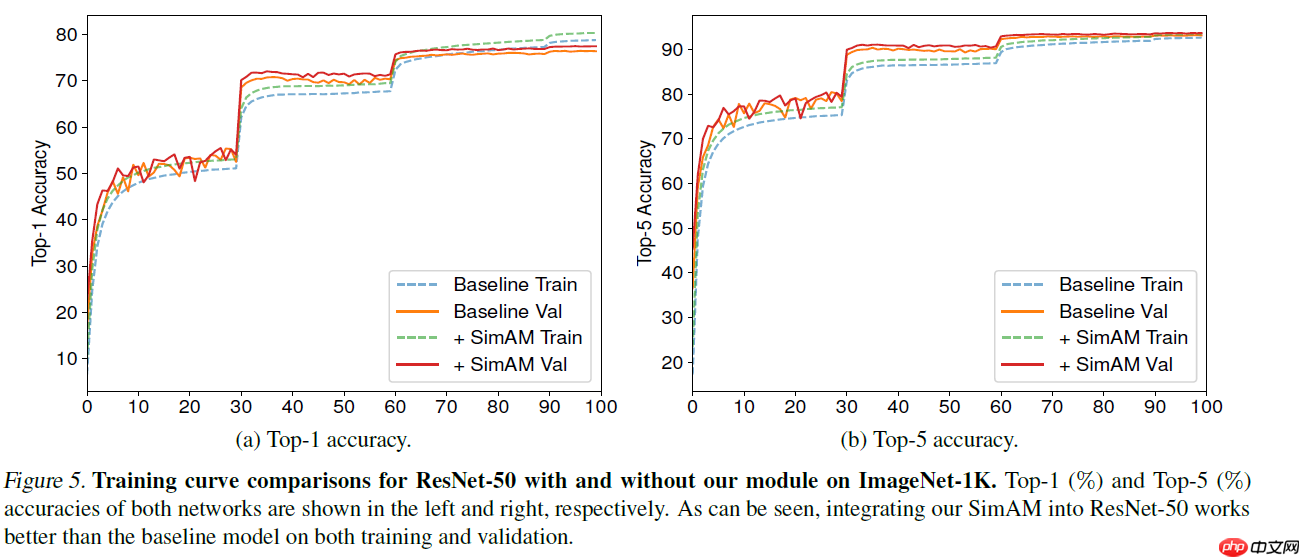
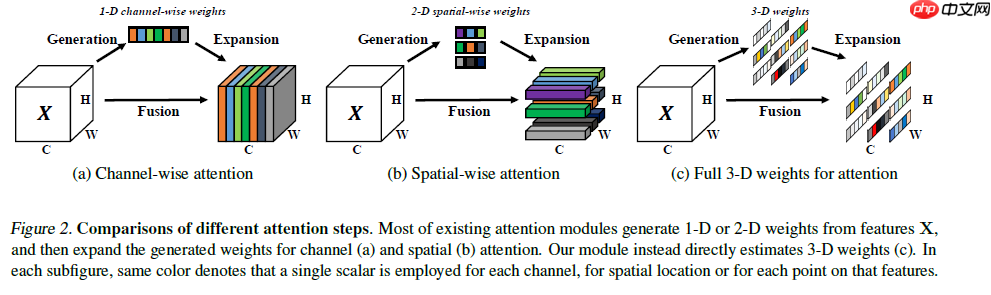

本项目基于中山大学提出的无参数SimAM注意力机制,在Caltech101的16类子集上验证其效果。SimAM从神经科学出发,通过能量函数挖掘神经元重要性,生成三维权重,优于传统一维、二维注意力。项目构建含SimAM的TowerNet模型,与ResNet50等经典网络对比,经数据准备、模型训练后,显…
-
ConvMixer:Patches are all you need?

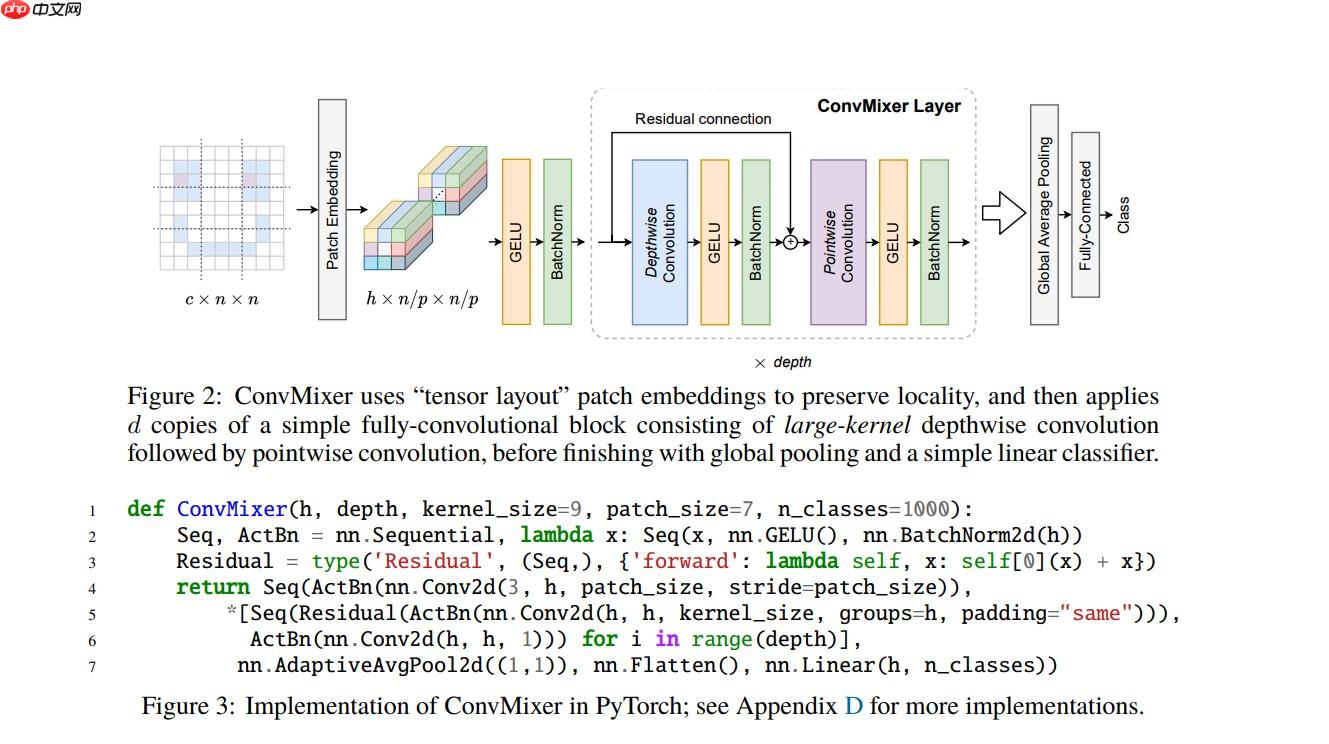
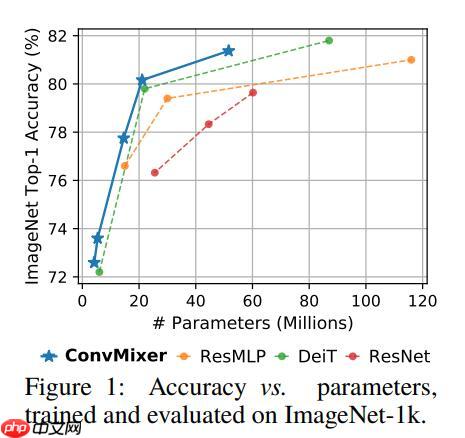
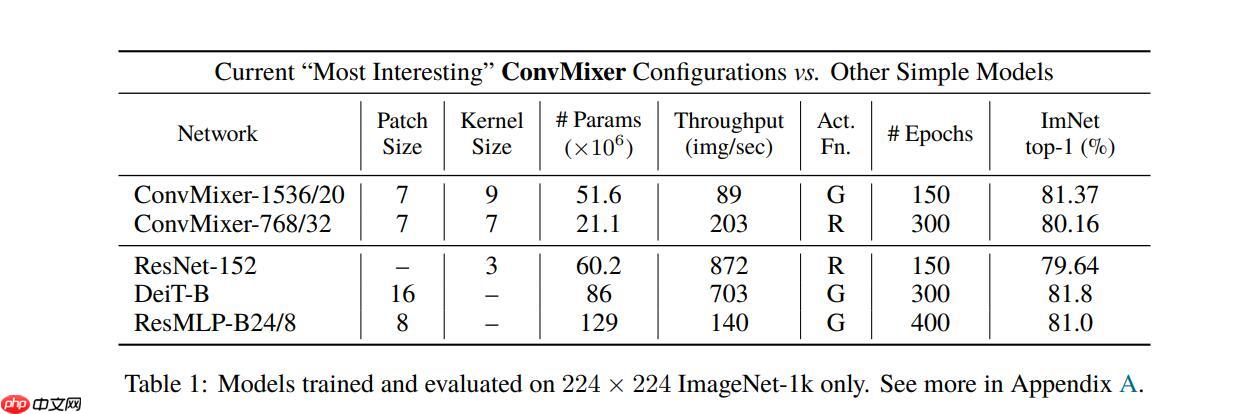
ConvMixer是基于卷积层进行Mixer操作的模型,结构简单却精度不错。它与MLP Mixer类似,通过交替混合channel和token维度信息提取图像特征,但用卷积替代MLP。其用逐通道卷积提取token信息,1×1卷积提取channel信息,官方提供三个预训练模型,在ImageN…
-
Paddle2.0:浅析并实现 FcaNet 模型
FcaNet通过频率域分析重新审视通道注意力,证明GAP是二维DCT的特例。据此将通道注意力推广到频域,提出多谱通道注意力框架,通过选择更多频率分量引入更多信息。实验显示,其在ImageNet和COCO数据集表现优异,基于ResNet时精度高于SENet,且实现简单。 ☞☞☞AI 智能聊天, 问答助…
-
Paddle2.0:浅析并实现 T2T-ViT 模型

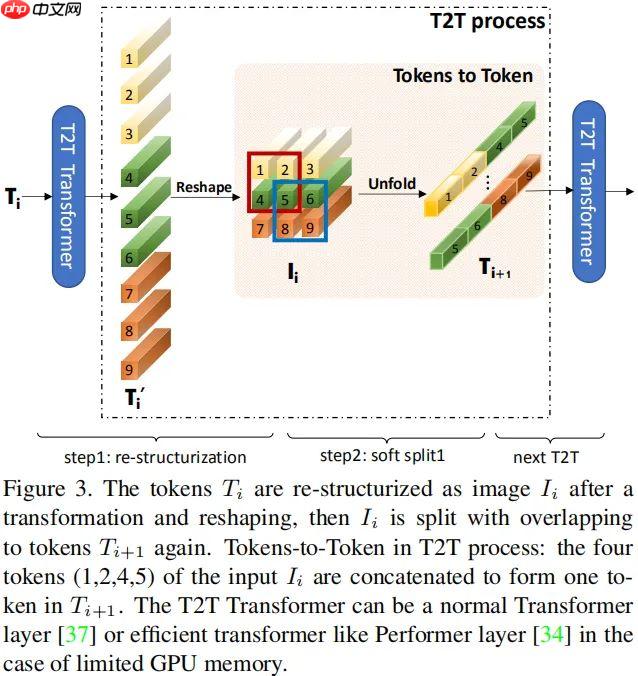
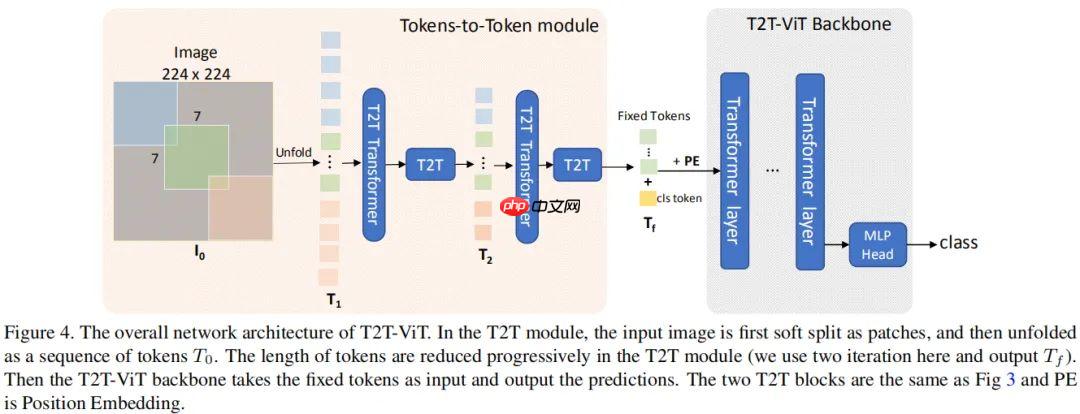
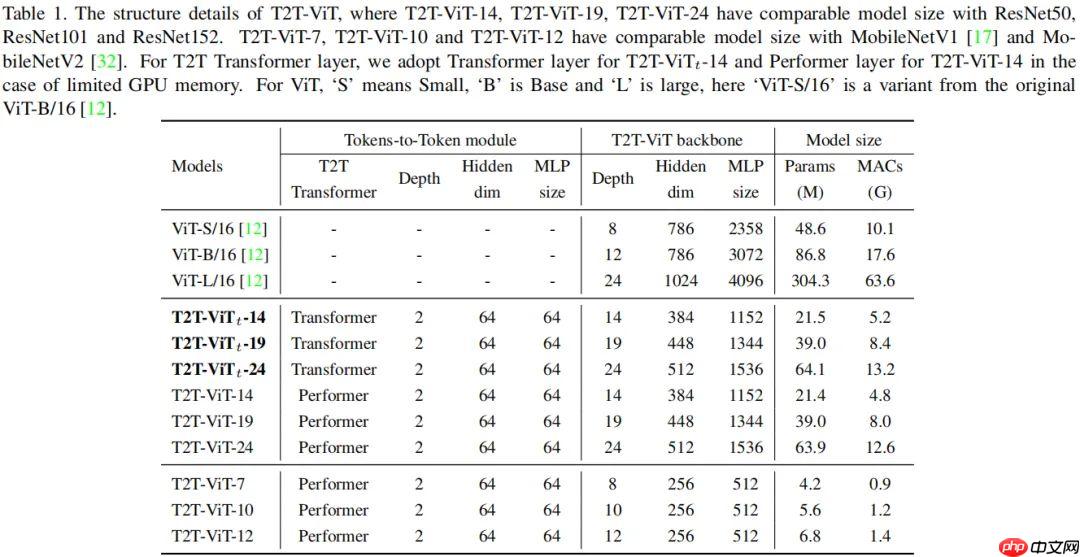
T2T-ViT提出渐进式Token化机制和深窄骨干结构,在ImageNet从头训练,超越CNN与ViT,参数和MAC减少200%,性能更优,如T2T-ViT-7验证集top1精度71.68%。 ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜ …
-
Paddle2.0:浅析并实现 LV-ViT 模型
本文探索提升ViT性能的训练技巧,提出LV-ViT模型。其改进包括增加网络深度、显式引入归纳偏置、改进残差连接、采用Re-labeling和Token Labeling策略及MixToken数据增广等。模型在ImageNet上性能优异,如LV-ViT-L在512分辨率下Top1精度达86.4,超越多…
-
Paddle2.0:浅析并实现 CoaT 模型




本文介绍基于Transformer的图像分类器CoaT,其含Co-Scale和Conv-Attentional机制,能为Vision Transformer提供多尺度和上下文建模功能,性能超T2T-ViT等网络。还阐述了Conv-Attention模块、Co-Scale机制的原理与代码实现,搭建了模…
-
改进的注意力多尺度特征融合卷积神经网络

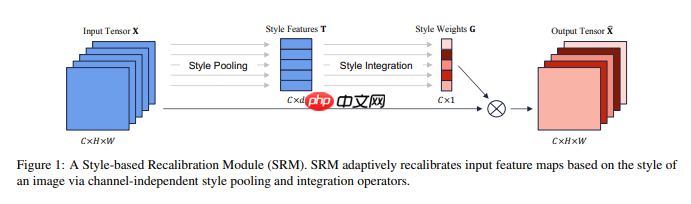
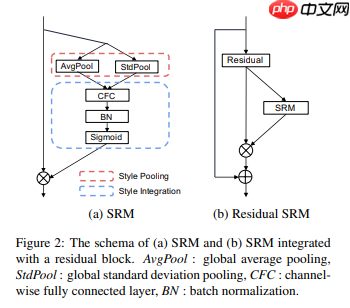
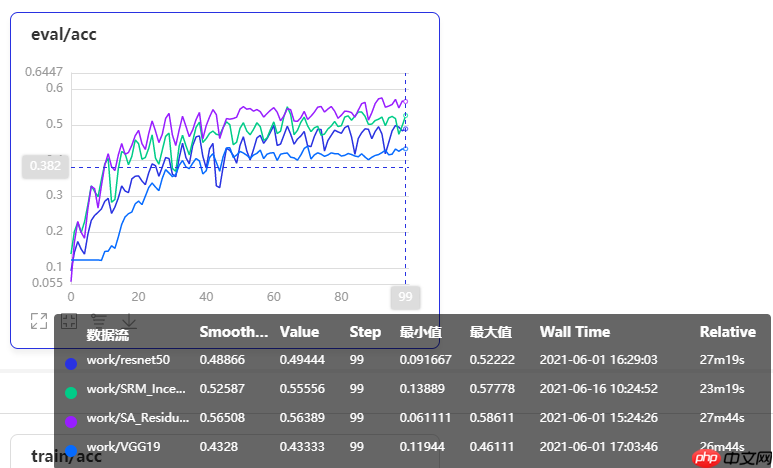
本文改进注意力多尺度特征融合卷积神经网络,加入基于style的重新校准模块(SRM),通过样式池提取特征图通道样式信息,经通道无关的style集成估计权重,增强CNN表示能力且参数少。用Caltech101的16类数据集,对比VGG19、ResNet50等模型,改进模型性能提升较明显。 ☞☞☞AI …
-
一文搞懂卷积网络之四(空间注意力Non-local)




本文介绍CNN注意力机制开篇之作Non-local,其解决传统CNN长距离特征提取不足问题,通过学习特征图点间相关性实现全局联系。文中实现了Embedded Gaussian等三种模块结构,在Cifar10上与ResNet18基线对比实验,发现BottleNeck结构和模块位置对效果影响大,不同版本…
-
自然语言生成任务中的五种采样方法介绍和Pytorch代码实现
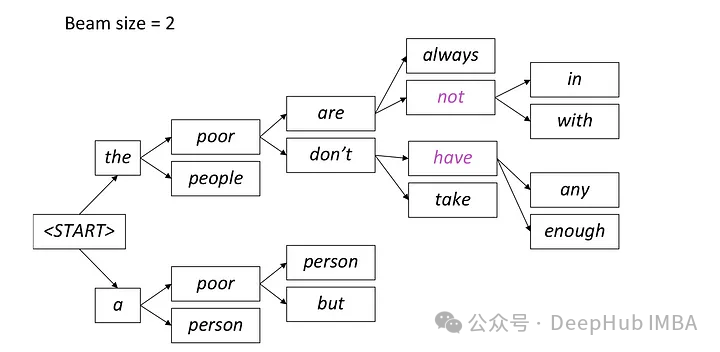



在自然语言生成任务中,采样方法是从生成模型中获得文本输出的一种技术。这篇文章将讨论5种常用方法,并使用pytorch进行实现。 1、Greedy Decoding 在贪婪解码中,生成模型根据输入序列逐个时间步地预测输出序列的单词。在每个时间步,模型会计算每个单词的条件概率分布,然后选择具有最高条件概…



